Introduction
With more and more organizations adopting Kubernetes across multiple teams, the need for IT to provide a way for these teams to quickly provision and configure clusters is increasing fast. This is not only true in cloud environments but also at the edge, and from a practical standpoint, adding more clusters can become exponentially difficult to manage if done individually.
Kubernetes has given development teams a lot of freedom and autonomy to innovate quickly. But the breakneck speed of adoption also caused operations, security, compliance, and infrastructure teams to fall behind. In the last 6 months, we’ve seen a trend in large organizations to try and catch up and put up some guardrails as well as look for ways to improve governance around Kubernetes.
As a developer’s advocate, and startup enthusiast, I have to admit when I hear governance, I immediately think of red tape, roadblocks, and unnecessary speed bumps. This is actually not the case when we engage with central IT today. They seem to be embracing the devops concept more and more and instead of trying to reign in and “regain control”, are more interested in enabling adopters and increasing visibility in existing and future environments.
The key to making everybody happy is more automation, and introducing new tools to help organize Kubernetes clusters at scale. GitOps and ACM are here to save the day!
You can also skip ahead to the good stuff and check out part 2 & part 3
GitOps Basics
This is going to be a quick intro to what gitops is, you can already find a lot of articles about this topic online but I’ll save you the trouble and just summarize what you need to know.
Infrastructure-as-code
If you’ve done any work in the cloud, chances are you are already familiar with infrastructure-as-code (IaC). Tools like Ansible, terraform, chef, CloudFormation, etc have been around for years to provision and manage servers, deploy applications, and more generally organize operational knowledge. If you’ve been doing things the right way, you have your said tools code into a git repository so it can be shared and evolved easily. Typically you would also add some ci/cd pipeline tool in order to run those scripts in an automated fashion. If you’re doing all that, you’re doing things right.
K8s declarative configuration
Enters Kubernetes. You may or may not know that Kubernetes relies on declarative configuration, in other words, every aspect of a cluster is described in state files called manifests, typically in YAML format although you can also use JSON. So instead of making changes to Kubernetes clusters by executing a series of script, you just submit your state files through the Kubernetes API, and various controllers on the cluster react to differences between the current and desired state.
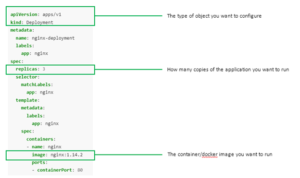
Example of a deployment manifest which creates 3 nginx pods
Kubernetes has a simple command line which wraps the CRUD API to manage state files and if you’re just playing around that’s a great way to get started.
kubectl create -f deployment.yml
kubectl update -f deployment.yml
kubectl delete -f deployment.yml
If you’ve ever used Kubernetes, no doubt you have used these commands before. If you save and commit all your manifests to git, you can then pull your repository and create/apply any number of manifests recursively to make changes to the cluster.
You can then throw a ci/cd pipeline on top of that and trigger updates when your repository is updated. This is what most organizations do at first, it’s familiar, it’s been working, and they do that for their other IaC tools. And this is fine for a single cluster but it gets a little bit more complicated when you have to propagate changes to multiple clusters, have multiple teams using the cluster(s) and your ci/cd tool requires admin access to your clusters which is certainly a security risk.
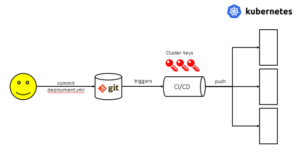
Classic release process with ci/cd
GitOps to the rescue
Simply, GitOps is IaC specifically for Kubernetes and a CD process. I say process because you have a choice of a couple tools to actually implement it, depending on preferences, use cases, security requirements, Kubernetes distribution, etc. But they essentially all do the same thing: sync your desired cluster state from Git.
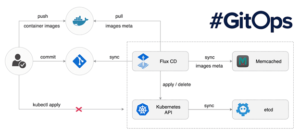
How is it different from Terraform? First of all, terraform is not declarative. You need to execute your terraform scripts yourself and it’s not immediately apparent what the state of your cluster looks like just by looking at some terraform scripts. In the cloud, it does a great job at maintaining an internal state of your infrastructure, but it’s not built to understand what’s going on inside Kubernetes. Teams that use terraform to manage Kubernetes deployments typically run the kubectl cli extension to push manifest changes to the clusters. I feel that using a CLI in terraform defeats the purpose of using a specialized tool, you might as well run the scripts from your ci/cd directly.
GitOps tools, on the other hand, are built for Kubernetes. Just by looking at the manifests in git, you can immediately know what your cluster state is at any given time. As you can see from the diagram above, GitOps uses a pull model to bring the manifests to the cluster. We’ll see how that helps when dealing with multiple clusters in a little bit.
GitOps Options
The two main GitOps vendors at the moment are FluxCD and ArgoCD. Both are CNCF projects, both implement the same basic GitOps process, but they have slight variations in how they organize manifests and implement security. We’ve successfully used both in our engagements, regardless of the environment and Kubernetes vendor.
For this particular approach, we’ve selected ArgoCD, because we’re using Openshift as the Kubernetes platform and Red Hat Openshift GitOps is based on ArgoCD. Red Hat ACM also has out-of-the-box integration with ArgoCD which will make some aspects easier, but you could use FluxCD and another Kubernetes vendor and get very similar results.
Why/how we use GitOps
Let’s get to the good part. I’m a very pragmatic person. I typically don’t adopt a new tool or process unless I have an existing limitation or I see a clear potential for improvement. In other words, no “shiny ball syndrome” here. I’ve been using IaC for a long time, and GitOps solves problems with Kubernetes that are not easily addressed by using existing tools. This applies to all milestones in your Kubernetes journey, regardless of where you are, if you’re not using GitOps, you’re seriously missing out! Let’s look at the benefits of adopting GitOps at different stages of your Kubernetes journey.
Early Stage
Developers friendly
A lot of our focus with Kubernetes is on enabling development teams. We want to start an engagement with Kubernetes and allow developers to be productive on day one. That means, without having to install and configure new tools, assuming they use git (but who doesn’t?), they can just start typing some yaml code in their favorite text editor and commit. They’re already familiar with that process.
No learning curve
With GitOps, you can start deploying workloads on Kubernetes without really understanding anything about the underlying architecture of container orchestration. Just copy/paste some deployment, service, and route manifests from examples, replace with your values and commit. Most already know about YAML format, and the manifests are usually very easy to understand, most of the complexity has been abstracted out in Kubernetes controllers. They also don’t have to learn about Terraform or Ansible, etc or the kubectl command itself.
Growth Phase
Mistake-proof
As more and more people start using the cluster and making changes, things break, people don’t remember what they did. With GitOps, a simple revert commit can restore a cluster to the last know good configuration. And because it’s all declarative, you don’t risk having lingering resources. The cluster will be restored to the exact same state it was at a given commit.
Organize operational knowledge
Going beyond basic application deployments, you start adding new features to your cluster, installing operators, creating security rules, etc and you need to keep things organized. Making those changes directly through the interactive cli and web console will result in lost knowledge when it comes time to create more clusters. GitOps is easy enough that it doesn’t add more time to channel cluster changes through git: kubectl apply -> git commit, same effort.
Multi-cluster configuration management
Further down the road, everybody wants to use Kubernetes in your organization but you want to ensure some consistency between clusters, and you don’t want every single team to re-invent the wheel. Because GitOps uses a pull model, multiple clusters can share the same git repository which provides a basic level of governance, and allow multiple teams to collaborate on a cluster configuration baseline.
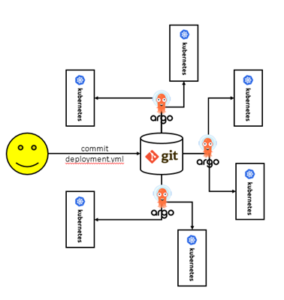
ArgoCD Pull Model
Steady State
Security
GitOps provides a control layer by not allowing people to make changes to clusters directly. In fact, we typically don’t provide write access to anybody except super-admins and redirect development teams to the git repositories to deploy applications. It not only prevents users from making untracked changes to clusters, it prevents external agents from gaining access to clusters through regular developer accounts. You can leverage your existing git access policy to regulate changes to the clusters as well as restrict what ArgoCD is allowed to do on behalf of the users. This is a whole blog article on its own.
Governance
By having multi-clusters share a common baseline as a GitOps repository, you can define what a cluster configuration should look like, in general. That doesn’t prevent individual teams from augmenting the baseline with custom changes, but you probably want to make sure that everyone is using things like cluster logging, monitoring, ingress, etc. While GitOps alone cannot address all aspects of governance, it’s still a good place to start.
Release management
Once you have clusters in production, you need to manage how workloads get promoted between different environments. In typical CI/CD fashion, you would end up with multiple stages in your pipeline to target dev/qa/prod, etc with approval gates in most cases. If you’re following 12 factor app recommendations, you already architected your application to read configuration variables from the environment. With Kubernetes, we want to make sure this is the case and use immutable images so we know that the application we’re deploying to prod is the same one that was tested in QA for example. Moving images between environments then is just a matter of referencing that image in the correct deployment manifest in git, for that environment. If you’re using git branches for your Kubernetes environments, then you’d simply merge the qa branch to the prod branch to promote a buid.
Disaster Recovery
Whether you’re using multi-region active/active or active/passive deployment models for your Kubernetes cluster, you can leverage gitops to git multiple clusters in sync as we’ve discussed before. If your two clusters share the exact same repositories, then their state will be completely identical. That way you don’t have to worry about a region going down. You can also do that between hyperscalers as long as the clusters have access to the same git repository. Now if your cluster goes down for some unexpected reason or you are a victim of a ransom attack, having your cluster state in Git allows you to re-create an identical cluster within just a few minutes, in the same cloud, or a completely different environment. You can also use that approach to save money and delete development clusters during off-business hours and re-create it brand new in the morning.
Overall GitOps Flow
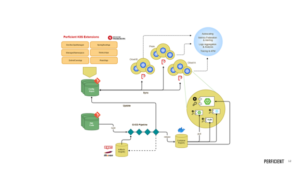
This is a pretty typical GitOps flow for the management of applications and cluster configuration.
For application developers:
- App code and deployment manifests are separated in two different repositories
- App code repositories are not affected by gitops, they just contain application code as usual
- Changes to app code triggers a ci/cd pipeline which results in the creation of a container
- The container is uploaded to a container registry
- The pipeline updates the deployment manifest in the config repo with the new container image version
- ArgoCD automatically deploys the updated manifest to the cluster(s) causing an application rollout
For admins:
- Cluster manifests are stored in a config repo(s)
- Admins add/update manifests in the repo(s)
- ArgoCD automatically applies to the changes to the cluster
Conclusion
In this first part of our multi-cluster management series, we’ve covered the basics of GitOps and why you should seriously consider adopting it if you’re doing any type of work on Kubernetes. My opinion is that GitOps should be the first thing you install on any cluster, even if you’re at the very beginning of your journey, especially if you are at the beginning actually. You really don’t want to be 3 months down the road and lose your cluster and have to start from scratch, and I’ve seen it happen.
Some good resources to understand more about the specifics of GitOps:
https://www.weave.works/technologies/gitops/
https://blog.argoproj.io/introducing-argo-cd-declarative-continuous-delivery-for-kubernetes-da2a73a780cd
In our next post in this series, we’ll look at a reference architecture and implementation to help you get started on the right foot. Stay tuned!