
IBM Cloud Pak for Data- Multicloud Data Integration and Data Governance:
As we all know, IBM Cloud Pak for Data is a cloud-native solution that enables you to put your data to work quickly and efficiently. Let’s understand below features of IBM Cloud Pak for Data. I’ll also be discussing what practical experience I have gained while working on this through some detailed steps:
- Multicloud Data Integration with DataStage as a part of Data Fabric Architecture
- DataStage AVI (Address Verification Interface)
- Watson Knowledge Catalog – Data Governance Processes and Data Privacy
Multicloud Data Integration with DataStage:
IBM DataStage on IBM Cloud Pak for Data is a modernized data integration solution to collect and deliver trusted data anywhere, at any scale and complexity, on and across multi-cloud and hybrid cloud environments.
This cloud-native insight platform — built on the Red Hat OpenShift container orchestration platform — integrates the tools needed to collect, organize and analyze data within a data fabric architecture. Data fabric is an architecture that facilitates the end-to-end integration of various data pipelines and cloud environments through intelligent and automated systems.
It dynamically and intelligently orchestrates data across a distributed landscape to create a network of instantly available information for data consumers. IBM Cloud Pak for Data can be deployed on-premises, as a service on the IBM Cloud, or on any vendor’s cloud.
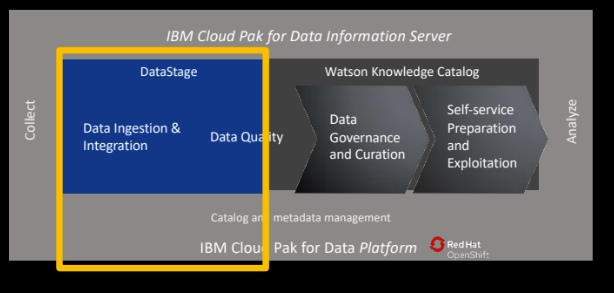
Source of above Data Stage diagram: IBM Documentation
Prerequisites: Need to have Data Stage Instance provisioned to perform the required tasks.
Below are the Tasks performed on Data Stage:
- Created a project and added DB2 as a connection
- Added data to the project. Data added from a local project sample file
- Create a DataStage flow that extracts information from DB2 source systems
- Performed steps using operations to transform the data using filters on Customer columns.
- Compiled and ran the DataStage job to transform the data.
- Deliver the data to Target – Project – Asset Tab, and Data asset Customers were present there.
Prerequisites:
- Signed up for Cloud Pak for Data as a Service
- Added Data Stage Service Instance
- Also added Watson Knowledge Catalog and Cloud Object Storage services
Below are the Tasks performed on Data Stage for Multiload Data Integration:
- Created a Sample Project and associated with a Cloud Object Storage instance
- Ran an existing DataStage flow that created a CSV file in the project that joins the two different Customer application data sets.
- Edited the DataStage Flow and changed the Joint node settings, and selected the Email Address column name as Key
- Added PostgresSQL Database to the DataStage Flow to get more Customer related information.
- Added another Join Stage to join filtered application data
- Added a Transformation Stage that created a new column by summing up two different Customer $amount columns.
- Added MongoDB database to get more information related to Customer
- Added a Lookup Stage and specified the range to get Customer information
- Ran the DataStage flow to create the final Customer output file.
- Created a Catalog so data engineers and analysts can access the relevant Customer Data.
- Viewed the output file in the Project and Published it to a Catalog
- In the Project->Asset Tab -> Now, you can view the data.
DataStage AVI (Address Verification Interface):
IBM’s Quality Stage Address Verification Interface (AVI) provides comprehensive address parsing, standardization, validation, geocoding, and reverse geocoding, available in selected packages against reference files for over 245 countries and territories.
AVI’s focus is to help solve challenges with location data across the enterprise, specifically addresses, geocodes, and reverse geocode data attributes. Data Quality and MDM have never been more critical as a foundation to any digital-minded business intent on cost and operational efficiency.
IBM cares about Quality addresses to avoid negative customer experience, Fraud Prevention, Cost of Undelivered and returned Mail, and maintaining key Customer Demographic data attributes.

Source of the above diagram: IBM Documentation
Prerequisites:
- Signed up for Cloud Pak for Data as a Service
- Added Data Stage Service Instance
Below are the Tasks performed on the Data Stage AVI Feature:
- Created an Analytics Project in IBM Cloud Pak for Data
- Added a Connection to the Project -> Selected DB2 and provided all DB and Host details
- Added DataStage Flow to the Project. Below three Primary Categories appear
- Connectors (Source and Target Access Points)
- Stages (Data Aggregation, Transformation and Table lookup, etc.)
- Quality (Data Standardization and Address verification)
- Added and Configured Connectors and Stages to the DataStage Flow
- Added a Source Connector from Asset Browser and selected address as an Input
- Added Address Verification from the Quality menu
- Added Sequential file to generate the .csv output
- Connected all the above 3 files from left to right
- Provided the required details and inputs for Address Line 1 and Address Line 2
- Compiled and Executed the AVI DataStage Flow
- Go to Project ->Data Asset->You would see a .csv file would be created
- Open the .csv file and review the columns. Here you will see more columns added from the Address Verification Process
- Please review the Accuracy Code String to see Verified versus unverified addresses.
Watson Knowledge Catalog:
IBM Watson Knowledge Catalog on Cloud Pak for Data powers intelligence, the self-service discovery of data, models, and more, activating them for artificial intelligence, machine learning, and deep learning. With WKC, users can access, curate, and share data, knowledge assets, and their relationships wherever they reside.
WKC’s below features were performed and tested.
- Data Governance processes include role assignment, access control, business terms, and classifications.
- Created a Centralized Data Catalog for Self-Service Access
- Created workflow to manage the business processes
- Mapped Business value to Technical asset
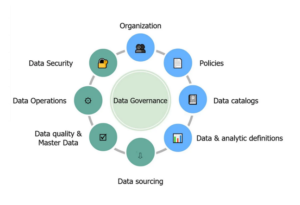
Source of above Data Governance diagram: IBM Documentation
Prerequisites:
- Signed-up for Cloud Pak for Data as an Admin
Below are the Tasks performed on Watson Knowledge Catalog:
- Click Administrator->Access Control->Created a New User Group
- Added Users under New User Group:
- Quality Analyst
- Data Steward
- Provided Pre-defined Roles – Administrator, Data Quality Analyst, Data Steward, and Report Administrator.
- Go to Governance -> Categories –> Customer Information ->Customer Demographics subcategory to view the Governance Artifacts
- Here you can explore the Governance Artifacts such as Address, Age, Date of Birth, Gender, etc.
- Go to Governance -> Business Terms ->Account Number. Here you can view the business terms such as – Description, Primary Category, Secondary Category, Relationship, Synonyms, Classification, Tags, etc.
- Go to Governance -> Classifications-<Confidential Classification. Here you can view the business terms such as – Description, Primary Category, Secondary Category, Parent/Dependent Classification, Tags, etc
- Go to Administration -> Workflows ->Governance artifact management->Template file-> You will find different approval templated here, including publish and review steps.
- Selected Automatic Publishing and provided Conditions (Create, Update, Delete, Import)
- Saved and Activated it.
- There were more things you could do in WKC, such as:
- Creating Governance Artifacts for Reference data to follow certain standards and procedures.
- Creating Policies and Governance Rules
- Creating Business Terms
- Creating Reference Data sets and Hierarchies
- Creating Data Classes – such as data fields or columns
Watson Knowledge Catalog – Data Privacy:
Here I have learned:
- How to prepare trusted data with Data Governance and Privacy use case of the Data Fabric.
- Created Trusted data assets by enriching them and with data quality analysis.
- The goal was how data consumers can easily find high-quality and protected data assets via a self-service catalog.
Prerequisites:
- Signed up for Cloud Pak for Data for data as a service with Watson Knowledge Catalog Services
Below are the Tasks performed on Watson Knowledge Catalog:
- As a data steward – Created a Catalog by going to the Catalog menu with Enforce Data Policies
- Created Categories by going to Governance ->Categories. This contains the Business Terms that we have to import later.
- Added Governance ->Business Terms and imported the .csv file
- Published the Business Terms.
- Imported data to a Project by going to Projects ->Data Governance and Privacy Project->Assets->New Asset->Metadata Import ->Click Next->Select the Project->Select Scope and Connection
- Selected Data Fabric Trial for DB2 Warehouse connection so the data can be imported and viewed as a table.
- Enriched the Imported data by selecting Metadata Enrichment from the Assets tab. You can Profile the data, Analyze the Quality and Assign the terms. This will help the end-user to find the data faster.
- Viewed the Enrich metadata
- Published the enriched data to a Data Catalog.
Conclusion: IBM Cloud Pak for Data is a robust Cloud Data, Analytics, and AI platform that provides a cost-effective, powerful MultiCloud Data Integration and Data Governance solution.