
Introduction
Edge computing and more generally the rise of Industry 4.0 delivers tremendous value for your business. Having the right data strategy is critical to get access to the right information at the right time and place. Processing data on-site allows you to react to events near real-time and propagating that data to every part of your organization will open a whole new world of capabilities and boost innovation.
Today we want the edge to be an extension of the cloud, we’re looking for consistency across environments and containers are at the center of this revolution. It would take way too long to do a comprehensive review of all available solutions, so in this first part, I’m just going to focus on AWS, Azure – as the leading cloud providers – as well as hybrid-cloud approaches using Kubernetes.
Solution Overview
At the core of Industry 4.0 is the collection of equipment and devices data and dissemination of said data to local sites as well as the rest of the organization. The basic flow of data can be summarize like so:
- Events are emitted by IoT devices over OPC-UA or MQTT to a local broker
- Part of the raw data is consumed directly for real-time processing (anomaly detection, RT dashboards, etc)
- Part of the data is (selectively) copied to a message broker for event-driven services, streaming analytics
- Messages are also (selectively) transferred to the cloud for analytics and global integration
- Configuration can also be pushed backed to the sites post-analysis
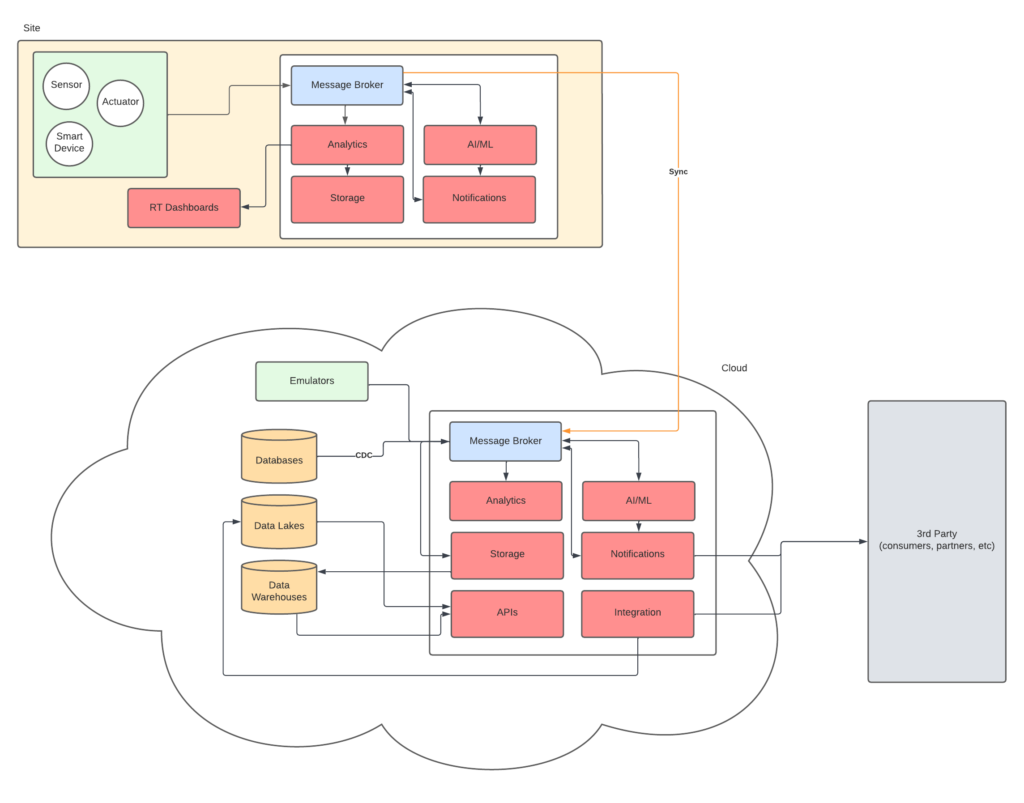
Industrial IoT (IIoT) solution overview diagram
Data Flow
Data Collection
Looking at the edge-most side of our diagram (top in light green), the first step in the solution is to collect the data from the devices. OPC-UA is very typical for industrial equipment, and the historical way we’ve been collecting events on the factory floor. The second, more modern option is MQTT, now available on most IoT devices and certain industrial equipments. Both are IoT optimized transport protocols like HTTP. OPC-UA also specifies a standard data structure for equipment information, while Sparkplug is the standard data structure specification for MQTT.
Most plants will have a mix of both, with older equipment connecting to an OPC-UA server that is bridged to an MQTT broker
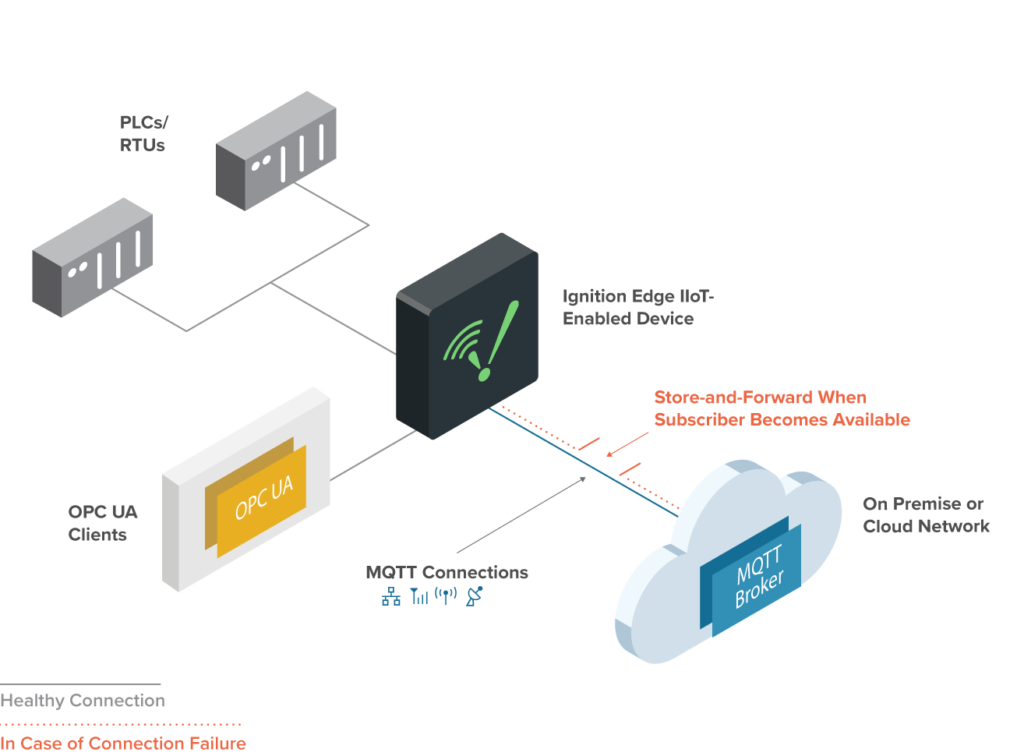
OPC-UA MQTT Bridge – Source: Inductive Automation
AWS
AWS IoT Sitewise Edge provides an MQTT gateway and has out-of-the-box support for OPC-UA to MQTT transformation. AWS Sitewise Edge is great to monitor devices on location, and run/visualize simple analytics. Sitewise Edge gateway then copies the data to the cloud where it can be processed by AWS IoT Core, and bridged to other systems. Downstream systems can be AWS IoT services, other AWS services like Kinesis, S3, Quicksight, etc. or non-AWS products like Kafka, Spark, EMR, Elasticsearch, and so on. Sitewise Edge is a software product which can be deployed on AWS outpost which we’re going to discuss later, or existing infrastructure, bare-metal or virtualized environment.
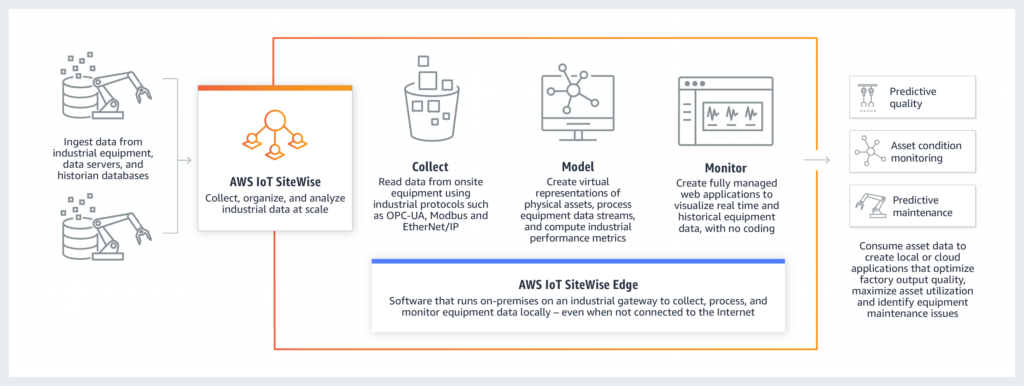
AWS Sitewise Edge – Source: AWS
Azure
Azure IoT Edge edge is the equivalent of AWS Sitewise for Microsoft. IoT Edge ties directly into Azure Iot Hub to make the data available in Azure cloud, which can then be processed using the whole gamut of Azure services like Stream Analytics, Functions, Event Hub, etc

Azure IoT Edge – Source: Azure
Self-Managed
You can also run your own OPC-UA & MQTT broker at the edge, in one of the compute options we’ll discuss down below, but you will be responsible for transferring that data to the cloud. RedHat AMQ, Eclipse Mosquitto, HiveMQ are common MQTT brokers with various degrees of sophistication. Red Hat Fuse, part of the Red Hat Integration suite, can also be used to set up an OPC-UA server if you’re not already using an off-the-shelf solution like Inductive Automation’s Ignition.
This is a great option if you’re just getting started and want to quickly prototype, since they all have trial versions, and/or are just plain free, open-source solutions. HiveMQ and Mosquitto are pure MQTT, while Red Hat Integration’s MQTT implementation is more raw, but offers a much broader range of capabilities beyond MQTT. You can’t go wrong with that option, it will scale really well, you’ll have a lot more flexibility, no vendor lock-in, but there is some assembly required.
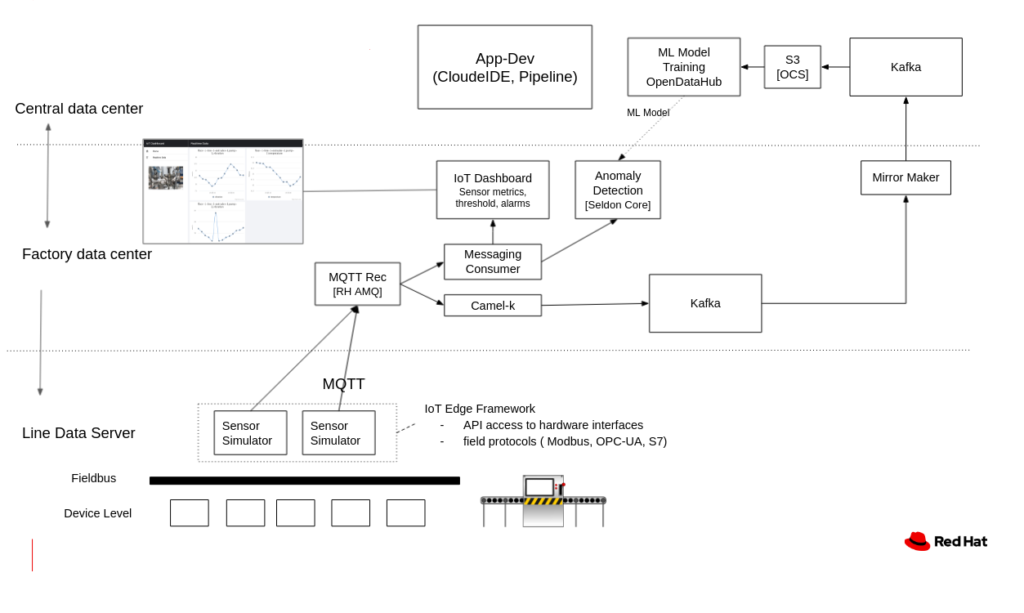
Self-managed MQTT/Kafka Stack – Source: RedHat
Streaming Data
In order to process the data for analytics, error detection, ML in general, etc we need to move it into a more suitable messaging system. The most common solution for that kind of workload is Kafka, and most analytics tools already know how to consume data from it. Kafka also supports replication between sites so it’s a great option to move data between sites and to the cloud.
If you’re using Sitewise edge or Azure Edge and you don’t need Kafka on the edge, the MQTT data will automatically be transmitted for you to the cloud (AWS IoT Core & Azure IoT Hub). You can then send that data your cloud hosted Kafka cluster if so desired (and you definitely should).

If you’re running your own MQTT broker, you can use MQTT replication to the cloud in some instances (Mosquitto Mirroring, HiveMQ Replication), but a better option is to use Kafka and leverage the mirroring feature.
Kafka implementations are plenty, RedHat AMQ Streams, part of the RedHat Integration suite, Strimzi for Kubernetes and Confluent Kafka are the most recognized vendors. Neither AWS nor Azure have managed Kafka products at the edge, but have other – native – ways to run analytics (Kinesis, Event Hub, etc), but more on that later.
Compute Options
Next we need to run workloads at the edge to process the data. Again we’ll have 3 options for the infrastructure setup, and many options to deploy applications to that infrastructure.
AWS
If you don’t have an existing compute infrastructure at the edge or if you’re trying to extend your existing AWS footprint to edge locations, the easier way is definitely AWS Outpost. Outpost are physical AWS servers that you run at your location, which come pre-configure with AWS services similar to the ones running in the AWS cloud, and seamlessly integrate with your existing AWS Cloud. Think of it as a private region with some limitations.
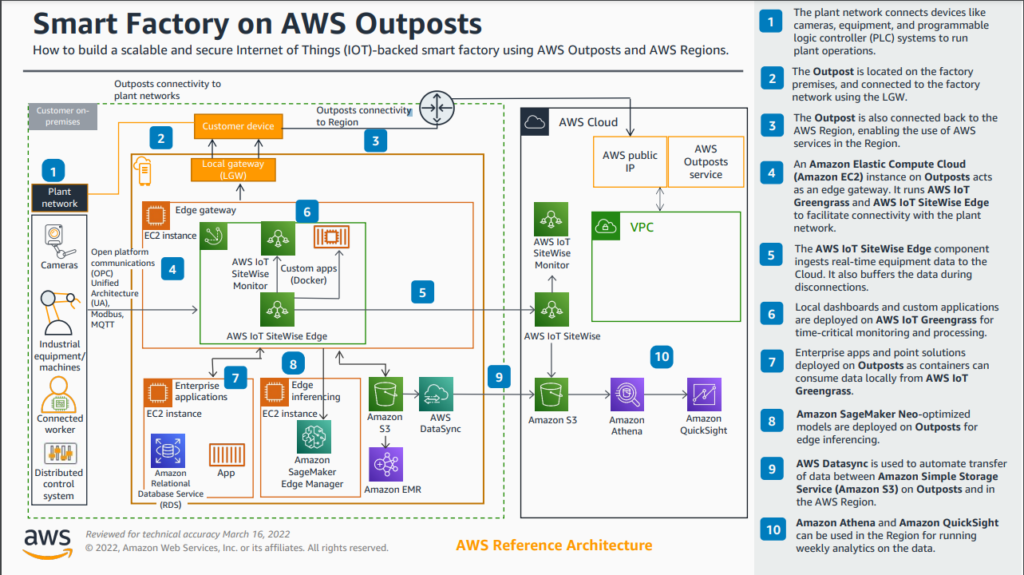
Edge Deployment with AWS Outpost – Source: AWS
Sitewise Edge can be deployed directly on Outpost servers as a turnkey solution for basic analytics on location. You can pair it with Wavelength for sites without existing internet connection, going over 5G networks.
AWS Snowball Edge is another hardware option more suitable for rough environments, remote sites without connection when you want to process the data locally and eventually move the data physically into the cloud (and I mean physically, as in sending the device back to AWS so they can copy the storage)
Outpost can locally run AWS services like S3, ECS, EKS, RDS, Elasticache, EMR, EBS volumes and more
You can also run AWS IoT Greengrass on both devices and use it to run Lambda functions and Kinesis Firehose.
This is a cool article about running Confluent Kafka on Snowball devices: https://www.confluent.io/blog/deploy-kafka-on-edge-with-confluent-on-aws-snowball/
Azure

Stack Edge is the Azure counterpart to AWS Outpost, with the mini-series for use cases similar to AWS Snowball. Again, here, seamless integration with your existing Azure cloud. Azure Stack Hub can run Azure services locally, essentially creating an Azure region at your site.
IoT Edge is the runtime, similar to AWS Greengrass, with IoT specific features. Azure services like Azure Functions, Azure Stream Analytics, and Azure Machine Learning can all be run on-premises via Azure IoT Edge.
Kubernetes (on bare-metal or vms)
Of course both options above are great if you’re already familiar and/or committed to a cloud provider and using the cloud provider’s native services. If you’re not, the ramp-up time can be a little intimidating, and even as a seasoned AWS architect, making sense of how to setup all the components at the edge is not straight forward.
An easier first step at the edge, whether you have existing compute infrastructure or not, is to use your own servers and deploy Kubernetes. If you’re already familiar with Kubernetes it’s of course a lot easier. If you’re starting from scratch, with no prior knowledge of Kubernetes or cloud providers’ edge solutions, I’m honestly not sure which one would be quicker to implement.
For Kubernetes, Red Hat Openshift is a great option. Red Hat suite of products has pretty much everything you need to build a solid edge solution in just a few clicks, through the OperatorHub. Red Hat integration provides MQTT, Kafka, runtimes for your message processing microservices and Open Data Hub for AI/ML. Red Hat published a blueprint for industrial edge to get you started: https://redhat-gitops-patterns.io/industrial-edge/
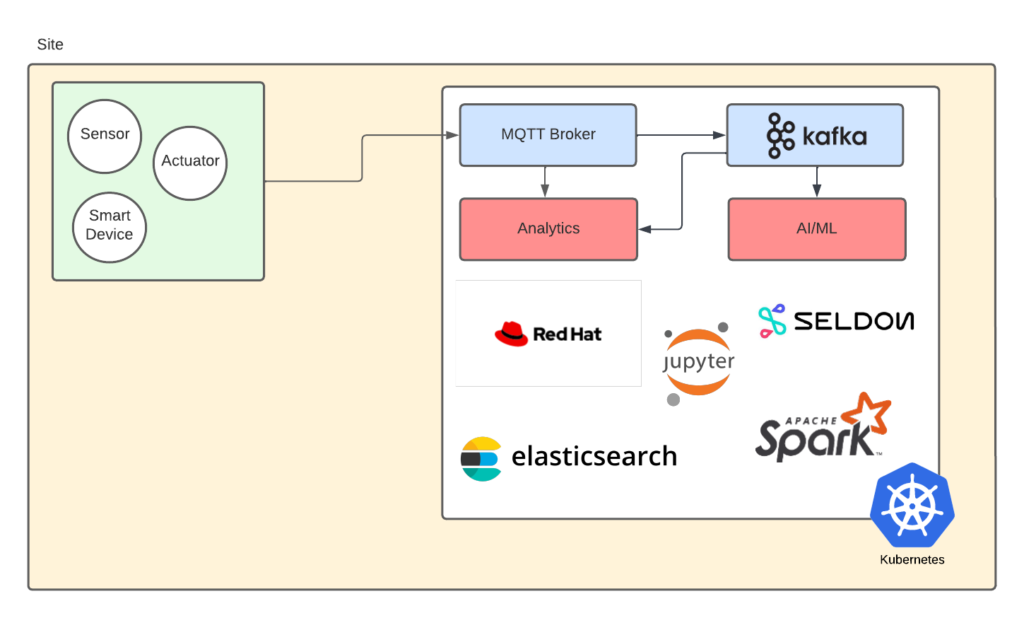
Edge IIoT on Kubernetes
All 3 options have the ability to run Kubernetes at the edge: AWS EKS, Azure AKS or plain Kubernetes (which I don’t recommend), or Openshift (best). A big advantage of using Openshift is the consistent experience and processes across all environments, including multi-cloud. GitOps is a very easy and powerful way to manage large number of clusters at scale and Red Hat Advanced Cluster Manager can be use to further enhance that experience.
Consider the complexity of keeping sites in sync when using AWS or Azure native services at the edge, in terms of applications deployment, architecture changes, etc. at scale. ARM and Cloudformation are available at the edge but you’re not likely to be able to re-use your existing CI/CD process. This is not the case for Kubernetes though, edge and cloud clusters are treated exactly the same way thanks to GitOps.
If you go with Openshift, the integration to the cloud is not seamless. AWS ROSA and Azure ARO are not currently supported on Outpost and Stack Edge so you’re responsible for setting up the cluster, securing the connection to the cloud (VPN) and replicating the data (Kafka Mirroring) to the cloud… so, as always, trade-offs have to be considered carefully.
Conclusion
There is no shortage of options when it comes to implementing edge solutions. All the major cloud providers cover most standard needs, end-to-end data pipelines with native services, even pre-configured server racks that you can just drop into your existing infrastructure. These allow you to easily extend your existing cloud architecture in physical locations. You can also bring your own hardware and software. Red Hat Integration running on Openshift, or the recently release Microshift running on edge optimized Linux is a very powerful and cost effective solution. There is no right or wrong choice here, you just have to consider the effort, cost & timing and find the solution with the best ROI.
Stay tuned for the next part in this series in which we’ll run through the Red Hat IIoT demo and look at what else we can build on top of that foundation.