
Google has been investing heavily in machine learning and its language processing capabilities for quite some time to help improve overall user experience and satisfaction.
In this episode of the award-winning Here’s Why digital marketing video series, Jessica Peck, Senior Analytics Consultant at CVS, joins Eric to discuss what Google’s SMITH algorithm is and why it is an important event for SEO.
Don’t miss a single episode of Here’s Why. Click the subscribe button below to be notified via email each time a new video is published.
Resources
- Google Research Paper – Beyond 512 Tokens: Siamese Multi-depth Transformer-based Hierarchical Encoder for Long-Form Document Matching Research Paper
- Google BERT Update – Digital Marketing Quick Take
- See all of our Here’s Why Videos | Subscribe to our YouTube Channel
Transcript
Eric: Hey, everyone. My name is Eric Enge, and I’m the Principal for the Digital Marketing Solutions business unit here at Perficient. Today, I’m happy to welcome back Jess Peck. She’s been a fixture in the series when she was an employee with us at Perficient as a Marketing Technology Associate. And now she’s a Senior Analytics Consultant at CVS, where she monitors data best practices and QA analytics tagging. Say hi, Jess.
Jess: Hi, everyone.
Eric: It’s been a while, and it’s great to have you back.
Jess: It’s great to be back. I’m really excited to talk to you today about the SMITH Algorithm.
Eric: So, is this another Google algorithm with a person’s name and a clever acronym?
Jess: Yes
Eric: And should marketers, like, drop everything they’re working on to start chasing SMITH?
Jess: No.
Eric: All right. Well, that’s that for this video. Oh, just kidding. So, what is SMITH, and why should we care?
Jess: So, SMITH is a proposed technique model for natural language processing by Google. It’s a lot better at matching longer documents with each other and a lot better at quickly breaking down long texts and understanding how parts of a text relate to itself.
Eric: Yes, it’s a massive jump forward in Google’s language processing capabilities. So, can you explain SMITH?
Jess: Well, I’m going to try and get into it while keeping this video entertaining and not too long. So, let’s see how we do. SMITH stands for Siamese Multi-depth Transformer-based Hierarchical, and that’s the SMITH bit, encoder. And that’s a real mouthful, but it makes sense if we break it down. It’s Siamese, in the sense of two models. It has multiple depths. It’s based on transformers like BERT. And it’s hierarchical, so has different structures basically.

So, let’s talk about the kinds of problems that SMITH is trying to solve. Semantic matching problems can be classified into four different categories based on the length of text, so if one is short, or the other long, or vice versa, or if they’re both short, or both long. So the developers of the SMITH model looked at the work that was being done and found when both texts are long, matching them requires a more thorough understanding of the semantic relationship, like matching patterns between fragments with a long distance between each other.
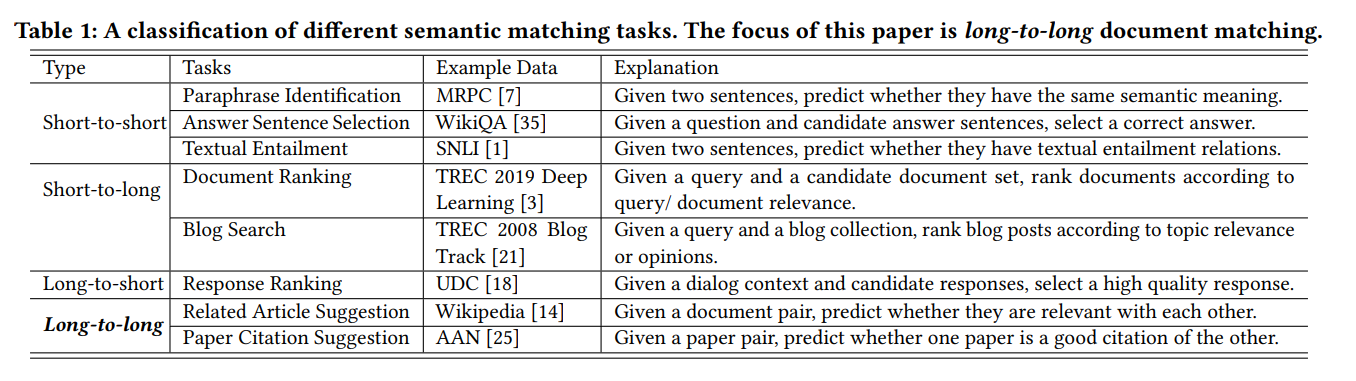
Eric: Right. And long documents contain internal structures, like sections and passages, as well as sentences. And when you’re a person reading a page, the structure of that page is part of the overall meaning of the text, and the machine learning model has to take document structure information into account for better matching performance.
Jess: And, yeah, that’s true. And most practically, because of all of this, machine learning already takes up a lot of memory. But the processing of long texts is way more likely to trigger practical issues like out of TPU or GPU memories, and other things like that, at least without really careful model design. Recurrent Neural Networks or RNNs are bad at longer and bigger tasks. Models like Transformers and BERT are better at this kind of task. But building a Transformer-based long text encoder is difficult, because dealing with memory is tough, and there’s quadratic computational time, which is exactly what it seems like.
Eric: So what does SMITH do to combat this?
Jess: They split the input document into several blocks containing one or more sentences using what they call a Greedy Sentence method. And then the sentence-level Transformers learn the contextual representations for the input tokens in each sentence block. So they, basically, break down the larger content into blocks and then try and understand the relationships between the sentences in those blocks.
The nice things about SMITH is these document representations can be generated independently of each other and then indexed offline before they get served online. And the hierarchical model captures the document’s internal structural information, things like sentence boundaries. And both of these things really help with memory and the understanding of the whole document.
And then thirdly, compared with directly applying Transformers to the whole document, it’s got a kind of two level hierarchy, which includes both sentence- and document-level Transformers, which reduce the quadratic memory problems that we’ve mentioned before and the amount of time complexity by changing the full self-attention on the whole document to several local self-attentions within each sentence block.
Eric: So the sentence-level Transformers capture interactions between tokens within the sentence block, and then the document-level Transformers look at the global interaction between different sentence blocks looking for long distance dependencies?
Jess: Exactly. Because the attention is split between two models, it can cover more ground quickly, and you get a deeper multi-level understanding of the text. So like BERT, SMITH also adopts the unsupervised pre-training and fine tuning paradigm for model training. So they hide or mask randomly selected words and sentence blocks during the training. So if you’ve ever seen like blackout poetry, imagine giving a computer blackout poetry and telling it to guess the rest of the poem.
Eric: It sounds like SMITH is pretty impressive.
Jess: Yep. And it’s going to have impacts on things like neural matching, self-attention models for long text modeling, transformer models and BERT but for longer text. Self-attention models like Transformers and BERT show promising performance on several tasks in natural language processing and information retrieval. There’s also unsupervised language model pre-training, so if you’ve heard of ELMo, GPT, Word2Vec, or BERT, all of these models can be pre-trained by predicting a word or a text span using other words in the same sentence. And this shows more of how that can be used on a bigger scale.
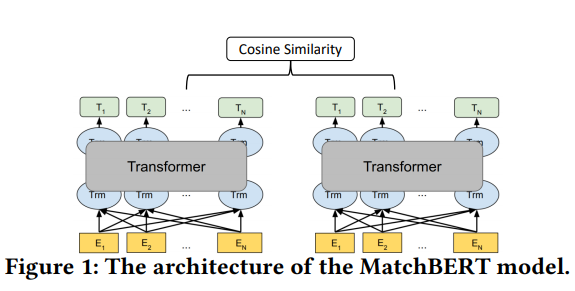
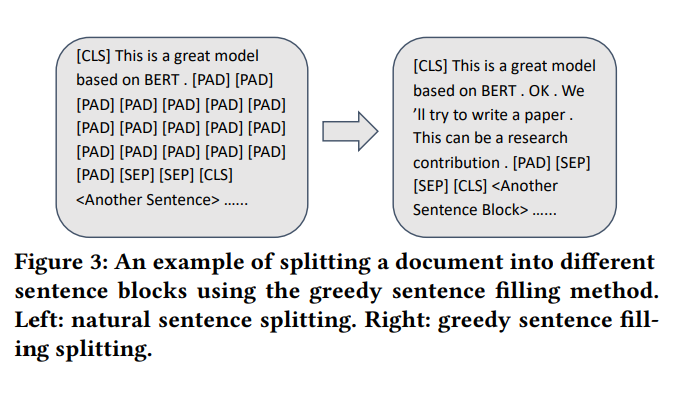
I’m not going to get into the technical details of any of this any more than I already have. But all of these elements are kind of connected with each other and point to some things about the future of search.
Eric: So Google isn’t currently using SMITH in the algorithm, is it?
Jess: No. But I think looking at SMITH can give us some insights into how information retrieval, particularly in Google Search, is going to evolve in the future. So let’s talk about some concepts from this paper that SEO-savvy marketers should focus on.
Eric: Obviously, this paper shows a continued focus from Google on natural language processing, especially for information retrieval, and a further focus on things, entities, and concepts.
Jess: And, yeah, with that, I think it’s worthwhile for technical SEOs and people interested in machine learning to read about and try and understand attention models. Attention just mimics human attention. It enhances important parts of the input data and fades out the rest. And you can see the effects of it in all sorts of machine learning models, from computer vision to image generation, to text generation, and translation. Transformers are another machine learning concept that invested technical SEOs should look at. They’re like Recurrent Neural Networks, and they are in use in SMITH, BERT, and GPT. And we’ve all seen how powerful these language models can be.
Eric: And I think beyond the machine aspect of NLP, Google has continued to invest in understanding natural language and how people speak and query.
Jess: Yeah, it’s another signal that we’re not only moving beyond just text-matching, but getting the machinery to use machine learning in a faster, better, more eloquent way.
Eric: Yeah, the future of search is making sure your site is top-tier, your content is good or excellent, and that you’re providing what your searchers are looking for no matter how they word their query.
Don’t miss a single episode of Here’s Why. Click the subscribe button below to be notified via email each time a new video is published.
See all of our Here’s Why Videos | Subscribe to our YouTube Channel