
AWS Athena is an interactive query service offered by Amazon that makes it easy to examine the data directly in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and we pay only for the queries which we run. Athena is easy to use. It simply points the data that is present in S3 and start querying the data using standard SQL. Most results are delivered within seconds.
When to use AWS Athena
Athena is used to analyse the data which is present in Amazon S3. Athena can operate with various types of structured and unstructured data types which includes data formats like CSV (comma-separated value), ORC (Optimized Row Columnar), Apache Parquet and Apache Avro, JSON (JavaScript Object Notation). You should use Athena if you want to run interactive ad hoc SQL queries for the data which is in Amazon S3. Athena provides us the easiest way to run ad hoc queries for data in Amazon S3
We can run interactive queries directly for the data present in Amazon S3 without having to format data or manage infrastructure. For example, Athena is useful if you want to run a quick query on web server logs to troubleshoot an issue which our website is facing.
Workflow of AWS Athena
Athena uses Presto which is a distributed query engine and used for running queries and Apache Hive for altering and creating tables and partitions. Athena is charged on a pay-per-query basis (the normal pricing $5 for 1TB of data in S3).

Amazon Athena’s workflow can be seen above. The data is uploaded to an Amazon S3 bucket, from which we query the data that is stored using Athena.
Advantages of Athena
- Serverless: Quickly query the data without any configured infrastructure
- Integration: Integration with many tools including: AWS Glue, Amazon Quick Sight, and Key Management Service (KMS).
- Secure: Uses Amazon S3 bucket policies and access control lists, as well as AWS Identity and Access Management (IAM) policies to ensure security.
- Pay-per-query: Pay only for the queries you run.
- Fast: Designed for fast performance. Perform queries side-by-side allowing users to get result within the seconds.
How Athena Works:
Below is an example how we can use Athena to query data in a S3 bucket.
I have the data in a CSV file format of the students’ names and their test percentages.
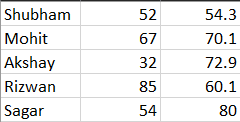
I have already uploaded this data to my S3 bucket.
- We need to open Athena service from our AWS dashboard. After opening Athena, you will see the dashboard below.

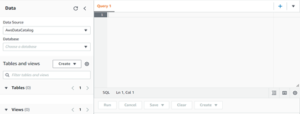
- Now we need to select the database. We can also create a database by using the below query
- create database “Data base name”;
- I have created a database with the name “AWS_test”
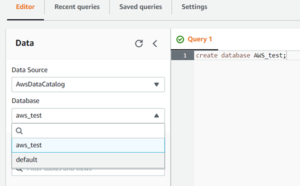
- If you have already created a database, you can simply select your database from the drop-down menu of database.
- Now we must create tables. You can create a table by clicking on the create tab.
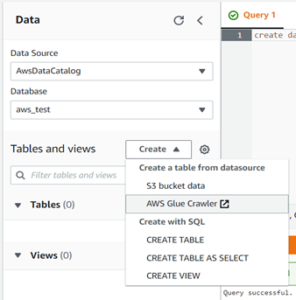
- As you can see there are many options present for creating the table, but we have to use the S3 data. So, we will select S3 bucket data.
- After selecting the S3 bucket data, you will be redirect. Here we have to enter the name for the table we want to create. I have named the table “Test” for this instance.
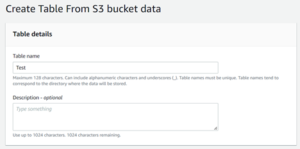
- Now we have to select the database. We are using the existing database which we have created earlier “AWS_test”
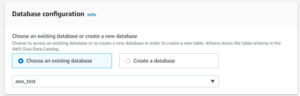
- You will need to enter the location of the file which is stored in our S3 bucket.
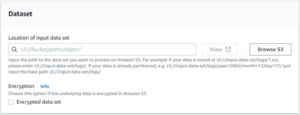
- If you want to find out the location of the file which is in S3. You can simply go in the S3 bucket on that file location.
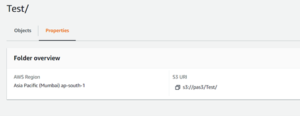
- Select properties, there you can find the S3 URL copy, as show below, and paste that in the location of data set.
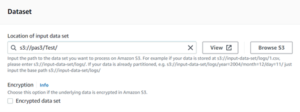
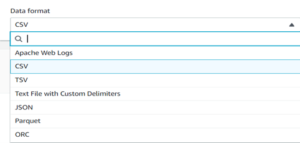
- We will need to specify the type of file. For EX: CVS, JSON etc.
- Next, we will name the columns. As you can see above in my file there are 3 columns. If you have too many columns in your file, then you can use bulk add column feature. Where one can add multiple columns at a time.
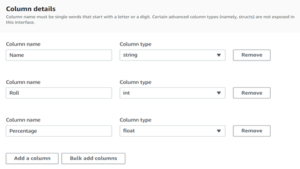
- We have to specify the name of the column and its data type like the value in the column is string, int or float or etc.
- Now press create table and your table will created
- Now we will query the data which is in the file using standard SQL.
- For running any query in Athena, we just need to write them in the box and select Run
- I am running the below query to show all the data which is in the file
- select * from Test;
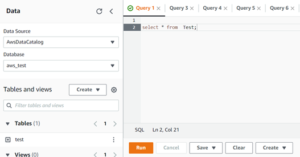
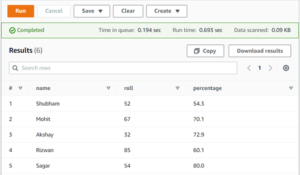
As you can see below after running the above query, I get the output of all the data which was present in my file
I have also run the below query where I specify a particular name of student and got the detail about them like what their roll number and percentage.
select * from Test where name = ‘Mohit’;
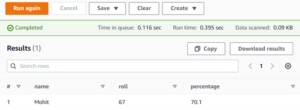
As you can see, Athena is quite easy to use and makes our workflow simpler. We just have to run the right query to receive the intended results within seconds!
How Can Perficient Help You?
Perficient is a certified Amazon Web Services partner with more than 10 years of experience delivering enterprise-level applications and expertise in cloud platform solutions, contact center, application modernization, migrations, data analytics, mobile, developer and management tools, IoT, serverless, security, and more. Paired with our industry-leading strategy and team, Perficient is equipped to help enterprises tackle the toughest challenges and get the most out of their implementations and integrations.
Learn more about our AWS practice and get in touch with our team here!
Very well articulated!! Keep up the great work!!
Superb explanation, I was even not aware of it.
Great job keep it up Hassan.
All the best 👌
Well Written,,, This Article very useful for production Environment.
Very Well Explained Syed!! Hope this article might get useful to us in future.
All the best.
Very well articulated even I am also not aware of.
You’re already doing a fab job and keep up the momentum. Well done Hassan.
Very well explained and super informative . Keep up the good work.
Amazing write-up, Looking forward for more such informative blogs.
Great Work Syed ! Keep it up
Great work ! This will help a lot.