
What is Machine Learning?
Machine learning means predicting outcomes using artificial intelligence based on previous data patterns. It is a computer program that can learn and adapt new data without human involvement.
Machine learning is a subset of artificial intelligence (AI), and it’s the study of algorithms that gives computers the ability to learn and make decisions based on data and not form explicit instruction.
If we talk about an operating system, we need to know the program and the process as the program and the code may change what the process will do. If your program needs specific data, the process you’re running will go to your hard drive to get the data it needs.
A popular example is learning to predict whether an email is spam or not by reading many different emails of these two types.
We typically differentiate between three types of machine learning:
1) Supervised Learning.
2) Unsupervised Learning.
3) Reinforcement Learning.
Supervised Learning
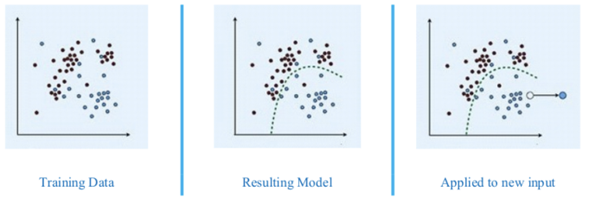
Source by – Google
Fig 1. The Working of Supervised Learning
Supervised learning uses a training data set to teach models to yield the desired output. Supervised learning solves two significant problems, regression and classification.
Unsupervised Learning
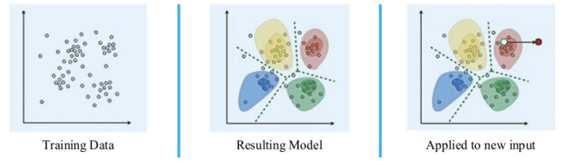
Source by – Google
Fig 2. The Working of Unsupervised Learning
Unsupervised learning identifies clusters without prior knowledge of class labels for input data while training. The input data is assigned to a particular cluster by the model during the testing phase. UL comes up with clusters based on the most frequent patterns at the end of each training step. UL is mainly used in clustering and dimensionality reduction.
Reinforcement Learning
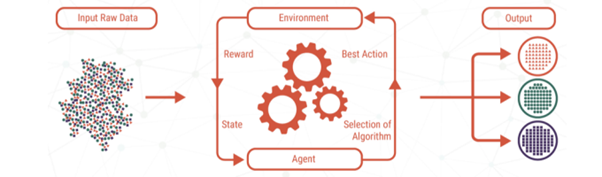
Source by – Google
Fig 3. The Working of Reinforcement Learning
Reinforcement Learning involves interactions with the environment. This technique defines the model that changes the environment’s behavior based on actions. The rewarding approach means the choice of optimal action. The learning environment keeps rewarding each action taken with a score. The optimal transition is based on these rewards awarded.
Uses Cases of Machine Learning
Machine learning can be used in various sectors like healthcare, financial services, sales and marketing, security, etc.
1. Financial Monitoring
Machine learning algorithms can be used to significantly improve network security. Data scientists are constantly working on training programs to detect flags such as money laundering strategies, which can be prevented by financial vigilance. The future holds high potential for machine learning technology that empowers the most advanced cybersecurity networks.
2. Identifying spam
If it weren’t for machine learning, our inboxes would be filled with spam or unsolicited emails. Consider the undertaking to delete those large amounts of unwanted emails. No one has time to do that. Not to mention the security risks found in such emails. Therefore, email providers use machine learning to filter spam automatically. Neural networks can select spam emails successfully based on standard features identified in the sender content and title.
3. Making Product Recommendations
A recommendation program is a general business learning app for a business. Used for mobile and web applications, entertainment platforms (such as Netflix and Google Play), e-commerce websites (such as Amazon and eBay), and search engines.
Machine learning algorithms record various parameters and behavioral data, including browsing history, context data (device, language, and location), item details (category, price), purchase, page views, item views, clicks, etc., to make recommendations.
This, in turn, enables businesses to increase profits, increase user interaction, increase traffic, and reduce churn levels.
4. Data Collection
One of the most critical responsibilities of a physician is to record a patient’s medical history correctly. This can often be challenging, as the patient is not a doctor and does not always know what information is worth disclosing.
Using a study machine in healthcare management, healthcare professionals can determine the most appropriate questions to ask a patient based on various indications. This will help gather relevant data and, at the same time, get the most accurate forecasts.
5. Health Research
Medical research and trials are expensive and lengthy procedures. There is a good reason for this – new drugs and medical procedures must be ensured before they are widely used. However, there are cases where the solution needs to be released quickly, such as with the COVID-19 vaccine.
Fortunately, there is a way to shorten the process with the help of machine learning algorithms. It can determine the best sample, collect additional data points, analyze continuous data from study participants, and minimize data-based errors.
How can we use machine learning in our life or predict based on previous data?
Let’s take an example of a salary dataset based on years of experience. The formula to calculate the salary of a person in 4.5 years will be: y = c + wx
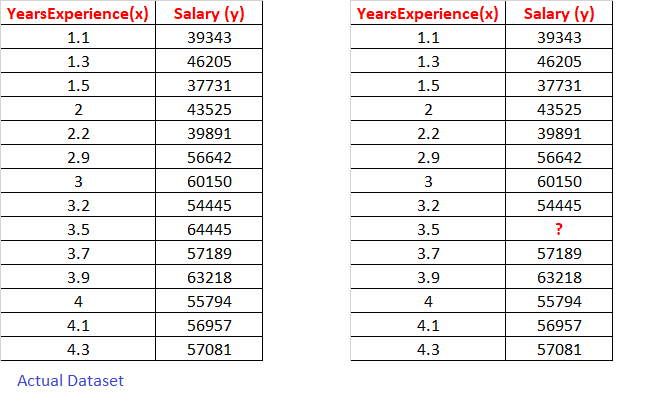
Here we will train our machine learning model by importing past data. After successfully training our model, we will test whether it provides an accurate salary for 3.5 years of work experience. We are importing Pandas Library for our prediction.
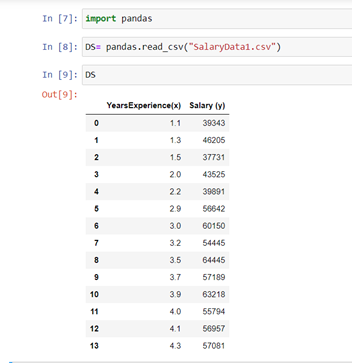
Here ds is our variable in which we are storing our dataset, and “.info()” is our function that gives information about the variable.
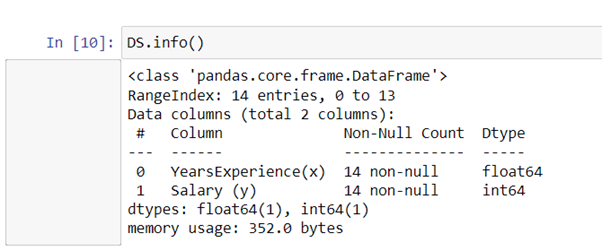
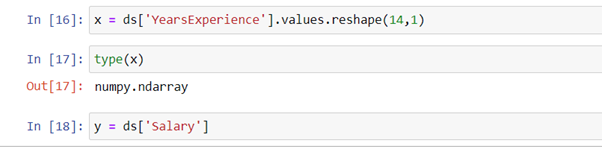
Here in our dataset “YearExperience” column will decide the salary, so we are putting this column in some variable, i.e., x., and the “Salary” column in some variable, i.e., y. We have reshaped the values because we have to convert our model into a 2d array, so we function “.values” that will make our x variable into numpyarray.
We have imported sklearn module to use the “LinearRegression” function, and we have stored this function into a variable “model.”

We can confirm that our model is trained successfully by this “model.coef_” function.

Now we will do a sample test that our model is predicting the salary

The actual salary for 3.5 years is $64,445, but our model predicted it to be $56,454. Because our model prediction/accuracy depends upon how much historical data we provide to the model, T will never be 100% accurate.
Now, if we want to calculate our model’s accuracy, we can simply divide the predicted result by the actual result and multiply it by 100.

So, here our model has trained with 87% accuracy. In the future, if we provide more historical data, then our model accuracy will increase.
This article was written by Rizwan Pathan.