Metadata Extraction: IDMC vs. PowerCenter
When we talk about metadata extraction, IDMC (Intelligent Data Management Cloud) can be trickier than PowerCenter. Let’s see why.
In PowerCenter, all metadata is stored in a local database. This setup lets us use SQL queries to get data quickly and easily. It’s simple and efficient.
In contrast, IDMC relies on the IICS Cloud Repository for metadata storage. This means we have to use APIs to get the data we need. While this method works well, it can be more complicated. The data comes back in JSON format. JSON is flexible, but it can be hard to read at first glance.
To make it easier to understand, we convert the JSON data into a table format. We use a tool called jq to help with this. jq allows us to change JSON data into CSV or table formats. This makes the data clearer and easier to analyze.
In this section, we will explore jq. jq is a command-line tool that helps you work with JSON data easily. It lets you parse, filter, and change JSON in a simple and clear way. With jq, you can quickly access specific parts of a JSON file, making it easier to work with large datasets. This tool is particularly useful for developers and data analysts who need to process JSON data from APIs or other sources, as it simplifies complex data structures into manageable formats.
For instance, if the requirement is to gather Succeeded Taskflow details, this involves two main processes. First, you’ll run the IICS APIs to gather the necessary data. Once you have that data, the next step is to execute a jq query to pull out the specific results. Let’s explore two methods in detail.
Extracting Metadata via Postman and jq:-
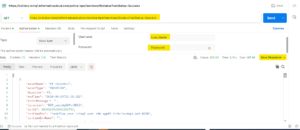
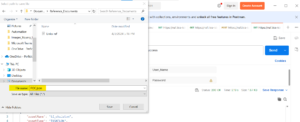
Step 2:
Construct a jq query to extract the specific details from the JSON file. This will allow you to filter and manipulate the data effectively.
Windows:- (echo Taskflow_Name,Start_Time,End_Time & jq -r ".[] | [.assetName, .startTime, .endTime] | @csv" C:\Users\christon.rameshjason\Documents\Reference_Documents\POC.json) > C:\Users\christon.rameshjason\Documents\Reference_Documents\Final_results.csv Linux:- jq -r '["Taskflow_Name","Start_Time","End_Time"],(.[] | [.assetName, .startTime, .endTime]) | @csv' /opt/informatica/test/POC.json > /opt/informatica/test/Final_results.csv
Step 3:
To proceed, run the jq query in the Command Prompt or Terminal. Upon successful execution, the results will be saved in CSV file format, providing a structured way to analyze the data.

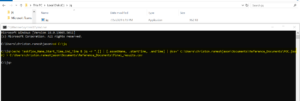
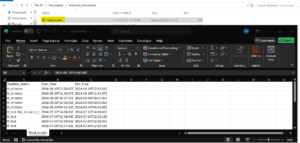
Extracting Metadata via Command Prompt and jq:-
Step 1:
Formulate a cURL command that utilizes IICS APIs to access metadata from the IICS Cloud repository. This command will allow you to access essential information stored in the cloud.
Windows and Linux:- curl -s -L -X GET -u USER_NAME:PASSWORD "https://<BASE_URL>/active-bpel/services/tf/status?runStatus=Success" -H "Accept: application/json"
Step 2:
Develop a jq query along with cURL to extract the required details from the JSON file. This query will help you isolate the specific data points necessary for your project.
Windows: (curl -s -L -X GET -u USER_NAME:PASSWORD "https://<BASE_URL>/active-bpel/services/tf/status?runStatus=Success" -H "Accept: application/json") | (echo Taskflow_Name,Start_Time,End_Time & jq -r ".[] | [.assetName, .startTime, .endTime] | @csv" C:\Users\christon.rameshjason\Documents\Reference_Documents\POC.json) > C:\Users\christon.rameshjason\Documents\Reference_Documents\Final_results.csv Linux: curl -s -L -X GET -u USER_NAME:PASSWORD "https://<BASE_URL>/active-bpel/services/tf/status?runStatus=Success" -H "Accept: application/json" | jq -r '["Taskflow_Name","Start_Time","End_Time"],(.[] | [.assetName, .startTime, .endTime]) | @csv' /opt/informatica/test/POC.json > /opt/informatica/test/Final_results.csv
Step 3:
Launch the Command Prompt and run the cURL command that includes the jq query. Upon running the query, the results will be saved in CSV format, which is widely used for data handling and can be easily imported into various applications for analysis.
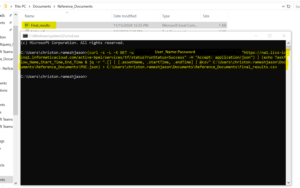
Conclusion
To wrap up, the methods outlined for extracting workflow metadata from IDMC are designed to streamline your workflow, minimizing manual tasks and maximizing productivity. By automating these processes, you can dedicate more energy to strategic analysis rather than tedious data collection. If you need further details about IDMC APIs or jq queries, feel free to drop a comment below!
Reference Links:-
IICS Data Integration REST API – Monitoring taskflow status with the status resource API
jq Download Link – Jq_Download