
Why Azure Data Factory?
Nowadays, the data our customer’s applications generate is increasingly exponential, especially if data is coming from several different products. Organizations have data of several types located in the cloud and on-premises, in structured, unstructured, and semi-structured formats all arriving at different time-frequency and speeds. It will be a critical task to analyze and store all this data. Azure Data Factory (ADF) is a cloud-based data integration service that exactly solves such complex scenarios.
ADF first stores data with the help of a data lake storage. Once it is stored, data is analyzed, then with the help of pipelines, ADF transforms the data to be organized for publishing. Once data is published, we can visualize the data with the help of applications like Power BI, Tableau.
For a more in-depth look at ADF and its basic functions, please check out my colleague’s blog post here.
Log Pipeline Executions to File in Azure Data Factory
Data integration solutions are complex with many moving parts and one of the major things that our customers want is to make sure they are able to monitor their data integration workflows or pipelines. However, Data Factory Monitor only stores data of pipeline run for 45 days with very limited information. But with log pipeline executions, we can store custom log data in Azure Data Lake Storage (ADLS) for a longer time with the help of query.
How to create CSV log file in Azure Data Lake Store.
For demonstration purposes, I have already created a pipeline of copy tables activity which will copy data from one folder to another in a container of ADLS.
Now we will see how the copy data activity will generate custom logs in the .csv file. We will begin with adding copy data activity next to copy-tables in canvas.
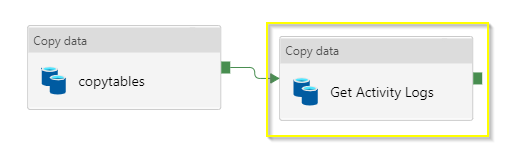
For the source dataset, as we need to define query in the source of copy data activity, I will select dataset as on-prem SQL Server by selecting linked service of on-prem SQL server.

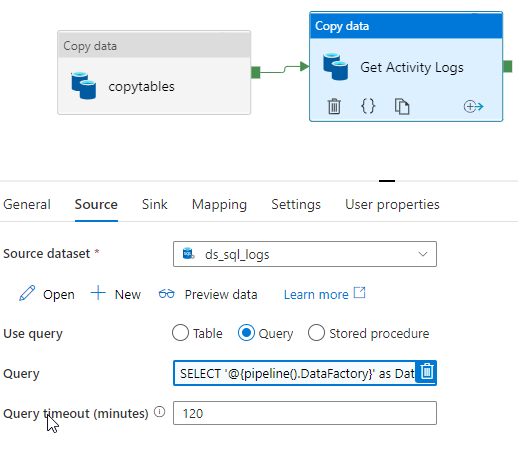
After creating the source dataset, I will add a query to the source. This query will contain a pipeline system variable and other metrics that I can retrieve on each individual task.
Below is the current list of pipeline system variables.
@pipeline().DataFactory – Name of the data factory
@pipeline().Pipeline – Name of the pipeline
@pipeline().RunId – ID of the pipeline run
@pipeline().TriggerType – Type of the trigger that invoked the pipeline (Manual, Scheduled)
@pipeline().TriggerName – Name of the trigger that invokes the pipeline
@pipeline().TriggerTime – Time when the trigger invoked the pipeline.

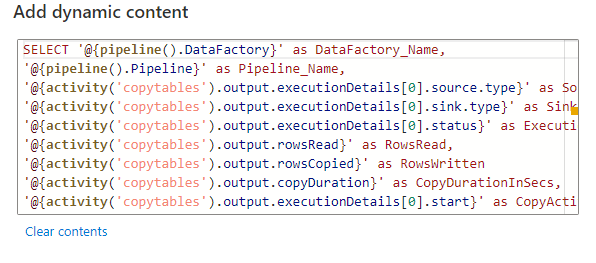
Query –
SELECT ‘@{pipeline().DataFactory}’ as DataFactory_Name,
‘@{pipeline().Pipeline}’ as Pipeline_Name,
‘@{activity(‘copytables’).output.executionDetails[0].source.type}’ as Source_Type,
‘@{activity(‘copytables’).output.executionDetails[0].sink.type}’ as Sink_Type,
‘@{activity(‘copytables’).output.executionDetails[0].status}’ as Execution_Status,
‘@{activity(‘copytables’).output.rowsRead}’ as RowsRead,
‘@{activity(‘copytables’).output.rowsCopied}’ as RowsWritten
‘@{activity(‘copytables’).output.copyDuration}’ as CopyDurationInSecs,
‘@{activity(‘copytables’).output.executionDetails[0].start}’ as CopyActivity_Start_Time,
‘@{utcnow()}’ as CopyActivity_End_Time,
‘@{pipeline().RunId}’ as RunId,
‘@{pipeline().TriggerType}’ as TriggerType,
‘@{pipeline().TriggerName}’ as TriggerName,
‘@{pipeline().TriggerTime}’ as TriggerTime
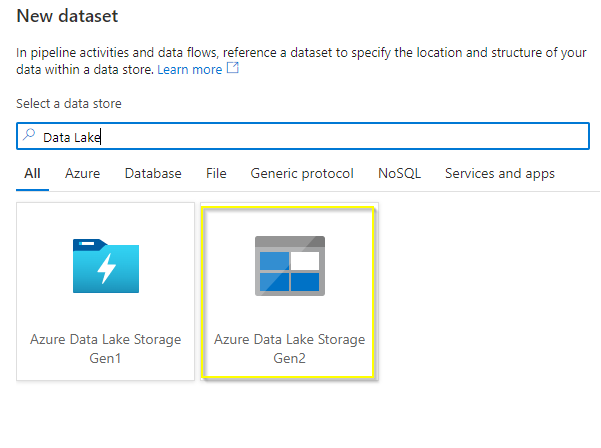
The above query will write the events information to a .CSV file. For that, we must define a sink dataset which will create a directory in ADLS container and CSV log file. Below snapshot shows you that I have selected the dataset type of Azure Data Lake Store Gen 2 and file format as .CSV.
I have used below the parameterized path that will make sure that the log file is generated in the correct folder structure with the proper file name.
Dynamic Content in Filename –
@concat(formatDateTime(convertTimeZone(utcnow(),’UTC’,’Central Standard Time’),’dd’),’/’,item().filename,’_’,formatDateTime(convertTimeZone(utcnow(),’UTC’,’Central Standard Time’),’dd-MM-yy_hh-mm-ss’),’_log’)
With this we are done with the configuration of log pipeline, after I save the pipeline, I need to publish it and run my pipeline. Now I can see the log file generated in ADLS container.
After downloading the file, we can see that as per our query all the output is populated in the.CSV file.

So, in this way we have configured the log pipeline with the help copy activity in ADF. The main advantage of configuring the log pipeline is we can get custom event’s output as data in .CSV file which will help a customer check the Execution status, Rows read, and rows written, etc.
Why Perficient?
Our more than 20 years of data experience across industries gives us a deep understanding of current data trends. As an award-winning, Gold-Certified Microsoft partner and one of just a handful of National Solution Providers, we are a recognized cloud expert with years of experience helping enterprises make the most out of the Microsoft cloud.
Ready to bring your data together to take advantage of advanced analytics with Azure? Contact our team about this solution.
An immensely informative article!!👌
I did have knowledge of Log Pipeline Executions to File in Azure Data Factory but never before did I understand this much about it. Thanks for putting together all the important information to be known about the system as a whole.
Will surely keep this in mind!!
Many, many congratulations Rohit, for this gem of an informative blog-post!! 😊👍💐
Looking forward to reading many more such articles from you in future.
All the best!
Thank you for the informative blog Rohit. Great Work !
Awesome!! Blog and Very Good demonstration for Log Pipeline in ADF. Surely this will going to help me and other as well in their tasks. Thanks Rohit for this informative blog!!
Really happy to see ur blog Rohit. It will help many ones, good going rohit keep it up. Best wishes☺
Great👍👍
Amazing write-up, Rohit.
Looking forward for more such informative blogs.😊
Much Informative blogs, good job. All the best !
Very informative… Thanks
Amazing Article!!
Thanks &
All the Best Rohit!
Awesome rohit 👍Happy to see your Blog.
Keep it up and best wishes for u
Great post Rohit! Keep it up! May you reach every height of success!😇
Very well done👍 good job… Sure it will help me a lot in my upcoming project… Keep it up !! All the best!
Nice Article! Enough though I am not very aware of Azure I found it really informative.
Very nice and informative article!! Thanks and All the best!!!
Nice and Informative👍👍
Nicely written.. Good going… Keep it up👍
Good job Rohit ….well done and much informative article. All the best 👍
Very well written. Looking forward for more such good work. Well done Rohit. 😊
Great Article and Well written with example and screenshot!!
Can we store that logs into a database rather than excel?
Nice blog, its very helpful to us.