
The problem statement:
An organization having a lot of FMCG products, conducts campaigns in various cities across India. The main aim of this campaign is to promote the products and collect feedback from the customers both existing and prospective ones.
The data is collected in excel files and loaded to a centralized location in the Cloud. Though the excel sample files have been shared with the campaigners, they added new columns if they felt that the data collected might be relevant. In such a scenario structure of all the input source files may or may not be the same.
So, each new source file comes with a new schema most of the time, i.e., some columns added, or some columns deleted. In such a scenario reading the input data and sending it to the next step in the pipeline is impossible and the ETL process fails at the first step.
However, the data is vital and needs to be further processed as the organization wants to draw useful business insights.
The approach:
Since we have raw data which is fluctuating every single time it will lead to a change in the structure of the table/ To avoid that, we use a simple programming language like Python to read the source file and convert it to a JSON file.
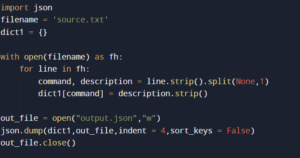
This JSON data in the file can now easily be dumped into a stage table in the Snowflake database.

Getting the source file converted into a JSON file we must dump it into the staging table of a snowflake by concentrating on specific columns which are required for data warehouse reports.
The JSON file can be loaded into snowflake using a two-step process:
First, use the PUT command wherein we need to upload the data file into the snowflake internal stage.
Second, using COPY INTO is used to load the file from the internal stage to the snowflake table.
To complete this two-step process we need to complete some prerequisites:
Creating a target relational table for JSON data —
Create or replace table JSON_data(
/* columns which are required */
);
Creating a named file format with the file delimiter set as none and the record delimiter set as the new line character—
When loading a JSON file or any semi-structured file we should set CSV as the file format type if we use JSON as file format any error in transformation would stop the COPY operation
Creating a temporary internal stage that references the file format object.
Now using the PUT command we’ll dump the data into internal storage (for windows):
Put file://%TEMP%/(name of the JSON file) @(temporary internal stage)
Creating a query in the COPY statement identifies a numbered set of columns in the data files we are loading from.
So finally, after completing the two-step process, we can get the final staging table in snowflake after dumping the source data.
Hence after getting ever-changing source data into snowflake using a simple select statement, we can get the desired columns which will help to reduce the efforts of mapping the columns and result in reducing the processing time and the baggage of the ETL tool.
The Conclusion:
Since we are talking about ever-changing which is related to FMCG campaigns like cosmetic and daily care products the amount of data getting processed and loaded to the database is enormous.
However, since we use snowflake the processing time is very less compared to any on-prem database using snowflake has many advantages like:
1. Storage capacity – It is a cloud-based storage blob i.e., an object storage solution for the cloud helpful for storing massive amounts of unstructured data. Snowflake can run on Microsoft Azure
2. Multi-cloud – We can host snowflake on other popular platforms too.
3. Performance tuning – It is user-friendly and helps the user to organize data and a highly responsive platform that performs optimally.
4. Star schemas – Snowflake is a star schema design that simply makes it fast and better optimized.
Using snowflakes in such a scenario helps us to truncate the work of mapping each column in the ETL tool while building up the process of transforming data through pipelines.
Good explanation. Well Done, Diksha!
Nice article, Diksha
Nice and informative.. thanks for sharing Diksha!