
Oracle’s new Pipelines feature in the Enterprise Performance Management Cloud (EPM) applications was made available with the June 2023 update. Pipelines allow for organizing individual jobs into one overall procedure directly within the EPM application, even across multiple EPM applications. You can learn more about this new feature in a recent Perficient blog Oracle EPM Cloud Feature Spotlight – Pipelines.
Below I’ll detail how Perficient used Pipelines to organize and automate the complete end-to-end data load process for one of our clients.
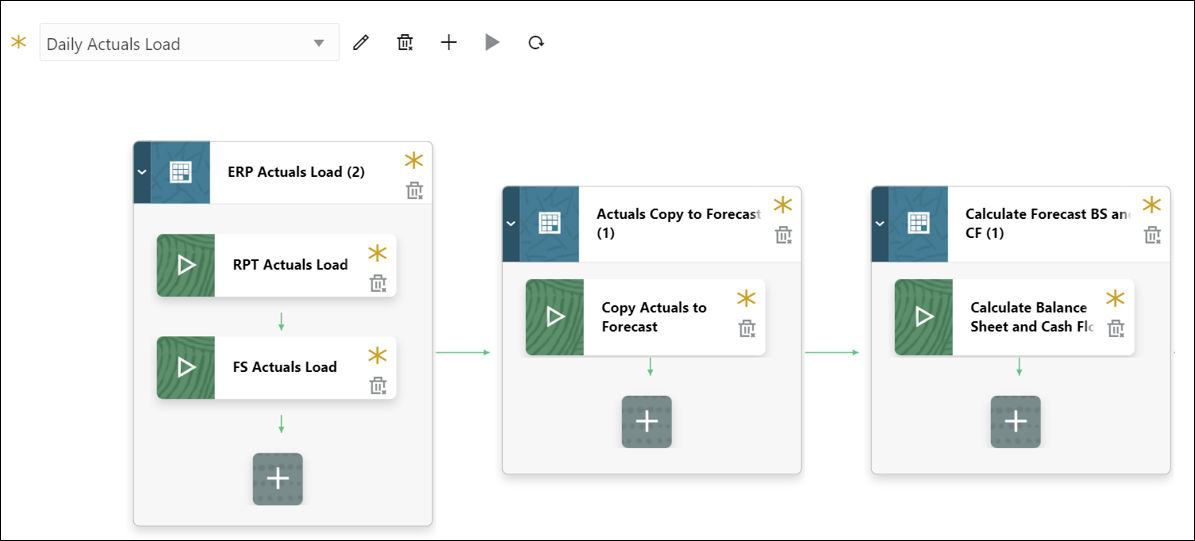
The daily load process of our client’s EPBCS application includes three steps:
- Actuals data load from the ERP Cloud into the Reporting and Financials cubes
- Copy of Actuals to Forecast scenario
- Balance Sheet and Cash Flow Calculation
Each of these steps in the load process needs to be run in a specific order and is contingent upon the success of the previous step. But since the client did not own a remote server to host EPM Automate scripts that would facilitate the sequential execution of these jobs, the Administrator was forced to perform each step manually.
With the new Pipelines feature, we could organize the three steps into one workflow or “Pipeline” within the application, thus simplifying the load process. Here’s how we did it!
Creating a Pipeline
Here are the steps that were used to create a Pipeline for the daily load process:
- From the Data Exchange page, Data Integration tab, click
 , and then select Pipeline.
, and then select Pipeline.
Note: Only Service Administrators can create and run a Pipeline.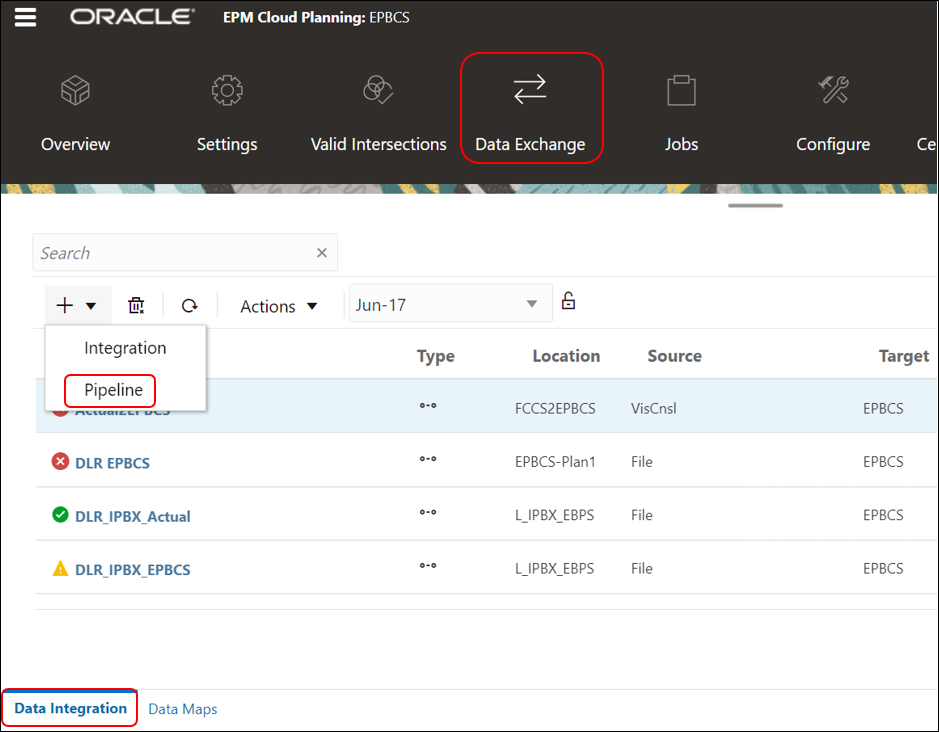
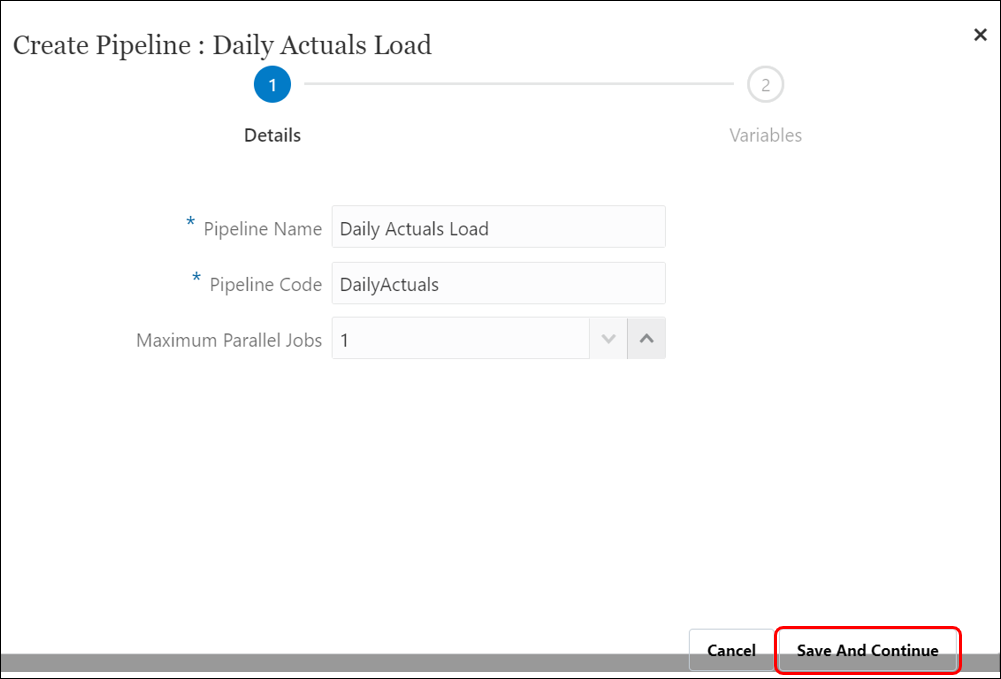
- From the Create Pipeline page, click ‘Details’, and in the ‘Pipeline Name’ enter the process name: “Daily Actuals Load”.
- In ‘Pipeline Code’, specify a Pipeline code: “DailyActuals” (Alphanumeric characters with minimum size 3 to maximum 30. No special characters or space is allowed).
- All jobs in the process run in a sequence so enter Maximum Parallel Jobs for each stage as 1.
- Click ‘Save and Continue‘.
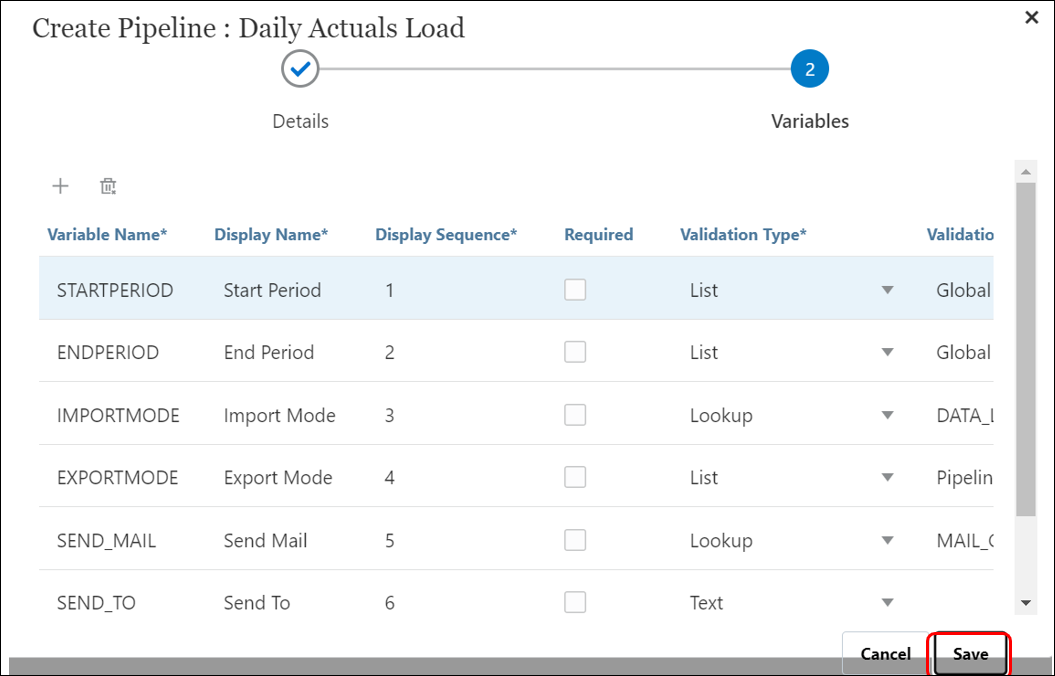
 On the Variables page, a set of out-of-box variables (global values) for the Pipeline is available from which you can set parameters at runtime (You can delete variables you do not need or create new variables. Variables can be pre-defined types like: “Period,” “Import Mode,” “Export Mode,” etc., or they can be custom values used as job parameters).
On the Variables page, a set of out-of-box variables (global values) for the Pipeline is available from which you can set parameters at runtime (You can delete variables you do not need or create new variables. Variables can be pre-defined types like: “Period,” “Import Mode,” “Export Mode,” etc., or they can be custom values used as job parameters).- Keep the below default runtime variables included with a Pipeline. Click ‘Save‘.
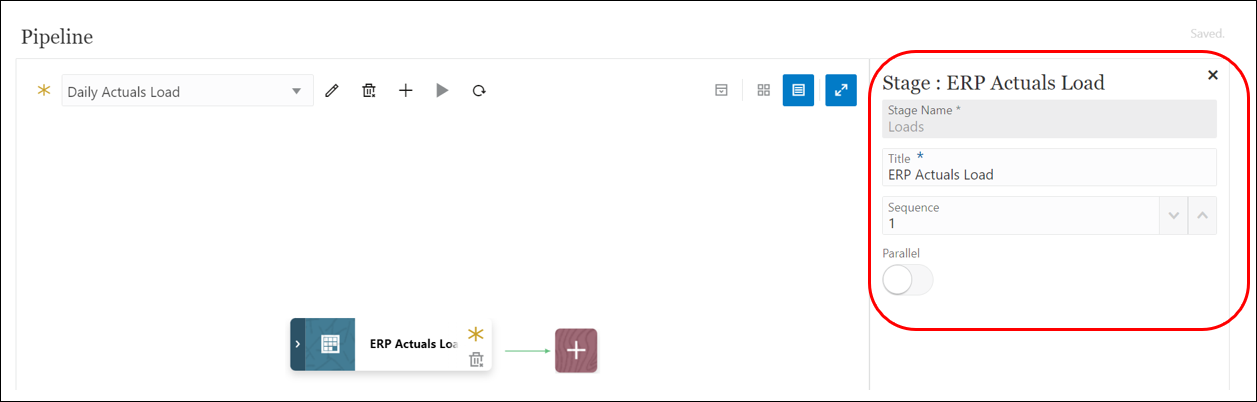
- On the Pipeline page, click
 to create a new stage card. It contains jobs that you want to run in the Pipeline at that stage and can include jobs of any type and for multiple target applications.
to create a new stage card. It contains jobs that you want to run in the Pipeline at that stage and can include jobs of any type and for multiple target applications. - In the Stage Editor, enter the following:
- Stage Name: Loads
- Title: ERP Actuals Load
- Sequence (A number to define the chronological order in which a stage is executed): 1
- Parallel: Off
- On the stage card, click ‘>‘ to add a new job to the stage.

- On the stage card, click
 (Create Job icon).
(Create Job icon). 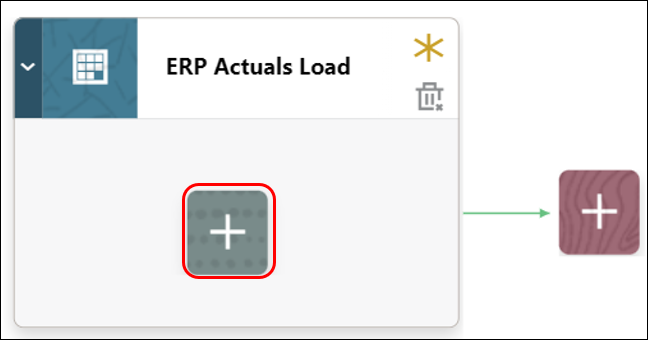
- A new job card is displayed on the stage card.

- In the Job Editor, from ‘Type‘ drop-down, select the ‘Integration‘ type job to add to the stage card.
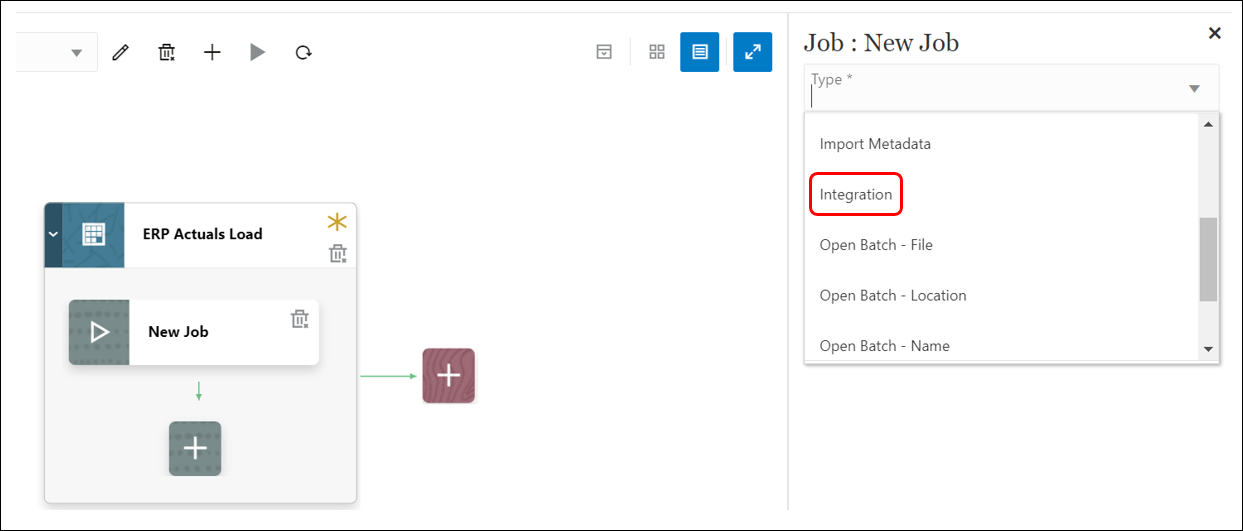
- From the ‘Connection‘ drop-down, select ‘Locali if the data integration is in the current environment.
- Enter the following details for the Job:
-
- Name (Select the Data Integration that loads from Cloud ERP to this EPBCS instance): Fusion US to EPBCS
- Title (Enter the title of job name to appear on the job card): RPT Actuals Load
- Sequence: 1
- Job Parameters: select any job parameters associated with the job like Import Mode, Export Mode, Start & End Period, Data load POV.

- Similarly, create a second job in this stage card to load data to the Financials cube.
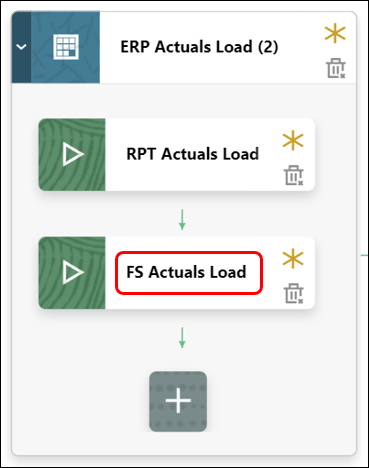
- Create the second stage to copy Actuals to the Forecast scenario by clicking on
 . Provide a stage sequence 2.
. Provide a stage sequence 2. 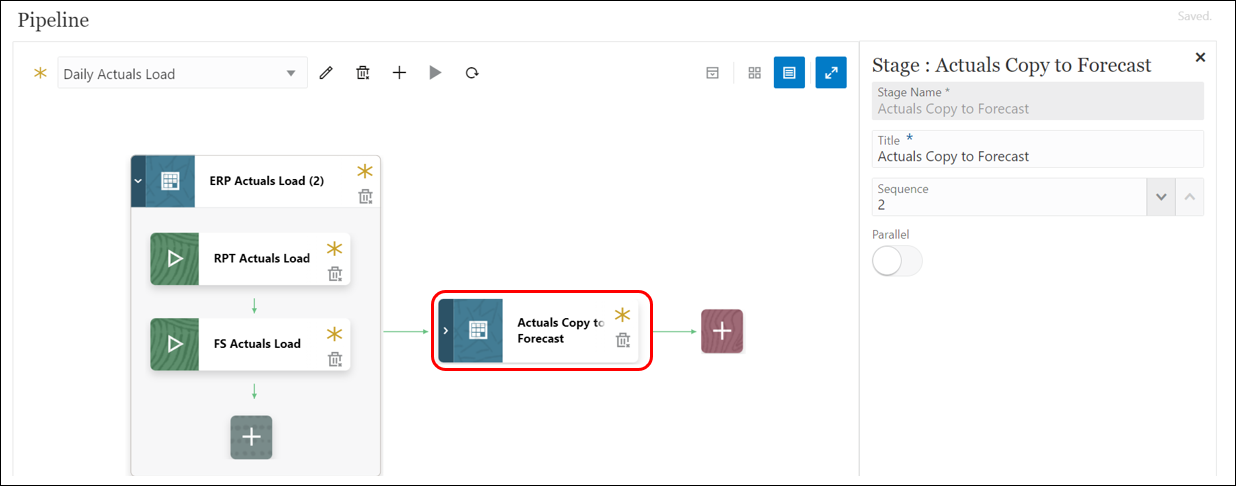
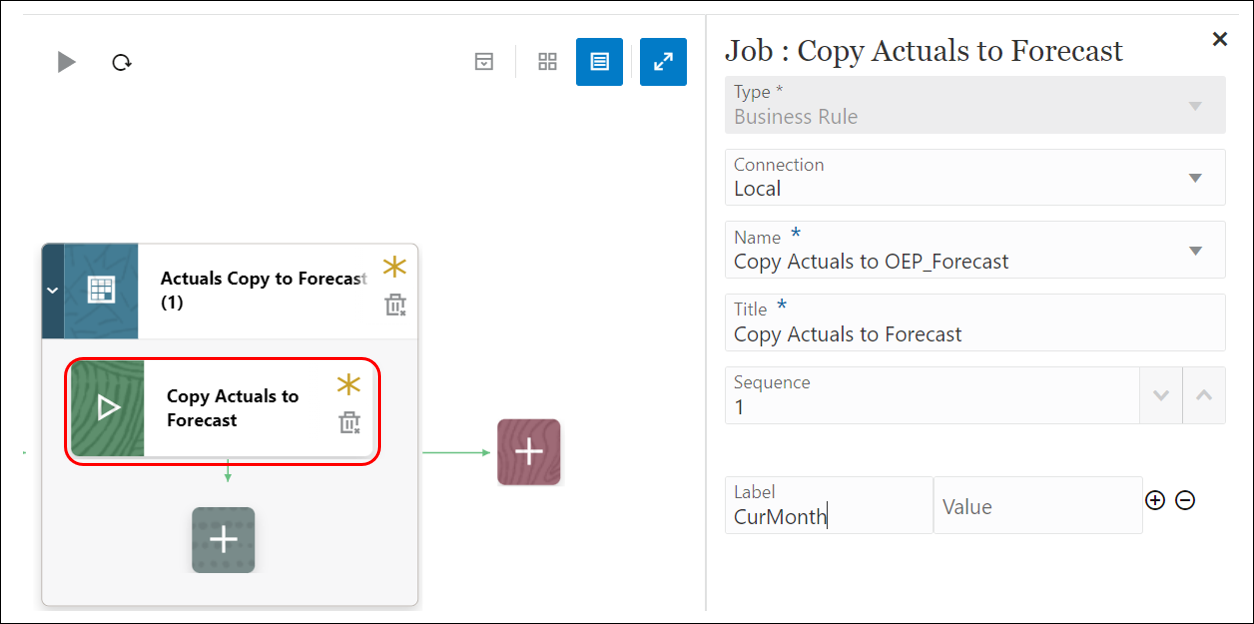
- Add a Business Rule type job and enter the following details:
-
- Connection: Local
- Name (Select the business rule to launch in this job): Copy Actuals to OEP_FS
- Title (Name of the job): Copy Actuals to Forecast
- Sequence: 1
- Label (runtime prompt as it is defined in the selected business rule): CurMonth
- Value (custom value type for a runtime prompt, specify the actual value): Not Applicable
- Create the third and final stage of the Pipeline to calculate Balance Sheet and Cashflow at the Forecast level and add a Business rule type Job to use the desired rule. Close the Pipeline.
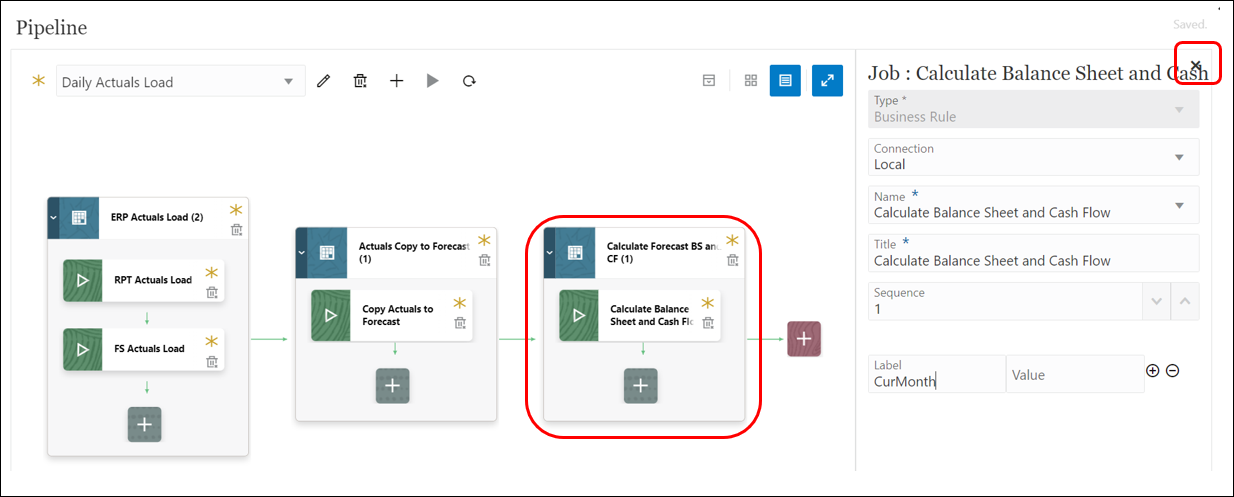
Note: The Pipeline is auto-saved while you are creating stages and jobs.
- The new Pipeline is added to the Data Integration homepage. Each Pipeline is identified with a
 under the ‘Type’ header.
under the ‘Type’ header.
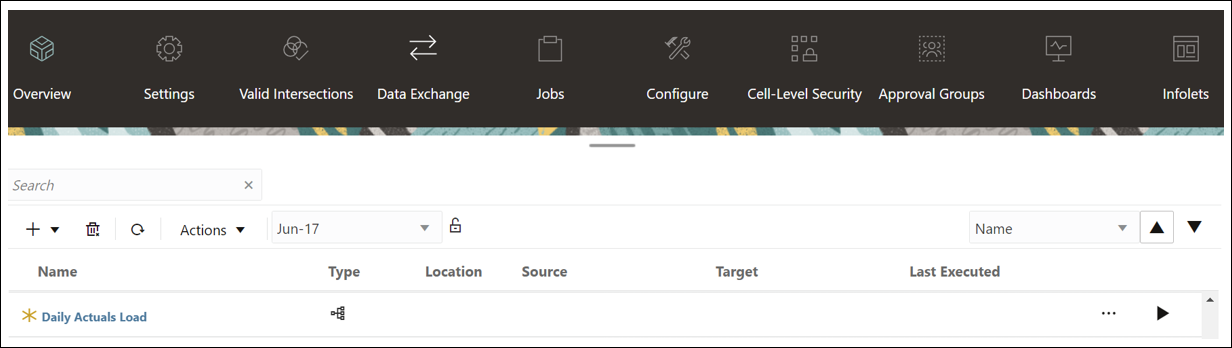
With a few simple steps, we organized the different types of jobs that needed to run for the data to load and process into one Pipeline. I will discuss how you can edit an existing pipeline, run it, and review the log files in my next blog!



As someone deeply invested in optimizing business processes, I found your article on Oracle Cloud EPM Pipelines to be an insightful and timely read. The way you’ve elucidated how these pipelines can redefine efficiency within organizations is quite commendable.
We have been leveraging Pipeline processes heavily since Oracle rolled out the functionality. Truly a game changer for us! My team of admins has been scheduling and running the processes, but wondering if there’s a way to allow users to run specific processes that we’ve created for their individual business process? Is there a way to assign security to a specific pipeline process?
Hi Scott! Thank you for reading the blog and thanks for your question! I am very glad to hear your team is taking advantage of the Pipelines feature in EPM. To answer your question, in the new November update from Oracle, you can now create a ‘Pipeline’ type-task in the Task Manager. If your application uses Task manager, you should be able to create a Task that is of Pipelines task-type and then assign the task to individuals responsible for running the process associated with that Pipeline.