
A federated architecture for self-improving skills — from every employee’s laptop to the company brain.
Every enterprise has the same problem hiding in plain sight. Somewhere between the onboarding wiki that nobody reads, the Slack threads that disappear after a week, and the senior engineer who carries half the team’s knowledge in their head — institutional knowledge is dying. Not because companies don’t try to preserve it, but because the systems we’ve built to capture it are fundamentally passive. They wait for someone to write a doc. They wait for someone to search. They never learn on their own.
What if every employee’s computer had an AI agent that watched, learned, and guided — and every night, those agents pooled what they’d learned into something smarter than any of them alone?
The State of Enterprise AI Assistants: Smart But Shallow
Today’s enterprise AI tools — Google Agentspace, Microsoft Copilot, Moveworks, Atomicwork — follow the same pattern. A large language model sits in the cloud, connected to your company’s knowledge base. Employees ask questions, the model retrieves answers. It works. But it has three fundamental limitations.
First, all intelligence is centralized. The model only knows what’s been explicitly fed into the knowledge base. It doesn’t learn from the thousands of micro-interactions employees have daily — the workarounds they discover, the mistakes they make, the shortcuts they invent.
Second, there’s no feedback loop from the edge. When a new hire spends 40 minutes figuring out that the VPN must be connected before accessing the PTO portal, that hard-won knowledge dies in their browser history. The next new hire will spend the same 40 minutes. The system never improves from use.
Third, one model serves everyone the same way. A junior developer and a senior architect get the same answers, in the same depth, with the same assumptions about what they already know.
A Different Architecture: Agents That Learn at the Edge
Imagine a three-tier system where intelligence lives at every level — on the employee’s device, on the department server, and at the company core. Each tier runs a different class of model, owns a different scope of knowledge, and communicates on a defined rhythm.
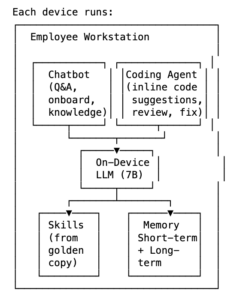
Tier 1: The On-Device Agent (7B–14B Parameters)
Every employee’s workstation runs a small but capable language model — something in the 7B to 14B parameter range, like Llama 3 8B or Qwen 2.5 14B. This model is paired with two things that make it useful: skills and memory.
Skills are structured instructions — think of them as markdown playbooks that tell the agent how to guide the user through specific tasks. A “setup-dev-environment” skill walks a new developer through installing dependencies, configuring their IDE, and running the test suite. A “code-review-checklist” skill ensures PRs meet team standards. These aren’t hardcoded — they’re living documents that the agent reads and follows, and they can be updated without retraining the model.
Memory comes in two layers. Short-term memory captures the day’s interactions: what the user asked, where they got stuck, what worked, what corrections they made. This is append-only, timestamped, and stored locally. Long-term memory is a curated set of facts about the user — their role, expertise level, preferred tools, recurring tasks — that persists across sessions and personalizes every interaction.
The on-device agent is always available, even offline. It responds instantly because there’s no round-trip to a server. And critically, sensitive information — proprietary code, internal discussions, personal struggles — never leaves the machine during the workday.
Tier 2: The Department Server (40B Parameters)
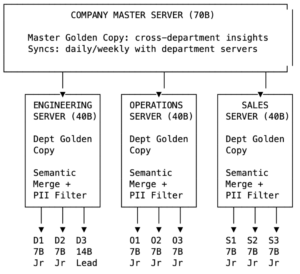
Each department — Engineering, Operations, Sales — runs its own server with a more powerful model in the 40B parameter range. This server has three jobs.
Collecting learnings. On a configurable schedule — real-time, hourly, or nightly depending on the organization’s needs — each device pushes its short-term memory deltas to the department server. Not the raw conversation logs, but distilled learnings: “User discovered that the staging deploy requires flag --skip-cache after the recent infrastructure migration.” A privacy filter strips personally identifiable information before anything leaves the device.
Semantic merging. This is where the 40B model earns its keep. When Device A reports “Docker builds fail on M-series Macs without Rosetta” and Device B reports “ARM architecture causes container build errors on Apple Silicon,” the server recognizes these as the same insight expressed differently. It merges them into a single, authoritative entry in the department’s golden copy — the canonical knowledge base for that team.
Conflict resolution with authority. Not all learnings are equal. The system uses an authority model inspired by API authentication scopes. Each device agent carries a token encoding the user’s role and trust level. A junior developer’s correction gets queued for review. A senior engineer’s correction is auto-merged. A team lead can approve or reject queued items. This prevents the golden copy from being polluted by well-intentioned but incorrect contributions while ensuring high-confidence knowledge flows freely.
After merging, the department server pushes updated skills back to all devices. Tomorrow morning, when a new hire boots up, their agent already knows about the --skip-cache flag — because someone else discovered it yesterday.
Tier 3: The Company Master Server (70B Parameters)
At the top sits the most powerful model — 70B parameters — responsible for the company-wide knowledge layer. This server doesn’t communicate with individual devices. It only syncs with department servers, exchanging golden copies on a daily or weekly cadence.
The key constraint: departments don’t share raw learnings with each other. Engineering doesn’t see Sales’ objection-handling patterns; Sales doesn’t see Engineering’s debugging workflows. This is both a privacy boundary and a relevance filter — most departmental knowledge is only useful within that department.
But the master server can synthesize cross-cutting insights that no single department would discover alone. If Engineering’s golden copy contains “API response times increased 3x after the v2.4 release” and Sales’ golden copy contains “customer complaints about dashboard loading times spiked this week,” the 70B model connects the dots. It pushes a unified advisory to both departments: Engineering gets “customer-facing impact confirmed — prioritize the performance regression,” and Sales gets “engineering is aware of the dashboard slowdown — expected resolution timeline: 48 hours.”
The Daily Rhythm
The system operates on a natural cycle:
Morning. Department servers push updated skills to all devices. Each agent loads the latest golden copy fragments relevant to its user’s role. A new developer gets the freshly refined “setup-dev-environment” skill. A senior engineer gets the latest “production-incident-response” playbook with patterns learned from last week’s outage.
Workday. Each on-device agent guides its user, answers questions, and logs everything to short-term memory. When a user corrects the agent — “No, that’s wrong, you need to run migrations before starting the server” — the agent captures the correction with the user’s authority level.

Sync interval. Based on organizational preference, devices push their learnings to the department server. This could be real-time streaming for fast-moving teams, hourly batches for a balance of freshness and bandwidth, or nightly bulk uploads for organizations prioritizing minimal disruption.
Server processing. The department’s 40B model performs semantic merging — deduplicating, resolving conflicts, filtering PII, and distilling raw observations into authoritative skill updates. High-trust contributions go straight to the golden copy. Lower-trust contributions are queued for review.
Company sync. On a separate, slower cadence, department servers exchange golden copies with the company master. The 70B model looks for cross-departmental patterns and pushes synthesized insights back down.
The Interface: A Chatbot and Coding Agent on Every Machine
The three-tier architecture is the brain. But what the employee actually interacts with is a local chatbot and coding agent running on their machine — powered by the on-device model and grounded in the golden copy that was pushed down that morning.
This isn’t a generic AI assistant. It’s an agent that knows the company’s way of doing things, because the golden copy is the company’s accumulated, distilled operational knowledge. Every answer, every suggestion, every code change it proposes is informed by the patterns, standards, and hard-won lessons that the entire department has contributed to.
For Developers: A Coding Agent That Knows Your Codebase Standards
A developer opens their IDE and the on-device coding agent is available inline — similar to how tools like GitHub Copilot or Cursor work today, but backed by the department’s golden copy rather than a generic training corpus. When the developer writes a new API endpoint, the agent doesn’t just autocomplete syntax. It suggests the error handling pattern that the team standardized last quarter. It flags that the developer is about to use a deprecated internal library that three other engineers already migrated away from. It proposes the exact test structure that passed code review most consistently, based on patterns the department server distilled from hundreds of merged PRs.
If the developer asks “how do I connect to the staging database?” the agent doesn’t give a generic PostgreSQL tutorial. It gives the team’s specific connection string format, reminds them to use the read-only replica for queries, and mentions the VPN requirement — all because those details were learned by other developers’ agents, merged into the golden copy, and pushed down as part of this morning’s skill update.
For New Hires: A Conversational Onboarding Guide
A new operations hire opens the chatbot on day one and simply asks: “What should I do first?” The agent responds with a structured onboarding path tailored to their role — not from a static wiki, but from a living skill that has been refined by the struggles and discoveries of every previous new hire. It walks them through account setup, tool installation, and first tasks step by step, answering follow-up questions in context.
When the new hire asks a question the agent can’t answer confidently, it says so — and logs the gap. That gap becomes a learning signal: if three new hires in a row ask the same unanswered question, the department server flags it as a missing skill that needs to be authored by a senior team member. The system doesn’t just answer questions. It discovers which questions should have answers but don’t yet.
For Everyone: A Knowledge Q&A Layer
Beyond coding and onboarding, the chatbot serves as a universal knowledge interface. “What’s the process for requesting a new AWS account?” “Who owns the billing microservice?” “What changed in the deployment pipeline last week?” These questions get answered instantly from the golden copy, with the confidence that the answers reflect the department’s current, collectively validated understanding — not a stale Confluence page from 2023.
The agent can also proactively surface relevant knowledge. If it detects that a developer is working on the authentication module (based on file context), it might surface a note from the golden copy: “Reminder: the auth module has a known race condition under high concurrency. See the workaround documented after the January incident.” This isn’t the agent being clever — it’s the golden copy doing its job, putting the right knowledge in front of the right person at the right time.
Why On-Device Matters
Running a model on every employee’s machine isn’t just an architectural choice — it unlocks capabilities that cloud-only systems can’t match.
Privacy by design. Code, internal communications, and personal context never leave the device during work hours. Only distilled, anonymized learnings sync to the server. This matters enormously for regulated industries and for employee trust.
Zero-latency guidance. The agent responds in milliseconds, not seconds. For a developer in flow state, the difference between an instant inline suggestion and a 2-second cloud round-trip is the difference between staying focused and being interrupted.
Personalization without centralization. The on-device agent knows this user’s preferences, skill level, and work patterns. It adapts its explanations, adjusts its depth, and remembers past conversations — all locally, without the server needing to maintain per-user state.
Offline resilience. The agent works on airplanes, in server rooms with restricted connectivity, and during cloud outages. The skills it loaded that morning are sufficient for most guidance tasks.
The Federated Learning Parallel
This architecture mirrors a well-established pattern in machine learning: federated learning. Google uses it to improve phone keyboards — each device trains locally on your typing patterns, sends only model weight updates (not your texts) to a central server, and the server aggregates improvements that benefit all users.
The difference is that traditional federated learning operates on model weights — opaque numerical tensors. This system operates on natural-language skills and memories — human-readable markdown that can be version-controlled, audited, and manually edited. An engineering manager can open the golden copy, read every skill in plain English, and decide whether a particular learning should be promoted, revised, or rejected. This transparency is critical for enterprise adoption where auditability and human oversight are non-negotiable.
There’s also a conceptual parallel to knowledge distillation in ML research, where a large “teacher” model’s knowledge is compressed into a smaller “student” model for edge deployment. Here, the 70B company model’s synthesized insights are distilled into skill updates that the 7B device models can act on — not through weight transfer, but through updated natural-language instructions.
Concrete Scenarios
New Developer Onboarding (Week 1)
Monday morning. The developer’s laptop has a 7B model loaded with the Engineering department’s latest skills. The “new-hire-onboarding” skill activates automatically.
The agent walks through environment setup step by step. At step 4, the developer hits an error: node-gyp fails on their specific macOS version. They spend 15 minutes finding the fix on Stack Overflow and tell the agent: “I needed to install Xcode Command Line Tools first — add that as a prerequisite.”
The agent logs this to short-term memory with the user’s authority level (junior). At the next sync cycle, the department server receives this learning. Since three other new hires hit the same issue last month (already in the golden copy as a known friction point), the server’s 40B model upgrades the severity and adds the prerequisite to the onboarding skill.
Tuesday morning, the next new hire’s agent already includes: “Before proceeding, verify Xcode Command Line Tools are installed: xcode-select --install.”
Cross-Department Insight Discovery
The Engineering golden copy contains: “API latency P99 increased from 200ms to 800ms after deploying service mesh v3.2.”
The Sales golden copy contains: “Three enterprise prospects paused contract negotiations citing ‘platform performance concerns’ this quarter.”
Neither department connected these. During the weekly company sync, the master 70B model identifies the correlation and pushes an advisory to both: Engineering receives a business-impact escalation, and Sales receives a technical context update with an estimated resolution timeline sourced from Engineering’s incident tracking.
Open Questions and Honest Limitations
This architecture is a synthesis of existing building blocks — on-device models, skill-based agent systems, federated sync patterns, semantic merging — assembled in a way that doesn’t exist as a product today. Several hard problems remain.
Merge quality at scale. Semantic merging works well with 10 devices. With 500, the volume of daily learnings could overwhelm even a 40B model’s ability to meaningfully synthesize. Hierarchical sub-teams within departments — team leads running intermediate merges — may be necessary.
Skill drift. If the golden copy evolves continuously, skills from six months ago might be unrecognizable. Version control and the ability to diff skill changes over time are essential. Treating the golden copy as a git repository with commit history is one approach.
Model capability at the edge. A 7B model can follow instructions and log observations, but its reasoning is limited. It might misinterpret a user’s correction or log a false insight. The authority system mitigates this — low-trust contributions get reviewed — but it doesn’t eliminate the risk.
Adoption friction. Employees need to trust that their on-device agent isn’t surveillance. The system must be transparently opt-in for the learning cycle, with clear boundaries between what stays local and what syncs. The privacy filter must be verifiable, not just promised.
Hardware cost. Running a 7B model on every employee’s laptop requires machines with sufficient RAM and ideally a capable GPU. For many knowledge workers with modern laptops, this is already feasible. For organizations with aging hardware fleets, it may require phased rollout.
What Exists Today
The building blocks are real and available now:
- On-device models in the 7B–14B range run comfortably on Apple Silicon Macs and modern workstations using tools like Ollama, llama.cpp, and LM Studio.
- Skill-based agent frameworks — notably the AgentSkills open standard developed by Anthropic and adopted by multiple platforms — define exactly how to package instructions as markdown files that agents can discover and follow.
- Memory architectures with short-term daily logs and long-term curated knowledge are production-tested in platforms like OpenClaw, which uses
MEMORY.mdfor persistent facts andmemory/YYYY-MM-DD.mdfor daily context. - Self-improving agent patterns exist in the wild — OpenClaw’s community has published skills that capture corrections and learnings automatically, and the Foundry plugin demonstrates a full observe-learn-write-deploy loop on a single device.
- Federated learning is a mature field in ML research, with frameworks like NVIDIA FLARE and Flower enabling distributed training across devices.
- Hierarchical multi-agent architectures — supervisor agents coordinating specialist agents across departments — are in production at companies like BASF (via Databricks) and documented extensively by Microsoft and Salesforce.
What nobody has assembled is the specific combination: on-device small models learning from daily use, syncing through department servers with semantic merging and authority-based trust, rolling up to a company-wide master that discovers cross-departmental patterns — all operating on human-readable, version-controllable, natural-language skills rather than opaque model weights.
The Bet
The bet is simple. Today’s enterprise AI is a library — it holds knowledge and waits for you to ask. The architecture described here is a living organism — it learns from every employee, improves overnight, and wakes up smarter each morning.
Every company already has the knowledge it needs to onboard faster, debug quicker, and operate more efficiently. That knowledge just lives in the wrong places: in people’s heads, in forgotten Slack threads, in tribal rituals passed from senior to junior. An on-device AI agent that captures this knowledge as it’s created — and a federated system that distills it into something the whole organization can benefit from — doesn’t require any breakthrough in AI capability. It requires assembling pieces that already exist into a system that nobody has built yet.
The pieces are on the table. Someone just needs to put them together.
This post explores a conceptual architecture for federated, on-device AI agents in enterprise settings. The building blocks referenced — AgentSkills, OpenClaw, federated learning frameworks — are real, production-available technologies. The specific three-tier system described is a proposed design, not an existing product.

This is a compelling and forward-thinking article that highlights how on-device AI agents can transform enterprise learning by making it more personalized, secure, and adaptive. It clearly shows the potential for smarter, faster skill development while addressing real-world challenges like data privacy and scalability.
This is a strong take on where enterprise learning is headed. The focus on on-device AI agents and privacy feels especially relevant as companies try to balance personalization with data security. It’s a thoughtful read that goes beyond the usual AI hype.
– Zakiul
Really interesting perspective on how on-device AI agents can change the way enterprise learning works — personalized guidance, instant help, and real knowledge captured from real work! 🌟 Love the idea of a system that learns from everyday interactions and makes the organization smarter over time. 👏
Insightful perspective on enterprise AI architecture!
I really like how this article goes beyond typical cloud-based assistants and highlights the limitations of centralized intelligence. The three-tier model — on-device, department server, and company master — feels practical and scalable, especially with the focus on edge learning, privacy, and role-based authority.
The idea of semantic merging at the department level and cross-functional synthesis at the company level is particularly powerful. It solves a real problem most enterprises face: knowledge fragmentation. The comparison to federated learning and knowledge distillation also makes the concept easier to understand from a technical standpoint.
What stands out most is the emphasis on continuous learning from real employee interactions rather than static knowledge bases. That’s where true enterprise intelligence evolves — not from documents alone, but from lived workflows.
Overall, this presents a thoughtful and forward-looking blueprint for building AI-first organizations that are adaptive, privacy-aware, and genuinely intelligent rather than just “smart but shallow.”