
Recently, we were investigating a CPU performance spike issue with an Adobe Experience Manager (AEM) publish server. After some research, we came across logs that indicated indexing had caused the CPU spike.
Adobe Experience Manager is more than just a content management system or an application to serve content to the user’s request. AEM includes more powerful functionality, such as Apache Lucene indexing, which enable full-featured text searches across content in the repository.
Behind the scenes, Apache Lucene fetches the documents in the repository and indexes the content based on the metadata and text content. The index update thread wakes up every five seconds looking for content updates. Apache Lucene uses Apache Tika, a content analysis tool, to get the internal detail of documents like metadata and text in the document to create the indexes.
In a real world scenario, many companies do not rely on AEM search functionality. Companies opt for enterprise-wide search implementations like Adobe Search and Promote or Apache Solr. In these scenarios, all text parsing is handled by third-party engines. Now the question is, do we need to continue with Apache Tika parsing the documents in AEM? The answer is no. It is not required, and by disabling Apache Tika parsing inside AEM, we can reduce the CPU spike.
So, how do you disable document parsing by Apache Tika inside AEM? You don’t even need to disable the Apache Tika bundles. Just like configuring the parser in XML format, in AEM we need to do simple configuration under Oak Index Lucene node.
To disable Apache Tika document indexing in AEM, follow these steps:
- Open CRXDE lite
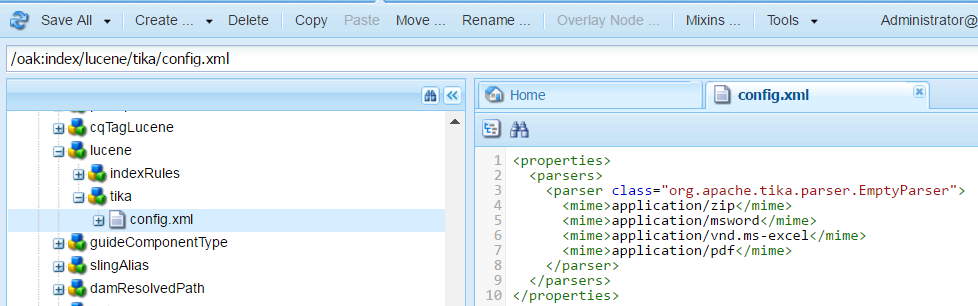
- Navigate to /oak:index/lucene
- Under lucene node create an nt:unstructured node named tika
- Under tika node, create file node named config.xml
- Open the config.xml, add the below entry:
<properties><parsers><parser class="org.apache.tika.parser.EmptyParser"><mime>application/zip</mime><mime>application/msword</mime><mime>application/vnd.ms-excel</mime><mime>application/pdf</mime></parser></parsers></properties><properties> <parsers> <parser class="org.apache.tika.parser.EmptyParser"> <mime>application/zip</mime> <mime>application/msword</mime> <mime>application/vnd.ms-excel</mime> <mime>application/pdf</mime> </parser> </parsers> </properties>
<properties> <parsers> <parser class="org.apache.tika.parser.EmptyParser"> <mime>application/zip</mime> <mime>application/msword</mime> <mime>application/vnd.ms-excel</mime> <mime>application/pdf</mime> </parser> </parsers> </properties> - Repeat the step 3 – 5 for /oak:index/damAssetLucene
- Now save everything.
In the above example, we are disabling the text extraction from Zip, MS-Word, MS-Excel and PDF files. During indexing these files will be ignored for text extraction.
Below is the image showing the configuration:
You can find a complete list of content types on the IANA website, add the type you want to exclude in step five. Based on the above example, you can add the list of MIME Type that you feel can be ignored for text extraction.
Please leave a comment below if you have any questions about indexing or performance related issues.
you can do Pre-extraction using oak run utility
https://jackrabbit.apache.org/oak/docs/query/pre-extract-text.html
In AEM 6.3 this does not work unless you disable the index definition storage configuration in the OSGi console:
1. Navigate to http://localhost:4502/system/console/configMgr
2. Find configuration for Apache Jackrabbit Oak LuceneIndexProvider and make sure Disable index definition storage is checked
3. Save
By default Disable index definition storage is unchecked and Oak’s text extractor keeps using the default Tika config.
Yegor,
Thanks for sharing you’re input.
With Oak version 1.6 above, index definition are cloned and stored as a separate structure. It will be used for query plan calculation. By disabling that check box in OSGI configuration, will have impact on query plan calculation. Please do refer https://jackrabbit.apache.org/oak/docs/query/lucene.html#stored-index-definition
In your instance if Tika config is executed, we need to check multiple things check is your index node as correct tika/config.xml with EmptyParser with correct MIME Types, error.log, Text Extraction step is enabled in Dam Update Asset workflow and also check Adobe CQ DAM Text Extraction configuration.
Thanks Prakash.
I see. In order to recognize the Tika configuration, the index definition needs to be refreshed. Without refreshing Oak will keep using the cached definition cloned at the time of last re-index, i.e. even if tika/config.xml exists, it won’t be recognized unless you tell Oak to do so.
The index definition can be refreshed in two ways:
1. Trigger full re-index by setting index=true in the index node. The definition will be cloned from the JCR node followed by full re-index.
2. Refresh the definition by setting the /oak:index/lucene/refresh property to ‘true’. in this case new assets will be indexed using the new Tika config, the old index entries will remain.
Yegor,
You can also re-index with Touch UI. Goto Operations > Diagnosis > Index Manager. Select the index you want and click on the Re-Index icon.
Thanks
Prakash