Edit: Part 3 using Mahout here
In my previous post I described the basics of HDInsight on Windows Azure and an example of what a Hadoop cluster can do for you.
Without further delay, lets build a cluster! If you don’t already have a Windows Azure account go here and sign up (it’s free!!)
Setup
Login to your Azure portal and you will have a dashboard similar to this:

If HDInsight is not initially on the dashboard simply add it by going here and selecting “Try it now” under “Windows Azure HDInsight Preview”. After installing HDInsight should now appear on your dashboard.
To create a cluster select HDInsight; upon clicking “Create an HDInsight Cluster” you will be presented with the following screen.
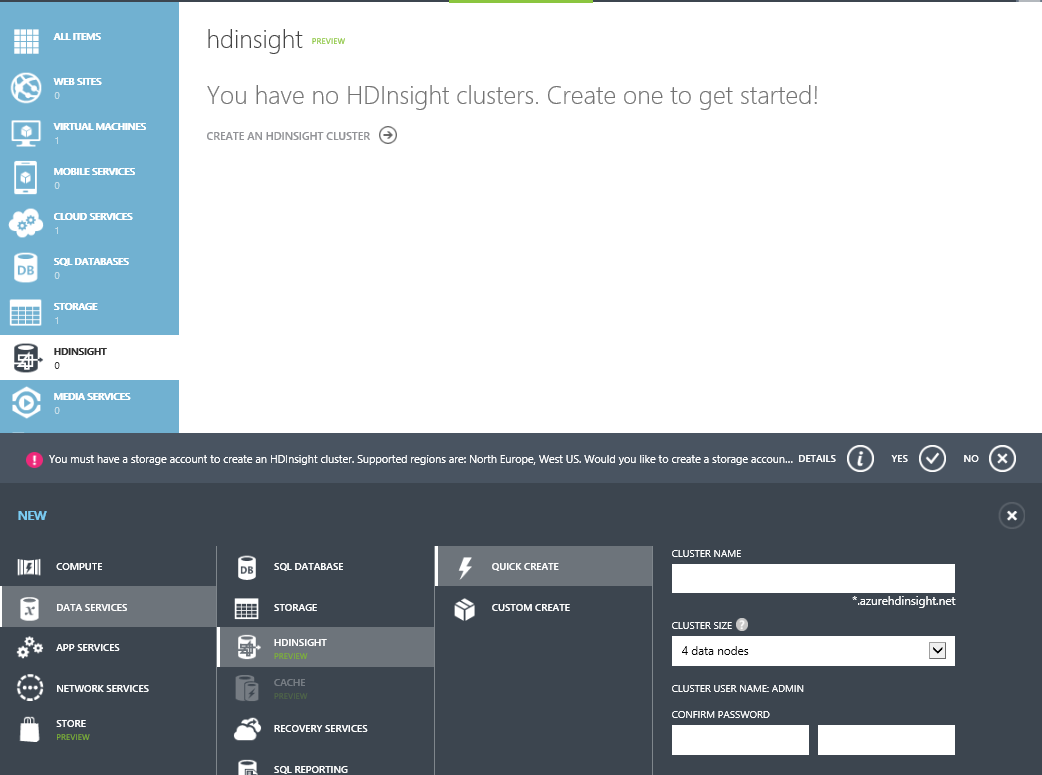
Before you can proceed with the cluster creation you must create a storage account for the cluster. The storage account must be located in the West US, or North Europe. Select “Yes” from the dialog and you will be guided through the creation of a new storage account.

After the storage account is created select “Create an HDInsight Cluster” once again. Give your cluster a unique name and select the cluster size. Notice your storage account was automatically associated with the cluster. Click “Create HDInsight cluster” and the creation process will begin. For a 4 node cluster the process will take approximately 10 minutes.
A Brief Tour

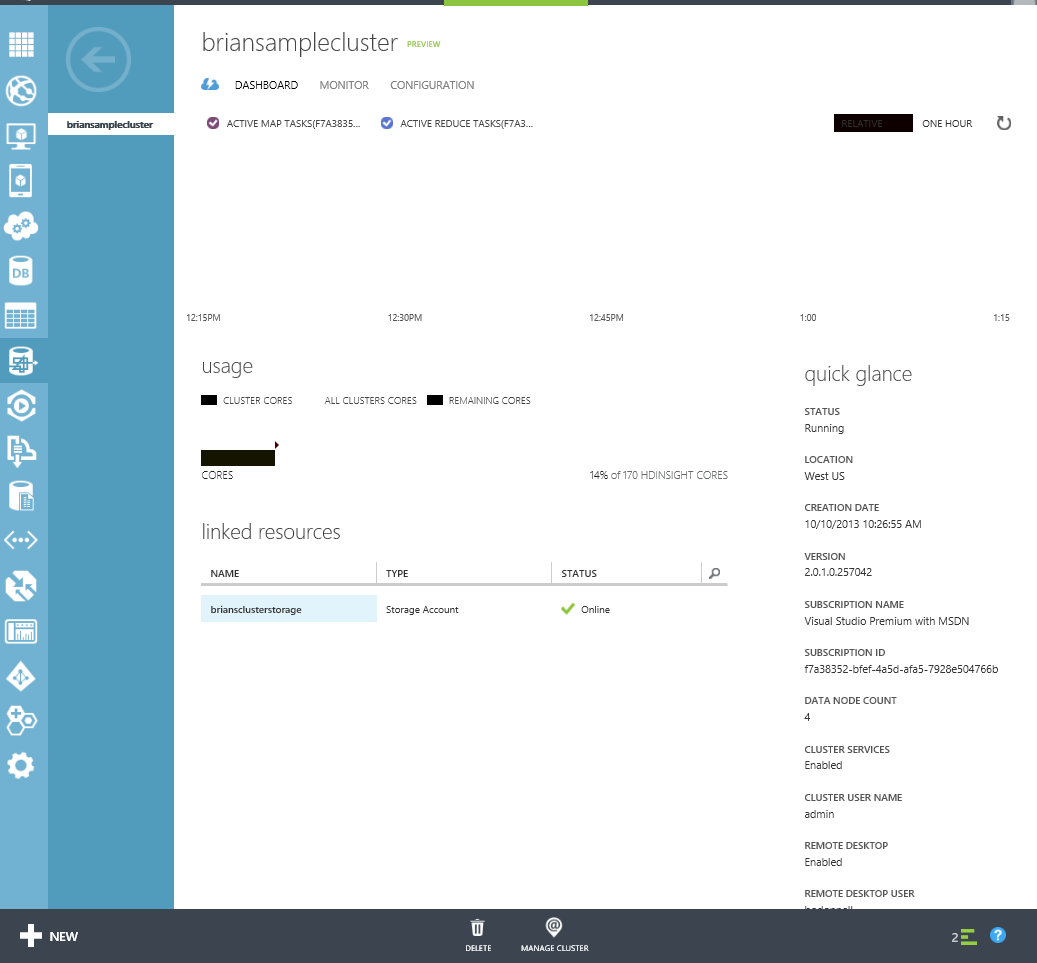
Once the cluster has completed you will see the cluster available for you. Clicking on it will bring you to the cluster dashboard. Take note of the right hand column, it has several key pieces of information that will help while becoming familiar with the environment. Two things to point out are the following:
- As of version 2.0, Remote Desktop to the head node has been disabled by default. You can enable Remote Desktop by clicking on the cluster dashboard and at the bottom of the screen select “Enable Remote Desktop”.
- When setting up the cluster you had to specify a password of at least 10 character long but there was no username associated with it. Note the username is admin. This is the username that will be used when running Map Reduce jobs over Hadoop. It is wise to user a different username / password combination when enabling Remote Desktop to the head node.
Running your first Map Reduce
If you are unfamiliar with Map Reduce please visit the Hadoop documentation on Map Reduce for more information. In short, Map Reduce is a way to filter and summarize large amounts of data. It is used most efficiently when distributed and managed among several different nodes in a cluster.
HDInsight makes it extremely easy to use Hadoop and Map Reduce without requiring much knowledge about the underlying systems. To get started open the HDInsight cluster management tool by clicking on “Manage Cluster” at the bottom of your screen.

***Note: The cluster management tool will be discontinued in future version of HDInsight. Many of the tools used here will be migrated to the Cluster Dashboard within the Azure portal. There are also PowerShell tools in development to deploy Map Reduce and other Hadoop jobs. The alpha version can be found @ https://hadoopsdk.codeplex.com/ ***
We are going to use the Interactive Console to run our sample job. The Interactive console is wonderful! Its a JavaScript console that combines Hadoop File System commands (HDFS) along with JavaScript “shell” commands. To get started select the first tile “Interactive Console”.
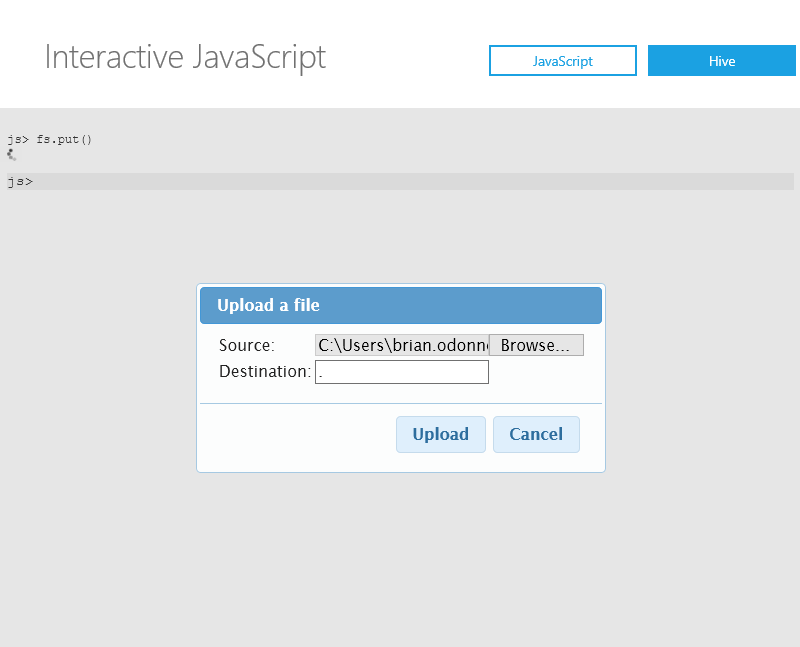
The first command you will type is: fs.put()
Source Name: http://isoprodstore.blob.core.windows.net/isotopectp/examples/WordCount.js
Destination: /example/data/gutenberg
Once uploaded, view your directory contents by entering: #ls /example/data/gutenberg
(for those familiar with bash or PowerShell this should look very familiar)
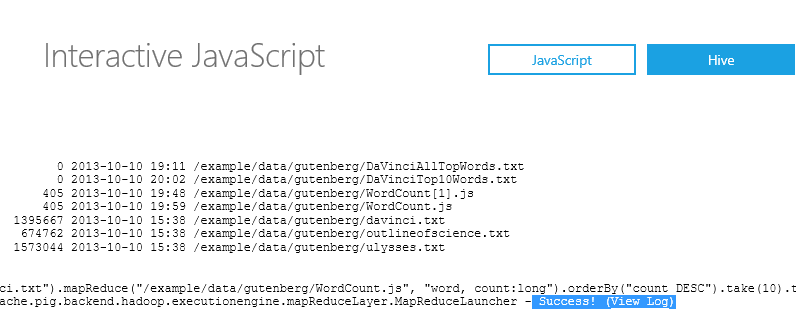
You should see something similar to the following

To view a printout of the WordCount.js file you just uploaded you can type: #cat /example/data/gutenberg/WordCount.js
Next we will run the Map Reduce job. Type in, or copy/paste this command:
pig.from("/example/data/gutenberg/davinci.txt").mapReduce("/example/data/gutenberg/WordCount.js", "word, count:long").orderBy("count DESC").take(10).to("/example/data/gutenberg/DaVinciTopTenWords.txt")
Pig? What is Pig?!? Pig is another Apache platform primarily for use with large datasets. Pig’s language (conveniently referred to as Pig Latin) is commonly used with Hadoop due to the large datasets Hadoop can traverse.
If your job was successful you should be able to scroll to the right and view the log.
The last step is visualizing the data. On the next line enter: file = fs.read(“example/data/gutenberg/DavinciTopTenWords.txt”)
We then want to parse the file and put it into a data object to be consumed by a graphing utility inside the Interactive Console: data = parse(file.data, “word, count:long”)
Finally, lets print the graph: graph.bar(data)
You should see a printout similar to this:
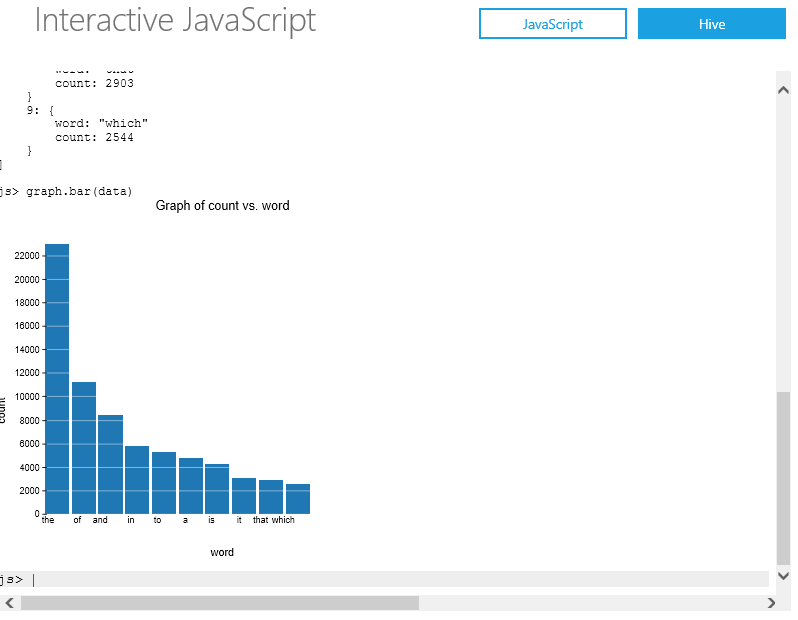
Your done! Congrats!