
HTML has always been the skeleton of the web: fundamental to its function, usually hidden, missing in certain areas, and important not to break. This HTML and SEO guide is written focused semantic SEO and the technical alignment between HTML and content. Structured Data has been a hot topic issue in SEO this year (as it is many years), and while schema is a major element of structured data, proper HTML formatting is as well.
(If you’re interested in this topic, but not necessarily up on HTML, you can read a basic HTML guide here.)
The Philosophy of HTML and Friendly Browsers
Something that separates HTML from other languages is how forgiving it is. (We can have a fun argument about whether or not HTML is just a markup language, or a declarative programming language. For shorthand and simplicity we’ll go to “language” and you can argue with me on Twitter 😊) For example, It doesn’t necessarily throw errors if you forget to close markup—it will just assume you want to keep that markup open until the end of the page, where it will helpfully close the element for you.
An exercise for understanding how the browser interprets what you see is looking at the view-source and inspector side by side. (My favorite tool for this is John Hogg’s view-rendered-source comparing tool.) The view-source shows what the developer wrote, and the inspector shows what the browser interprets out of that, rendering thrown into the mix.
HTML design is kind of a Schrodinger’s art—you know what it looks like in your browser and the browsers you test on, but there are always use cases that you aren’t expecting (have you tested your site on smart fridges, Nintendo DS browsers, or smart watches? Have you tested screen readers, braille displays? Because those are all ways that people interface with the net nowadays. How does your website feel? How does it sound?)
Semantic HTML is great because it provides all different interpreters a baseline for what the content is and what it means, making even the most stripped-down version of your site interpretable by all sorts of devices—and people. This also helps machines of all sorts interpret your web page—social media and smaller crawlers may not render JavaScript, and accessibility devices use semantic anchors to navigate pages.
Back to friendly browsers: because browsers want to help your HTML, this can lead to some weird behaviors that can be surprising and lead to SEO issues. For example, if you forget to close a tag, the browser will close it for you—albeit, perhaps, after you actually wanted the tag to end.
Page Source
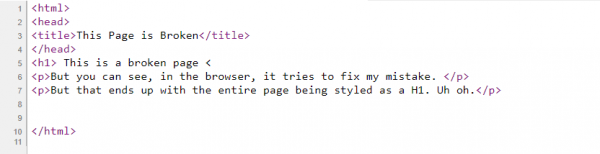
Inspector View
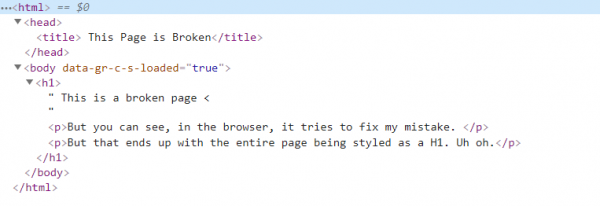
The actual page

The <body> and Semantic HTML
The <body> is where aligning your HTML and your content becomes extremely important.
Semantic elements in the body are a companion to the visual layout of the page. With HTML5, developers will be able to use semantic elements like <article> and <aside> to describe more about the content and how it fits onto the page. There are roughly 100 semantic elements available, and all of them help sculpt machine understanding of content.
While this doesn’t mean you have to go through and match the perfect semantic element to the perfectly crafted content that you’ve written, when structuring your HTML using semantic elements can provide simplicity to you, and will help the people and bots who navigate your site. Outlining your navigation, footer, and other details with semantic elements can be invaluable for screen reader users. On top of this, it can keep your written markup clean and legible – it’s a lot easier to sort through <section>s rather than a thousand <div> tags.
For another example of the importance of semantic HTML– links. Previous Google stated that it does not, cannot, and will not follow or look at links that exist outside proper link attributes. A proper link attribute involves an opening a tag and a href attribute. There’s a reason <span class=”link”>link</span> statements make SEOs shudder in fear. Here Martin Splitt shares a bit more broadly what types of link implementations you shouldn’t use:

H/T to Martin Splitt
Links are how the internet is structured; a link is a connection from one Web resource to another. It’s important to use proper link tags when you’re working with HTML; a link is made up of two anchors (<a> tags) and a direction. The link starts at the source and points to a destination.“
But recently, Gary Illyes said during a bay area search meetup; “I would stay away from <span> links. Not because we can’t understand them, but because it will take us longer to understand them. Whatever requires rendering takes time. ” This is a lot less, how shall we say, stringent than previous statements, and I’d consider it a pretty significant shift.
Another bold shift from Google came from a video John Mueller put out about <h1> tags and how to handle them for SEO and Accessibility. The part that made my eyes bulge slightly was this specific slide:

It makes sense that Google would want to move closer to understanding sites the way that viewers see them, instead of how they’re written—if someone has a title with <h1> tags that is different from something that might be a styled as a title (say, using CSS), so it’d be important for Google to see that discrepancy and read the more accurate version of the page.
However.
HTML can be described as kind of a quantum layout language—You can write HTML as an input but you cannot, necessarily, be sure out what the output is. Users are everywhere, using all sorts of devices and aspect ratios and color-changing extensions and screen readers and more. You can control what you write, but not how your users will see the results.
Semantic HTML is a standard way to tell all these different machines what the different parts of a page mean. And not all these devices will interpret the CSS and JavaScript of a page—they all still rely on semantic elements. On top of this, much like how users can misinterpret a page, I wouldn’t be surprised if Google’s Algorithms are more likely to misinterpret the version of the page without Semantic HTML.
By using the correct elements, you’re giving assistive device users and machines context for those anchors and the text around them, which helps spin more of a semantic web around your content. Even with Google’s ability to interpret your pages without Semantic HTML, it’s still important to understand and implement HTML properly.
The List and Table Advantage

Tables and lists are easy ways for Google and other robots to digest information. Be aware, though; machines are looking for expected behaviors—unexpected behaviors can easily trip them up.
Google SERP listing for “bob animal crossing”
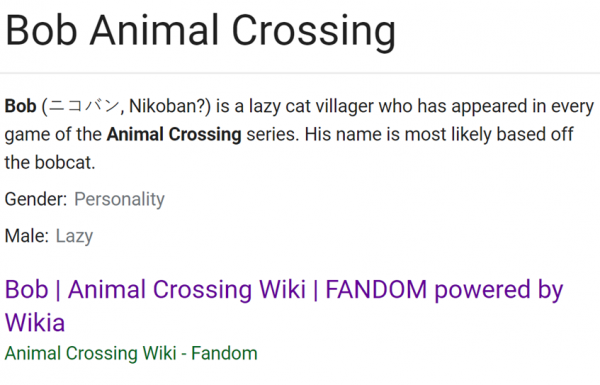
Animal Crossing Wiki table entry.

Google likes to extract data from tables and display them in Knowledge Panels, Explore Panels, Featured Snippets or Rich Snippets. However, when the layout of the table deviates from Google’s assumptions one may end up with results that don’t align with the source information. A table element in HTML is usually made up of a defining <table> tag, and then <tr>, or table row, tags, defining each row; a table header is defined with a <th> tag. Each cell is defined by the <td>, or table data, tag.
In the example above, this table is nested inside another. The cell with “Gender” in it is labeled as a part of a table-row (“tr”) element, and also is as a cell labeled “td” or “table data.” So the snippet interprets Gender as Personality, and Male as Lazy. Google would probably better understand this table if the top row was marked with “th” or “table heading.”
Another interesting thing to note about tables is that browsers (and, presumably, bots) decide whether a table is a data table or a layout table. This is probably a holdover from the time where tables were more commonly used for layouts, rather than nowadays where developers use things like CSS-grid. People used to use tables to set up the layout of their pages, rather than using it for displaying data in a table format. This means machines often have to decide whether you’re looking at a table used for layout or for data. You can use the Accessibility Tree in the Chrome Inspector (right click, or ctrl + shift + I in Chrome) to see if a table is a Layout Table or Data Table.
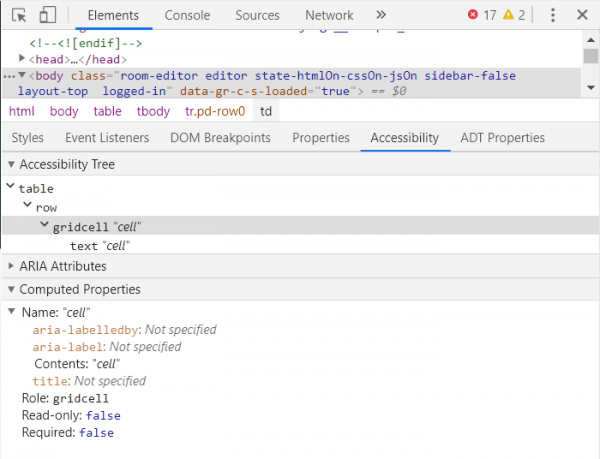

The link above goes to a Codepen page where Paul Duncan runs through several scenarios, noting the kinds of things that Chrome seems to use to calculate whether a table is a data table or layout table. For example, zebra-striping (going back and forth between colors by row) seems to let the browser see a table is to do with data instead of layout. This is important for a few reasons- one is accessibility (screen readers and devices interact with layout tables and data tables differently). But it may also affect SEO—Januka Harshan on twitter noted that their competitors seemed to be picked up more often partially because those competitors used alternating colors. So, there’s a fun test for someone to try out.
Another way to help Google and robots understand data is lists. Google knows that for some types of information the easiest way to make information digestible is through a numbered list.
There are two different types of lists in HTML– <ul>, unordered list, and <ol>, ordered list. Google Featured Snippets tend to show up in four formats; paragraphs, lists, tables, and videos. Lists can be both a great way to convey information rapidly, but also often get cut off by the featured snippet, which can cause more click throughs. Google likes lists for items, steps of processes, tasks, etc.
John Mueller’s explanation shone a light on that. “The reason that kind of content can tend to rank for featured snippets is because it is well organized… They are ranking because the ideas contained in the content is coherent, it is organized and well structured.” Data from our Featured Snippet study backs this up; for some queries, Google prefers bulleted lists. In aggregate, we see <p> tags as the main source of Featured Snippets, but for some spaces the winner is <table> tags.
What’s up with Divs:
When all you have is a framework, everything starts to look like a <div> attribute. A <div> attribute is an empty element; it doesn’t have any semantic meaning. This means you can wrap other elements with <div>s without necessarily affecting anything. You can assign styles to <div>s, populate them using JavaScript, and all sorts of other flexible meanings.
An evolution over the last few years has been the divergence between accessibility/SEO practitioners and web developers. As developers have worked with more JavaScript frameworks, like React, Angular, and Vue, they’ve found that <div> elements are an easy way to insert JavaScript into a page. On the other hand, because <div> elements are empty and mean nothing (a horrible insult for a person but a neutral description of a <div>), accessibility experts and SEOs have shied away from <div>’s. Some even go to the extreme of advocating for 0 <div> elements on any page of a website.
So who’s correct here? Are <div> elements literally the worst thing to come into web development or are they flexible, easy, and good? The truth is the answer is both—when abused they can be terrible, but used correctly they can be really useful. Divs are a neutral element—and because they are neutral, <div> elements can be used all over a page to provide styling, inject JavaScript content (using, for example, d3.js) and giving developers a way to group elements of the page for the purposes of styling. These elements can be used to sculpt a page without forcing screen readers to note every element on that page.
Debugging HTML:
Debugging HTML can be as simple as looking at the page and checking if the appearance matches with your expectations. Comparing the source and the inspector and running your HTML through a HTML validator are other ways you can see if there’s anything wrong with what you’ve developed. Another recommendation I would make for HTML is to actually use a screen reader on your site—you can try JAWS or ZoomText for Windows, or if you’re on a Mac navigate to the Accessibility settings to enable VoiceOver. You can also try and navigate your site using only the keyboard. This can show you the shape of how your HTML affects your content, and since many people are only experiencing your site those ways it’s important to include them in your design.
Talking to the Robots: New Google Developments
HTML is an ever-evolving thing; recently, Google introduced new HTML attributes to help give Googlebot more information about your content. These are almost entirely specific to Search Engine Bots.
Semantic Link Attributes: On September 10th, Google posted about new link elements that could be used to describe nofollow links. A lot of webmasters were wondering how those kinds of attributes might affect their content, and why they should change from nofollow links to include new kinds of attributes like “ugc” or “sponsored.” I think this has some similar benefits to other semantic HTML elements—to semantically describe the links is to give Google more context, which can’t be a bad thing.
Snippet attributes: Google has also introduced more options for snippets, using the robots meta tags (in the head) and a new HTML attribute (data-nosnippet) in the body. This allows webmasters control over what search engines index and display in search results.
HTML Ch-ch-changes
HTML is constantly changing, with new attributes being explored by developers, discussed by the World Wide Web Consortium, and implemented in browsers. Attributes like Native Lazy Loading make difficult web development tasks easier, as well as providing performance and SEO value. Keeping up to date in the HTML space and learning more about HTML also help improve accessibility. Google has said their goal is to make the web a better place for everyone, no matter what their connectivity, device, accessibility concerns, or love of JavaScript frameworks—the baseline of this is semantic HTML.
Even as Google gets better at “seeing” pages as users do, the truth of the matter is that GoogleBot is, itself, a biased user; it cannot read the page the way that every possible user does. It is still a machine, that makes mistakes, with some of the most advanced technology of the world powering it. Even testing and throttling for slower devices does not equal being a user working with those devices. One of the biggest advantages of semantic HTML is it can level the playing field for almost everyone. On top of this, Google is still a machine that makes mistakes; guiding it to your intent instead of letting it figure out what you mean is still more reliable.
Don’t make Google guess what you’re trying to say. Use the alignment of technical details with your content to help machines parse and comprehend what you have to say, and help your audience get to that content.