Introduction
In Part I of our multi-cluster management series, we’ve introduced GitOps and gone over some of the reasons why you should adopt GitOps for the management of Kubernetes clusters. GitOps is always the #1 thing we set up when starting an engagement and we’ve spent a lot of time perfecting our best practices. Today we’re diving deep inside our reference architecture using Openshift and ArgoCD. Note that the same approach can be used for other Kubernetes distributions on-prem or in the cloud, and FluxCD.
TLDR: If you just want to see this reference implementation in action, feel free to try our Red Hat Openshift on AWS accelerator in your own environment. Simply click the button at the top to launch the Cloudformation template.
Check out part 3 on Advanced Cluster Management
Our GitOps Architecture
Now that you’re familiar with all the reasons why you should use GitOps, let’s talk about how to get started on the right track. The way of organizing GitOps repository I’m going to describe is our baseline for all our greenfield Kubernetes engagements. I’ll explain why we made some of these decisions but as always this might not apply to your particular use case.
High-level repository layout
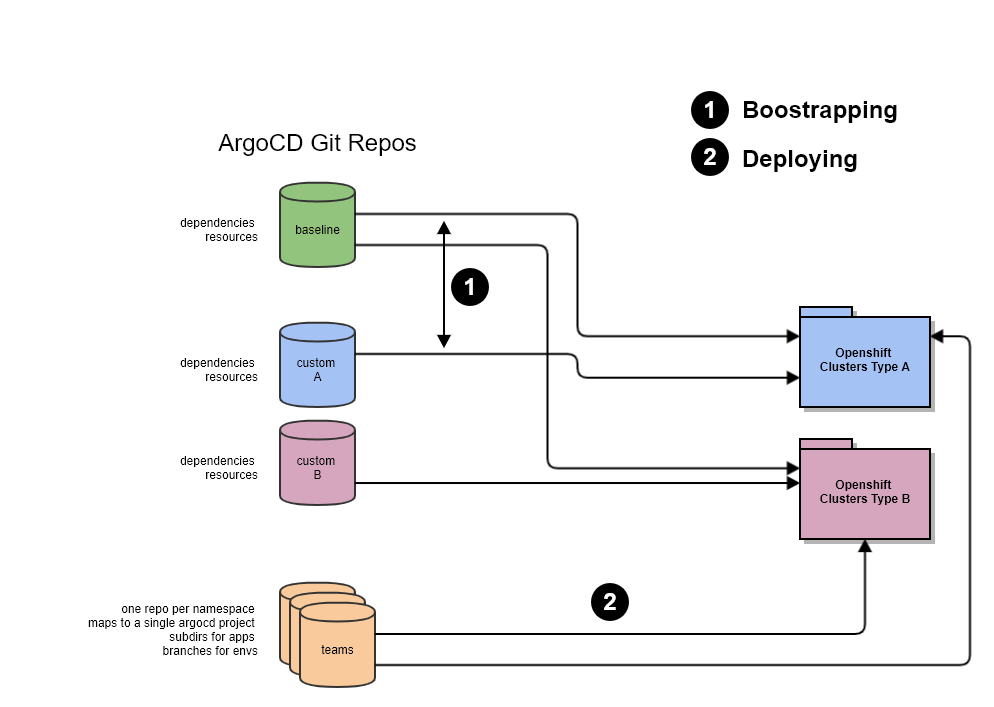
We split our cluster’s configuration into 3 or more repositories:
- baseline: contains the manifests common to all the clusters. That repo is split into two directories, each mapping to a separate ArgoCD App:
- dependencies: contains basically operator subscriptions, default namespaces, some rbac, service accounts, etc
- resources: contains the manifests for the custom resources (CR) that actually use the operators, and other base manifests
- custom A, B, …: same directory structure as baseline but are used for specific clusters or families of clusters (for example clusters for ML, clusters for microservices, clusters for particular teams, etc)
- teams: these repositories are the only ones to app dev teams with write access. This is the place where workload manifests are managed. Since ArgoCD can process repositories recursively, we like to create subfolders to group application manifests which go together (typically a deployment, service, route and autoscaler). Each team repository is tied to single ArgoCD App which maps to a single namespace in Kubernetes.
This is what this looks like in ArgoCD on any given cluster:
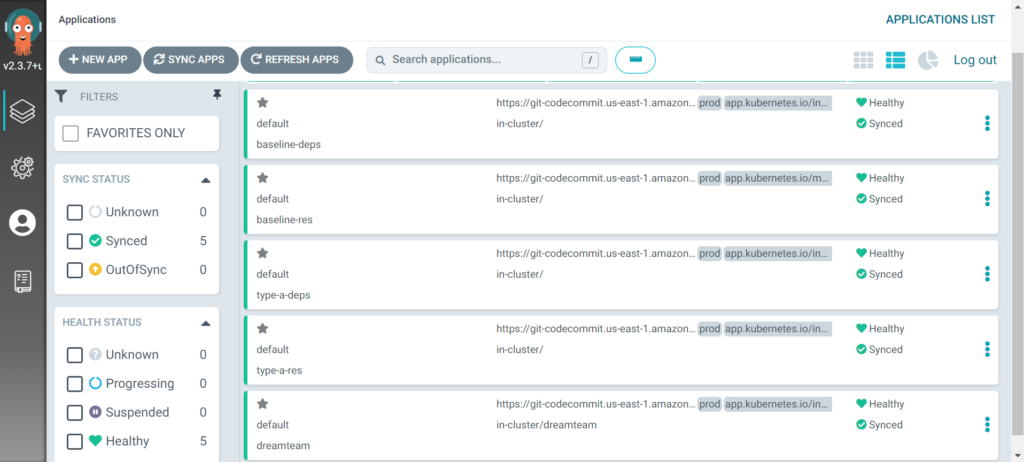
Remember that an ArgoCD Application (ArgoCD App) does not necessarily map to an actual “application” as-in a single program. ArgoCD Application is an ArgoCD concept that represents a connection to a repository, which contains multiple manifests for one or more programs, or just pure configuration resources. This is a common misconception and application could be easily renamed configset or something like that, but the point is an ArgoCD Application is just a collection of arbitrarily organized manifests.
Here we see the top two ArgoCD applications baseline-deps and baseline-resources connected to the shared baseline repo dependencies and resources directories. The next two are the connected to the shared type A cluster repo dependencies and resources directories. The last one is owned by the “dreamteam” team connected to their own repo. Notice the last application targets the dreamteam namespace while the others don’t specify any.
Example 1:
Baseline repository contains the manifests responsible for the installation of the cluster logging operator but a particular cluster needs to forward the logs to a 3rd party. In that case the custom repository contains the LogForwarding CR for that particular cluster.
Example 2:
Custom repository “kubernetes-data-pipeline” contains the manifests to configure clusters that run data pipeline applications. These clusters require Kafka, Service Mesh, and KNative, so this is the repository where you will place your manifests to install the required operators, and configure a Kafka cluster, the service mesh control plane, etc. Then each team can configure their own topics and service mesh virtual services, etc from their own repo.
App of Apps Design
We almost always use the “App of App” technique to build our clusters configuration, where we only create one ArgoCD application initially: the type-a-baseline. The type-a-baseline repository contains 2 ArgoCD applications: type-a-res and baseline-deps. The hierarchy is as follows:
- type-a-deps (kind: argoproj.io/v1alpha1 Application, type-a/deps repo)
- type-a-res (kind: argoproj.io/v1alpha1 Application, type-a/res repo)
- baseline-deps (kind: argoproj.io/v1alpha1 Application, baseline/deps repo)
- baseline-res (kind: argoproj.io/v1alpha1 Application, bsaeline/res repo)
You can create how many layers you want, each one referencing the layer below. For example, if you wanted to bootstrap a unique cluster, that’s built on top of type-a config, you would create a single ArgoCD application called my-cluster-deps, connected to a my-cluster Gitops repo, containing a manifest for the type-a-deps application, etc:
- my-cluster-deps
- my-cluster-res
- type-a-deps
- type-a-res
- baseline-deps
- baseline-res
- my-team-config
- app-1
- app-2
- etc
The main point of this is you can build increasingly complex cluster configuration by assembling and stacking up ArgoCD Apps, but you only ever need one single ArgoCD App to bootstrap any cluster. Think of it as a maven library which references other maven libraries, and they themselves reference other libraries, building a complex dependency tree.
ArgoCD unfortunately only shows a single layer of dependencies, so you cannot visualize the hierarchy in the UI.
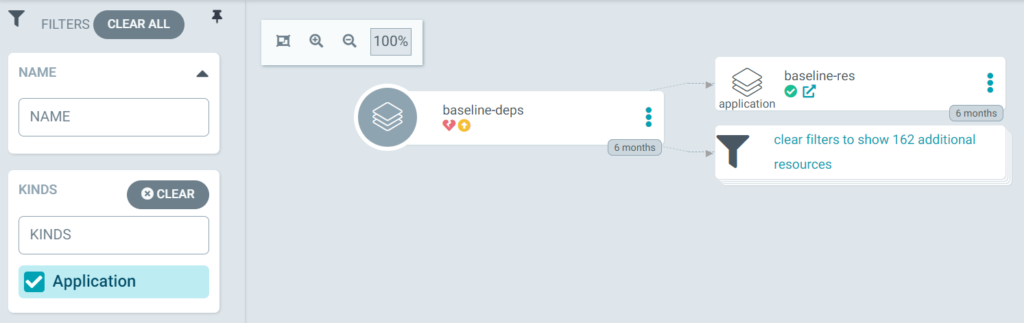
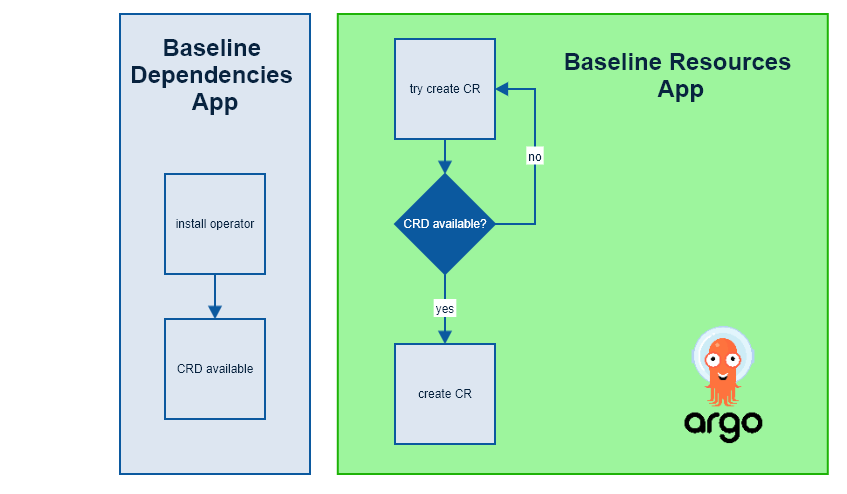
Note: why do we separate dependencies and resources? In Openshift, we leverage operators to install extensions such as Prometheus, Elasticsearch, etc. Operators register new object types with the Kubernetes API called CRD (Custom Resource Definition). Once a CRD is declared, you can create instances of these objects (like a Prometheus cluster for example) using a CR (Custom Resource) which is a manifest with a kind: NewResource.
ArgoCD App will not be able to deploy CRs and sync will fail when the corresponding CRD is missing (i.e. the operator hasn’t been installed yet). Even if you have the operator subscription and the CR in the same ArgoCD App, you will run into a race condition. To work around that problem, we had split the baseline into two directories and map them to 2 different ArgoCD Apps. The 2 apps will try to sync initially, but the second one will immediately fail as the first one is installing the operator. No worries though, ArgoCD will keep retrying and eventually sync once the operator is finally installed.
Basic GitOps Security
In theory, you could very well use a single repository that contains all the manifests for a cluster and use pull requests to review and control what actually gets deployed. We prefer separating our manifests in different repos to align with Kubernetes user personas and facilitate reusability instead.
Admins: have write access to baseline and custom repositories which contains cluster-wide configuration manifests such as operators, security aspects and shared resources like monitoring and logging. These are resources which, when modified, will impact all the tenants on the cluster, so special care needs to be taken during the PR process.
Dev Teams: have write access to team’s repos. These repos are tied to specific namespaces in Kubernetes and changes to manifests in these namespaces only affect that particular team.
The basic principle here is that only admins are allowed to create ArgoCD Application instances so you can use Git permissions as a high-level access control mechanism. Dev teams can only deploy manifests in the Git repo that is assigned to them, which is tied to a specific namespace on the cluster. They cannot create resources in global namespaces because they don’t have write access to those repos.
More on GitOps security and granular ArgoCD ACLs coming up in a separate post.
Provisioning Clusters
Using this shared repositories model, provisioning new clusters is a simple two-steps process:
- Create a new blank cluster using the appropriate installer
- Install ArgoCD
- Create an ArgoCD Application which points to the top-level repo (see above)
- The cluster will bootstrap itself from Git
You can repeat that process as many times as you want, there is no technical limitation to how many clusters can sync from the same repo. Existing clusters using the shared repositories will keep themselves up-to-date.
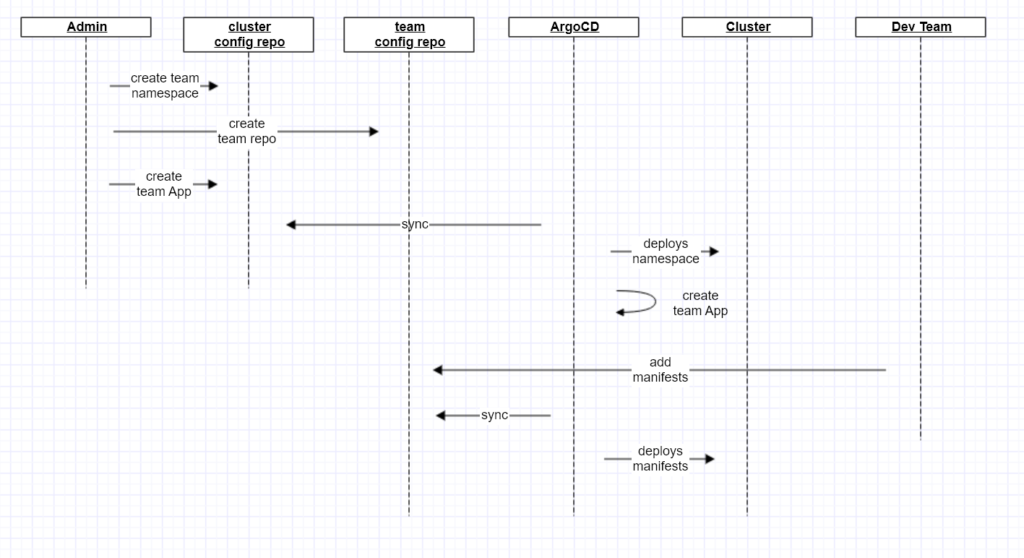
Once bootstrapped, an admin can onboard a development team by:
- Creating a dedicated team repo
- Creating a namespace on the cluster for that team
- Creating an ArgoCD App which binds the team repo to the new namespace
And the new team can start deploying workloads by adding application manifests to their new repo.
Releasing Applications
Classic Deployment Pattern
This is a common workflow to deploy artifacts to classic application servers, using CI/CD:
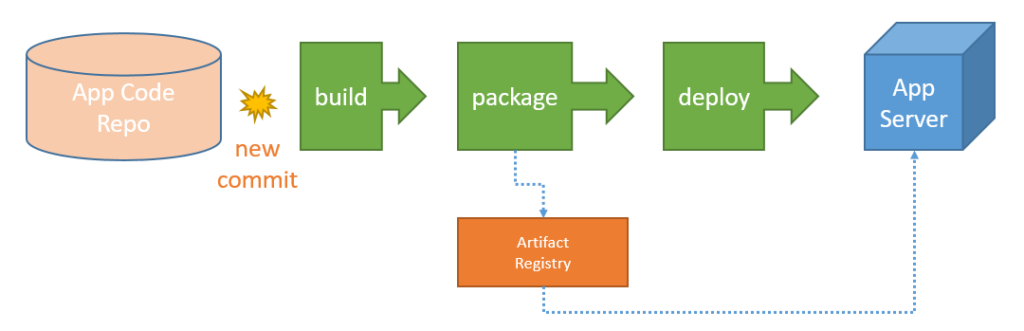
- Somebody commits some changes
- A new application artifact is built
- (Sometimes) the artifact is pushed to an artifact repository
- The artifact is deployed to the application servers (either copied directly or indirectly)
If you’re using IaC, like Chef or Ansible or similar, you might update your web server by running some kind of recipe, that’s good practice to deploy at scale and recovering servers.
The GitOps Way
We’ve shown how each application team gets its own Git repository and that Git repository is tied to a specific namespace in the Kubernetes cluster. So for a team to deploy a new application, all they need to do is commit the application manifests (usually deployment, service, route, autoscaler) and ArgoCD will sync the state automatically. Of course before that happens, a container image has to be created, and ArgoCD can’t do that for you so you need a CI pipeline for that purpose.
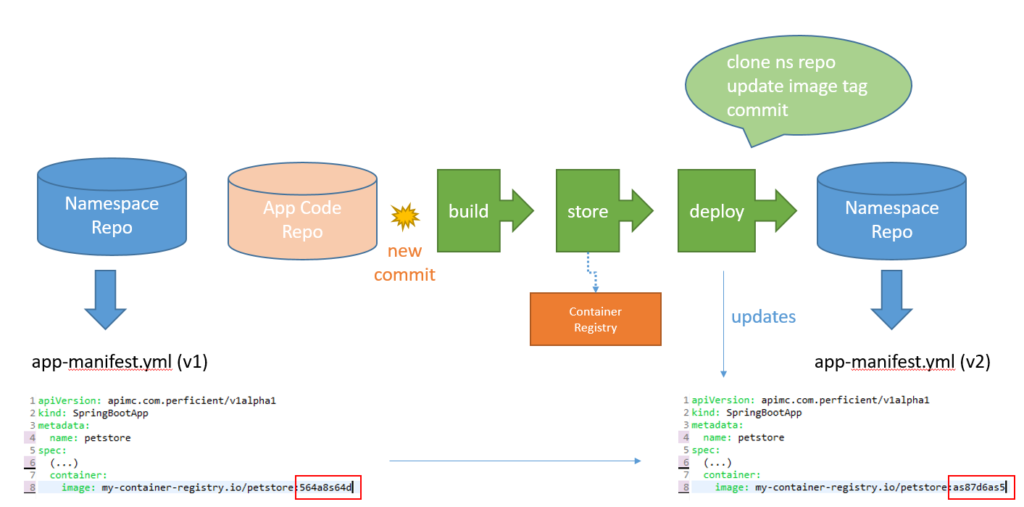
The main difference with a classic CI/CD pipeline is that we always push the artifact (the container image) to the container registry, and the end of the flow is an update to the deployment manifest containing the new image tag. Notice that the Kubernetes cluster is not in the CI/CD process at all. That because the actual CD is handle by the GitOps tool.
Managing Multiple Environments
Branching Strategy
When you first start with Kubernetes, you will likely have a single Kubernetes cluster for dev. Soon though you will need to promote your applications to QA for testing, then staging and prod.
We tend to treat our lower environment clusters as production, because a broken cluster might prevent dev and QA teams from doing their job and cause delays and additional costs. Typically the only differences between our environments are related to scale and security. I’m not talking about an experimental cluster that you use to try different operators and configurations and is essentially a throw-away cluster.
So with that in mind, we like to use long-lived branches for environments. This makes it really easy to moves things around by just merging branches. It also helps with permissions as people allowed to commit code to dev can be blocked from deploying changing to production.
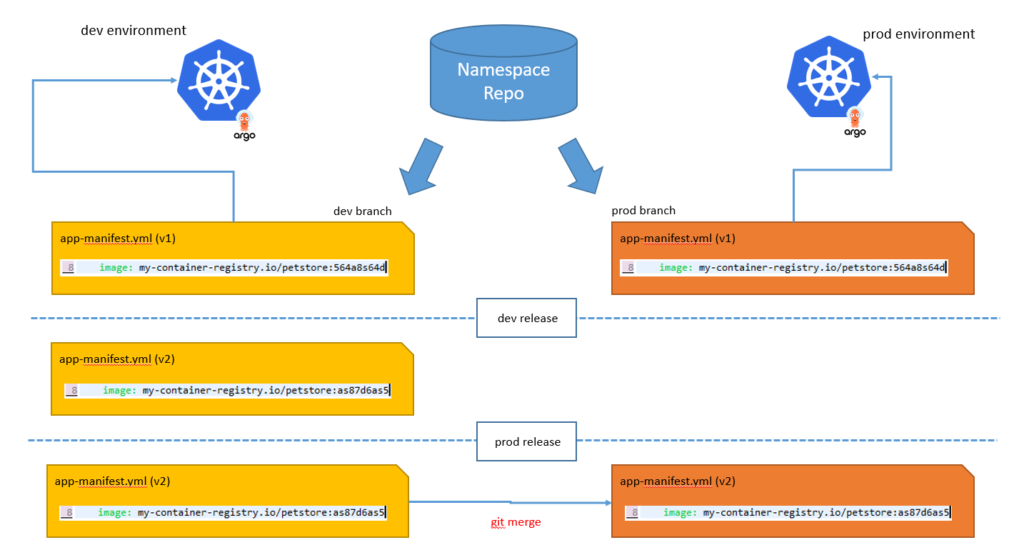
application version promotion process
What about sub-directories for environments?
Another approach that I commonly see out there to manage multiple environments is to use a single branch repository but one sub-directory per environment. In some cases teams use Kustomize to create a shared base and create overlays to customize each environment.
This approach has a few disadvantages:
- More prone to error. You might inadvertently make a change in a higher environment and allow it to go through if the PR is not thorough. It’s harder to tell what environment a file change impacts if you have a lot of changes in the commit. Using branches, you can immediately tell that the target for the change is the production branch and pay extra attention. You can even configure Git to require more approvals when targeting specific branches
- There is no way to manage write permissions for different environments, it’s all or nothing since a person with write access to the repository will have write access to all the sub-directories
- It’s not as straight forward to compare differences between environments. You can pull the repository locally and run a diff, but with branches, you can use the Git UI to compare entire branches
- It’s not as straight forward to look at change history for a given environment. Your commit logs will show all changes across all environments. You would need to filter by sub-directory to only see a particular environment log
- The process to promote things between environments is manual. Adding an application for example, requires to copy the manifests in the right sub-directory. It’s not always obvious which files are affected, you might forget to copy one or more files, or copy the wrong file. Branch merging will immediately highlight additions, deletions, etc
A case where branching would not be a good option is when environments are significantly different and too many conflicts would arise when trying to merge changes. For example, regional clusters with specific networking requirements, or edge clusters:
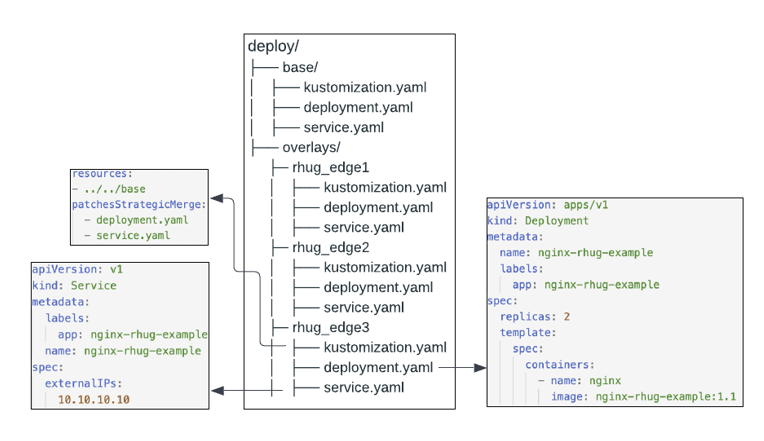
Example of a multi-site gitops repo structure with Kustomize
(Thanks to Ryan Etten at Red Hat)
Limitations
As with any shared resources, the main problems are:
- Any change to a manifest in the baseline repository will be propagated to all clusters connected to it. It means an untested change could negatively impact everybody
- Everyone is going to receive the changes whether they want it or not. It could be desired to make sure everybody is running the latest versions of operators, or follow basic security practices, but it could also be inconvenient if there is a breaking change
- A team might want to customize something that’s set in the baseline, which is incompatible with other teams
- A team might request a change that requires everyone to be in agreement and has to be reviewed by a lot of people, which might cause delays in getting things changed
A solution to this problem is to let individual teams manage their own cluster and use the shared repositories as helpers instead. In that scenario, a team can fork the baseline and custom repositories they need and make modifications as they see fit.
Consider the trade-offs though:
- Individual teams need to know what they’re doing with regard to Kubernetes
- Individual teams need to be more disciplined and regularly check the shared repositories for updates, then merge the changes to their own repositories
- IT teams need to trust that individual teams will configure their own clusters according to organization security or regulatory standards
Personally, I like product teams to be responsible for themselves as long as the skills exist and there is accountability. It really depends on your organization’s culture but if you are new to Kubernetes my recommendation is to start with the shared model, and slowly increase autonomy as you gain more knowledge about what works and doesn’t work for you.
Trying It Out
If you want to see this process in action, Perficient has developed an accelerator for AWS using ROSA (Red Hat Openshift on AWS). The included Cloudformation template creates a cluster and all the necessary AWS resources to run Gitops as described in this article.