As with any IT initiative, it is very important for an organization to align business and technology needs when choosing to invest in data analytics and big data processing. We are seeing an increase in big data use cases in financial services around customer data to explore new markets, enable product development, enhance cross-sell capabilities, provide targeted offers, and improve ongoing customer support. For many of these use cases, big data needs to capture data that is continuously changing and unpredictable. Financial services institutions tapping big data capabilities to analyze new data sets will find a new architecture is needed. Organizations will want to avoid moving raw data directly into a data warehouse.
For the purpose of this post, I am going to focus on three key big data architectures and various drivers you need to consider when making choices to support enterprise needs and budgets.
Proprietary Models
Proprietary technology models for big data capabilities traditionally require a significant capital expense for software and hardware resulting in a higher total cost of ownership. Often times the requirements and risks of managing open-source components, the network infrastructure layer, multiple servers, custom code, and numerous copies of data become unfeasible and uneconomical. It is very important do a build-versus-buy analysis when thinking about building a big data platform. Building custom tools may seem like a cost-saving measure, but it’s not always wise when buying technology could save untold man-hours and avoid delays or abandoned big data projects.
Big Data Appliances

A big data appliance model is an effective way to implement capabilities at a lower cost of ownership. Outside of the work to identify business and IT performance drivers, the overall implementation is shortened and allows the business to focus on data modeling and analytics. As opposed to building a big data system from scratch, appliances eliminate the time-consuming effort of configuring hardware and open-source components. Often times more money and time is spent on network switches, bandwidth and and infrastructure (which can be an eye-opening experience) making the ease of use and faster time to market even more appealing to the enterprise. Appliances connect the dots between activities across consumer banking channels to offer better promotions and target key customers.
Hadoop, an open source distributed file system, is seen as the cornerstone for big data processing. Hadoop does limit upfront licensing costs for managing and processing large volumes of data. In addition to it being open source it is also data agnostic, allowing flexibility for banks and financial services companies looking to gain insight from unstructured data sources like web logs and social media. Unstructured content like social streams and click streams are quick wins for big data in banking. As a result, we’re seeing a large number of technology providers like IBM, Teradata and Oracle developing Hadoop-based analytics software tools and appliances for big data to help businesses find value in both structured and unstructured data. By integrating components of a big data platform into a flexible, scalable and supported big data architecture, financial services companies and banks can focus on finding value in customer insights faster.
The reduced storage and server requirements make appliance models affordable big data architecture. Despite minimizing enterprise storage with Hadoop, businesses still face issues with commodity servers for big data storage. Disk storage failures on commodity boxes and node outages can be costly, require additional network resources and monitoring tools, and may prohibit time-sensitive analyses of data with delays. As you can see, it’s very important to look at all the infrastructure options available to you for implementing big data.
Big Data Platforms in the Cloud
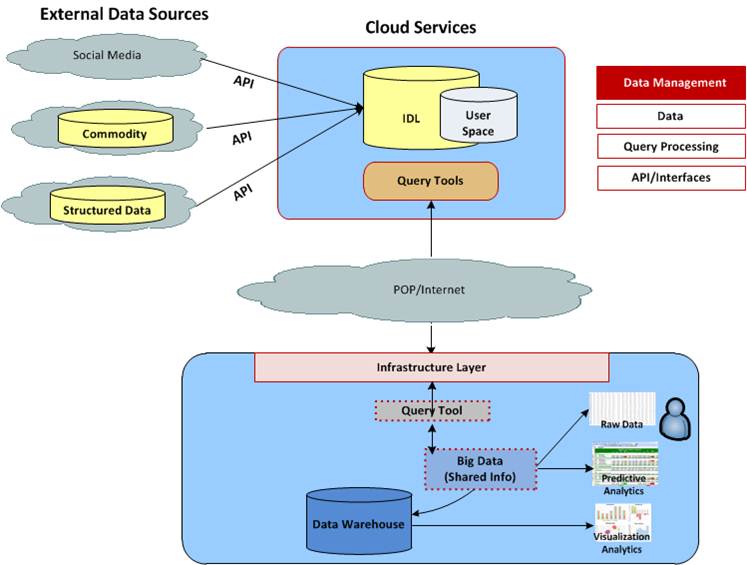
The cloud doesn’t have to be a dirty word. When implementing a cloud-based big data platform, organizations will benefit from the use of an Investigative Data Lab (IDL). An IDL allows business users access to data to look for signals in social media, commodity data and unstructured data. When signals are found it can be socialized across lines of business, queried in the cloud (no enterprise backup and recovery needed), brought into the internal environment, parced into a data warehouse and shared in a cache model or through query tools. Pulling in large data sets is very expensive over time. By focusing on finding the signal in data, banks can pull only valuable pieces of data into the enterprise data warehouse.
Below is a diagram of cloud-based big data architecture.
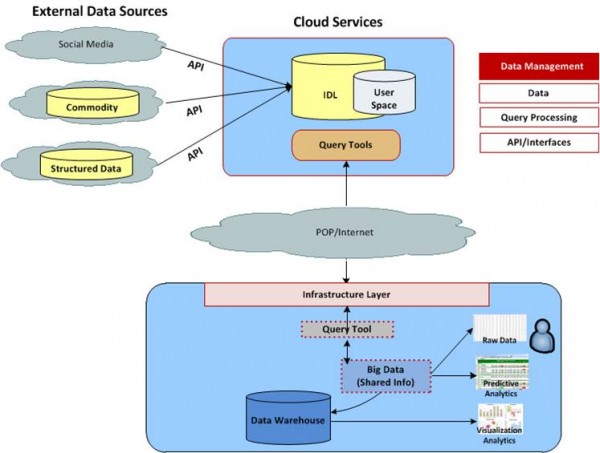
Vendors like infochimps are great at deploying real-time, ad-hoc and batch analytics through a big data infrastructure in the cloud. Cloud services and infrastructures support the use of text analytics for voice of customer (VOC) or sentiment analysis without a lot of manipulation. Banks can also leverage the cloud for click stream analysis to look for keywords being searched for (both internally and externally).
As you can see, there’s a lot to consider when making architecture decisions to add big data capabilities. The technology landscape continues to evolve, as well, making it hard to plan for the future. Not to mention, many banks still struggle with finding value in existing data. How can we help? Perficient is expertly positioned to implement data governance programs and big data assessments and roadmaps for business-driven technology solutions in the financial services industry. Learn more about Perficient’s big data capabilities.