
Introduction
In part I of our Kubernetes multi-cluster management series, we’ve talked about the basics of GitOps and explained why you should really consider GitOps as a central tenet of your Kubernetes management strategy. In part II, we looked at a reference implementation of GitOps using ArgoCD, and how to organize your GitOps repositories for security and release management.
In this final installment of our Kubernetes multi-cluster management series, we’re taking our approach to the next level and look at enterprise scale, operational efficiency, compliance for regulated industries, and so much more. To help alleviate some of the shortcomings of the GitOps-only approach, we’re going to introduce a new tool which integrates really nicely with ArgoCD: RedHat Advanced Cluster Management (ACM) and the upstream community project Open Cluster Management.
I should mention right off-the-bat that ACM is not limited to RedHat Openshift clusters. If your hub cluster is Openshift, then you can use ACM and import your other clusters (AKS, EKS, etc) into it, but you can also use other clusters as hubs with Open Cluster Management.
Motivation
When I first heard about Advanced Cluster Management, I thought, why do I need this? After all, our GitOps approach discussed in Part II works and scales really well, up to thousands of clusters, but realized there are a few shortcomings when you’re deploying in the enterprise:
Visibility: because we use a pull model, where each cluster is independent of the others and manages its own ArgoCD instance, identifying what is actually deployed on a whole fleet of cluster is not straight forward. You can only look at one ArgoCD instance at a time.
Compliance: while it’s a good idea to have standard configuration for all your clusters in your organization, it’s not always possible, in practice, to force every team to be in sync all at the same time. You can certainly configure GitOps to sync manually let individual teams pick and choose what/when they want deployed in their cluster, but how do you keep track of gaps at a global level?
Management: GitOps only deals with configuration, not cluster lifecycle, and by that I mean provisioning, starting, pausing clusters. Depending on the organization, we’ve been relying on the cloud provider console or CLIs, and/or external automation tools like Terraform to do this. But that’s a lot more complicated in hybrid environments.
Use Case
Let’s focus on a specific use case and see how to address the above concerns by introducing advanced cluster management. The organization is a large retailer with thousands of locations all over the US. Each individual store runs an application which collects Bluetooth data and computes the information locally to customize the customer’s experience. The organization also run applications in the cloud like their website, pipelines to aggregate collected store data, etc. all on Kubernetes.
Requirements
- All the stores run the same version of the application
- Application updates need to happen at scale over-the-air
- All the clusters (on location and in the cloud) must adhere to specific standards like PCI
- Development teams need to be able to simulate store clusters in the cloud
- The infrastructure team needs to quickly provision new clusters
- The compliance and security teams regularly produce reports to show auditors
Solution
GitOps-only
1-4 requirements can be mostly addressed with our GitOps-only approach. This is the overall architecture following what we presented in part II
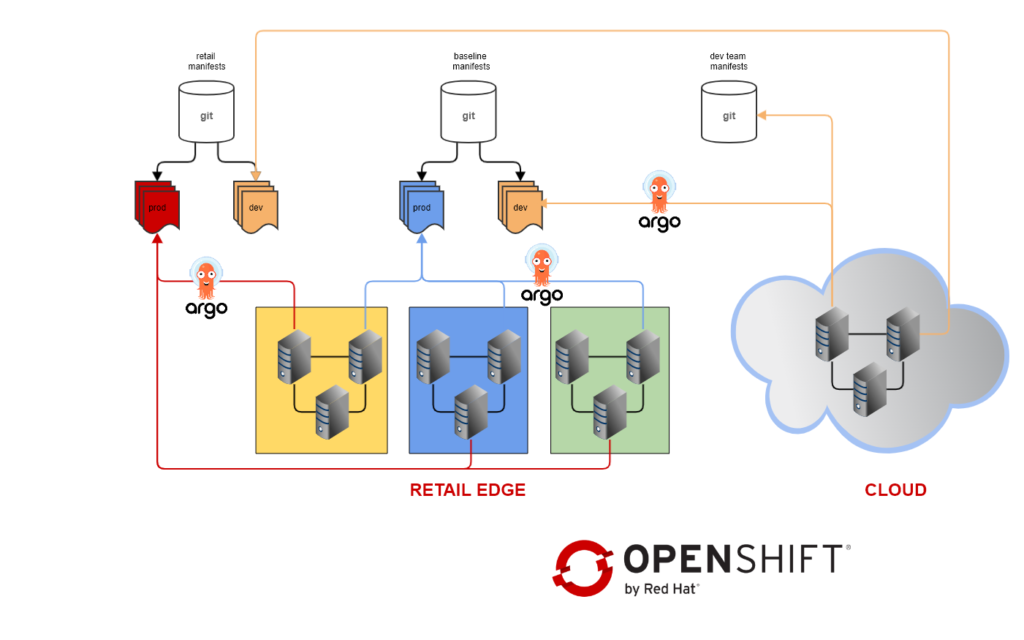
- Baseline configuration for all our clusters is in a shared repository managed by the infrastructure team
- The baseline contains dependencies and tools like operators, monitoring and logging manifests, etc. And some of the PCI-related configuration.
- Various teams can contribute to the baseline repository by submitting pull-requests
- Store clusters are connected to a second repository which contains the BT application manifests
- Stores clusters can be simulated in the cloud by connecting them to the same repository
- Dev teams have dedicated repositories which they can use to deploy applications in the cloud clusters
- For simplicity sake, we only have two environments: dev and prod. Each environment is connected to the repository branch of the same name
- New releases are deployed in the dev branches, and promoted to production with Git merge
So GitOps-only goes a long way here. From a pure operational perspective, we covered most of the requirements and the devops flow is pretty straight forward:
- Dev teams can simulate a store cluster in the cloud
- They can deploy and test changes by committing to the dev branches of the repos
- When they’re ready to go, changes are merge to prod and automatically deployed to all the edge clusters
- All the clusters share the same baseline configuration with the necessary PCI requirements
ACM and OCM overview
Red Hat Advanced Cluster Management and the upstream community project Open Cluster Management is an orchestration platform for Kubernetes clusters. I’m not going to go into too many details in this article. Feel free to check out the documentation on the OCM website for a more complete explanation on architecture and concepts.
For the moment all you need to know is:
- ACM uses a hub-and-spoke model, where the actual ACM platform is installed on the hub
- The hub is where global configuration is stored
- Agents run on the spokes to pull configuration from the hub
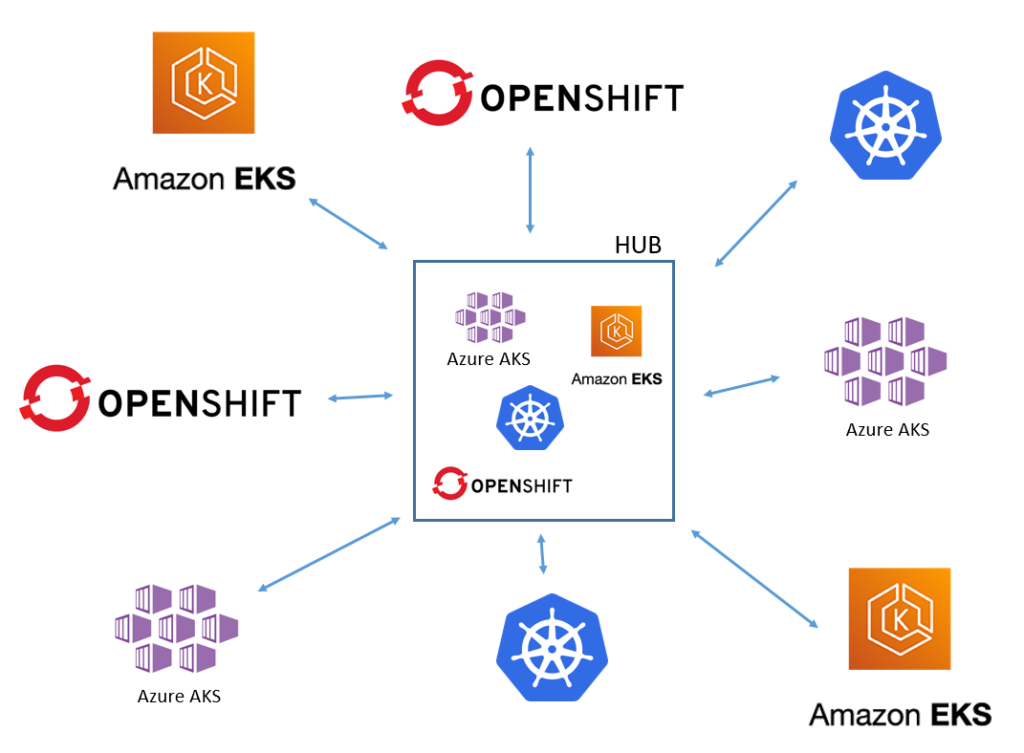
- ACM provides 4 main features:
- Clusters lifecycle management (create, start/stop/pause, group, destroy clusters)
- Workload management to place application onto spokes using cluster groups
- Governance to manage compliance of the clusters through policies
- Monitoring data aggregation
Both tools can be installed in a few minutes through the operators’ marketplace, with ACM being more integrated with Openshift specifically and Red Hat enterprise support.
Cluster Provisioning

GitOps cannot be used to provision clusters so you need to rely on something else to create the cluster infrastructure and bootstrap the cluster with GitOps. You have 2 options:
- If you’re deploying non-Openshift clusters, you will need to use some kind of automation tool like Ansible or Terraform or provider specific services like Cloudformation or ARM. I recommend wrapping those inside a CI/CD pipeline and manage the infrastructure state in Git so you can easily add a cluster by committing a change to your central infrastructure repo.
- If you’re deploying Opensihft clusters, then you can leverage ACM directly, which integrates with the main cloud providers and even virtualized datacenters. A cool feature of ACM is cluster pools, which allows you to pre-configure Openshift clusters and assign them to teams with one click. More on that later…
Regardless of the approach, you need to register the cluster with the Hub. This is a very straight forward operation, which can be included as a step in your CI/CD pipeline, and is managed by ACM automatically if you’re using it to create the clusters.
Cluster bootstrapping
Once the blank cluster is available, we need to start installing dependencies, basic tooling, security, etc. Normally we would add a step in our provisioning CI/CD but this is where Advanced Cluster Management comes in handy. You don’t need an additional automation tool to handle it, you can create policies in ACM, which are just standard Kubernetes manifests, to automatically install ArgoCD on newly registered clusters and create an ArgoCD application which bootstraps the clusters using the baseline repository.

The 3 bootstrapping policies installed on our hub
ACM governance is how we address point 5 and 6 in the requirements. You can pick existing policies and/or create new ones to apply specific configuration to your clusters, which are tied to a regulatory requirement like PCI. Security and compliance teams, as well as auditors can quickly identify gaps through the ACM interface.
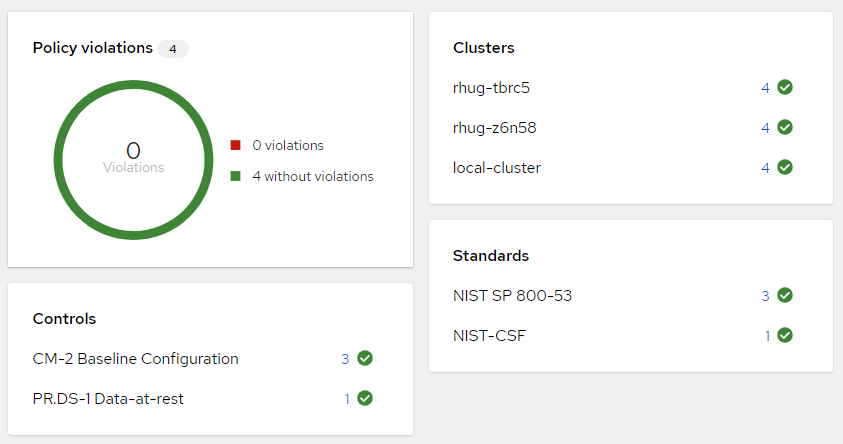
ACM Governance Dashboard
You can choose whether you want policies to be enforced or just monitored. This gives your teams flexibility to decide when they’re ready to upgrade their cluster configuration to get into compliance.
In our case, our policy enforces the installation and initialization of GitOps on every single cluster, as a requirement for disaster recovery. This approach allows us to quickly provision new edge clusters and keep them all in sync:
- Provision the new cluster hardware
- Install Kubernetes
- Register with the hub
- As soon as the cluster is online, it bootstraps itself with GitOps
- Each cluster then keeps itself up-to-date by syncing with the edge repo prod branch
Workload Management
You have 2 ways to manage workloads with Advanced Cluster Management:
Subscriptions: this is essentially ACM-native GitOps if you’re not using ArgoCD. You create channels to monitor Git repositories and use cluster sets to target groups of clusters to deploy the applications into. The main difference with GitOps is the ability to deploy to multiple clusters at the same time
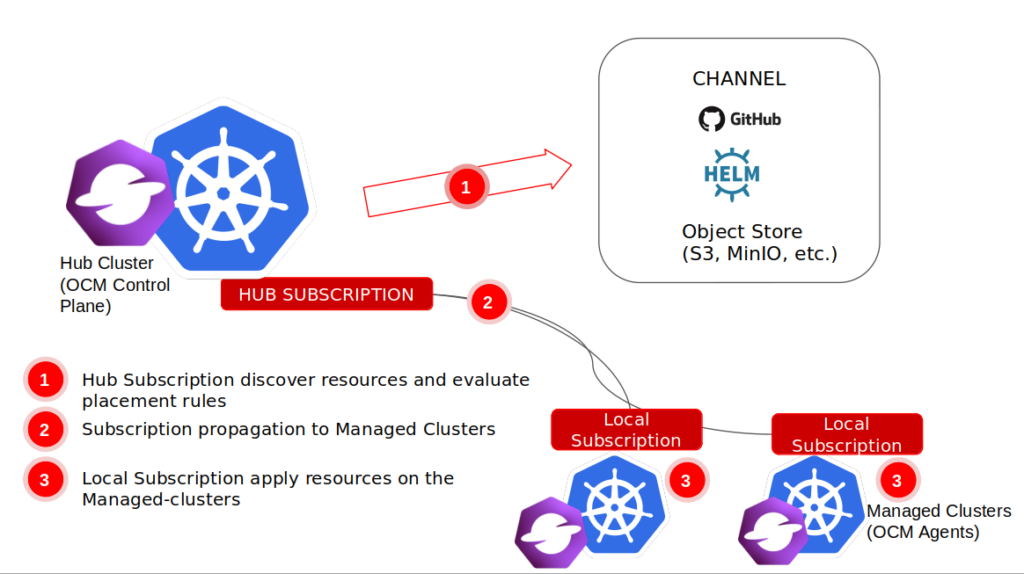
ArgoCD ApplicationSets: this is a fairly new addition to ArgoCD which addresses the multi-cluster deployment scenario. You can use ApplicationSets without ACM, but ACM auto-configures the sets to leverage your existing cluster groups, so you don’t have to maintain that in two places
ApplicationSets are the recommended way but Subscriptions have some cool features which are not available with ArgoCD like scheduled deployments.
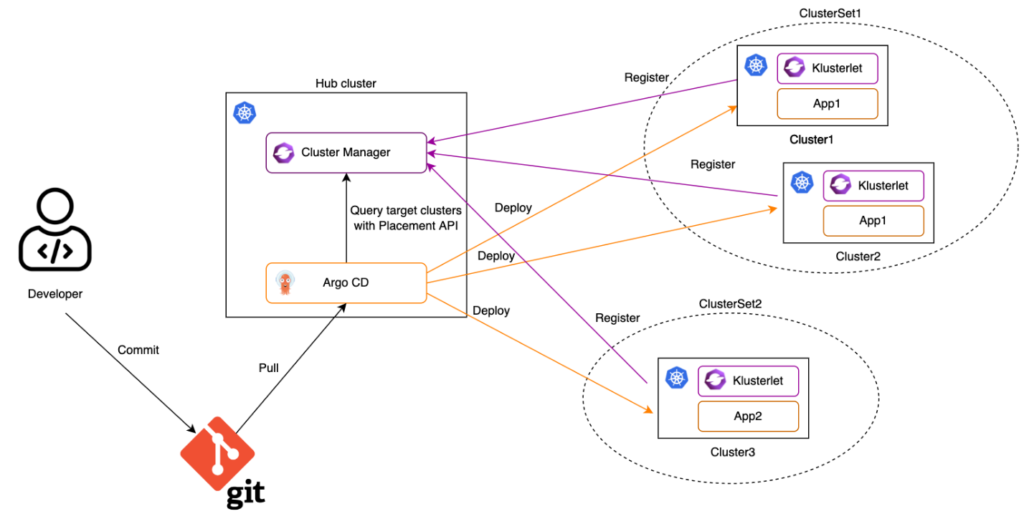
I have one main concern with ApplicationSets, and it’s the fact that it relies on a push model. ApplicationSets generates one ArgoCD Application per target cluster on the hub and syncs the changes from the one ArgoCD server on the hub. When you’re talking 100s or 1000s of clusters it will put a lot of load on the hub.
Another potential issue is ingress networking for the retail locations to allow the hub to push things out to the spoke. It’s usually easier to configure a NAT on the local network, going out to the internet to pull the manifests from Git.
So… in this case, we’re just not going to use any of the ACM provided method and stick to our approach where each cluster manages its own ArgoCD server 😀
But… we can still use ACM for visibility. ACM application page can show you all the workloads deployed on all your clusters in one place, show you deployment status, basic information, and makes it very easy to drill down into logs for example. And navigate to each individual cluster’s ArgoCD UI.

Application dashboard
Note on cluster pools
I want to go back to cluster pools for a little bit because it’s a really neat feature if you are using Openshift.
This is an example of a cluster pool on AWS:

AWS Cluster Pool
This cluster pool is configured to always have one cluster ready to be assigned. Notice the “claim cluster” link on the right. As soon as a team claims this cluster, the pool will automatically provision a new one, if so configured.
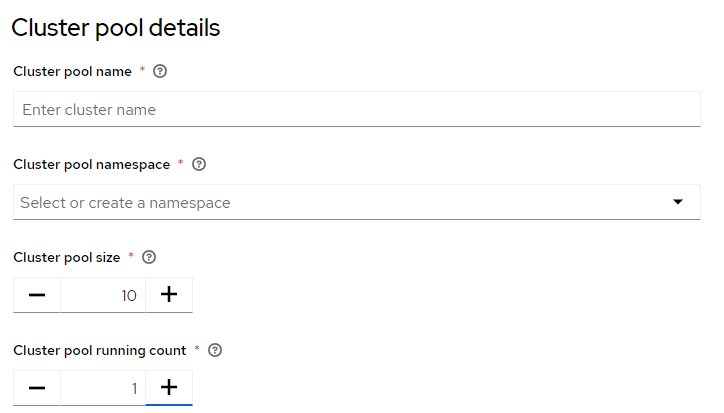
Cluster pool configuration
In this case the pool is configured with 10 clusters, with one warm cluster (not bootstrapped) available to be claimed immediately at all time.
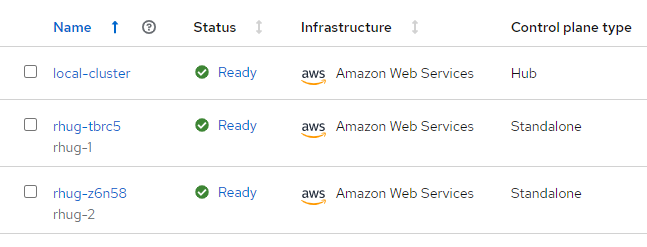
Pool dashboard
Here we see 2 clusters provisioned through the pool, which we previously claimed. Notice the auto-generated cluster name indicating the origin of the cluster as rhug-.
Note that clusters deployed on AWS that way are not managed by AWS and Red Hat, unlike AWS ROSA clusters, although they are provisioned using the same installation method. Something to keep in mind. If unmanaged clusters are a deal breaker, you can always provision a cluster on ROSA and register it with the hub explicitly.
There are two great use case for cluster pools & cluster lifecycle management:
- Quickly provisioning turnkey new clusters for development teams. If you maintain your shared config repositories correctly, you can build and bootstrap brand new, fully compliant and ready-to-use clusters in a matter of minutes. You can terminate a cluster at the end of the work day and re-create it identical the next morning to save on cost, reset clusters to the base configuration if you messed it up, etc
- Active-passive disaster recovery across regions or even cloud providers. If you want to save on your redundant environment infrastructure cost, and you don’t have Stateful applications (no storage), create a second cluster pool in the other region/cloud and hibernate your clusters. When you need to failover, resume the clusters in the standby region, and they will very quickly start and get up-to-date with the last-know good config.
Conclusion
There is so much to discuss on the topics of GitOps and ACM, this is barely scratching the surface, but hopefully it gave you enough information to get started on the right foot and to get excited about the possibilities. Even if you only have one cluster, GitOps is very easy to setup, and you’ll rip the benefits on day 1. I strongly recommend you check out part II of this series for a reference. As a reminder, I also shared a CloudFormation template which deploys an implementation of that architecture using AWS ROSA (minus ACM as of today). When you’re ready to scale, also consider Advanced Cluster Management for the ultimate multi-cluster experience. I haven’t had a chance to include it in my reference implementation yet, but check back later.
Stay tuned for my next GitOps articles on ArgoCD security and custom operators…