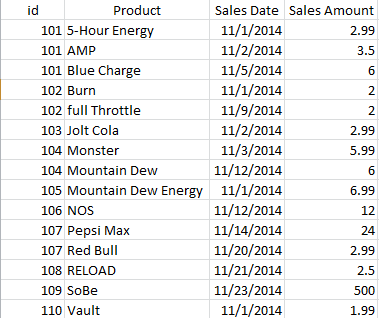
Consider the scenario where you have to convert information held in a “categorical field” into a “collection of flag fields” – found in a transactional source. For example, suppose you have a file of transactions that includes (among other fields) a customer identifier (“who”) and a product identifier (“what”). This file of transactional data indicates purchases of various energy drinks by unique customer IDs:
Aggregation and Flag Fields
What I need is have a single record per unique customer showing whether or not that customer purchased each of the energy drinks (True or False – not sales amounts) during a period of time. More like:
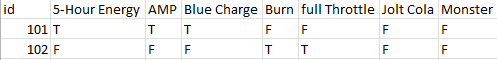
Doing it in TM1
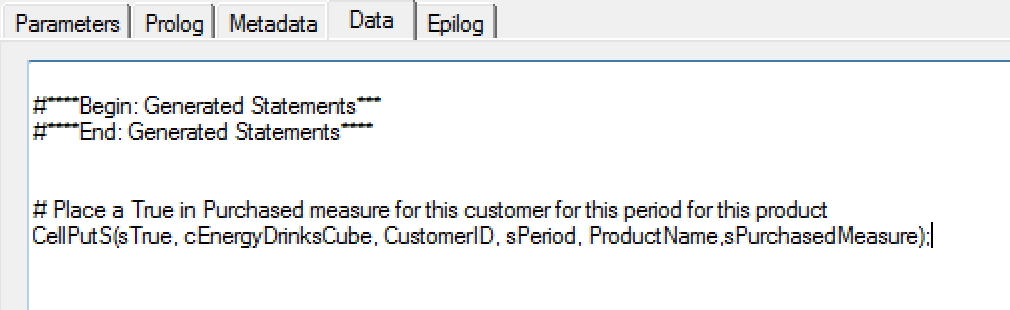
In Cognos TM1, you’d utilize TurboIntegrator to read the file – record by record – aggregating the data (by customer id) and updating each measure (energy drink) – a reasonable trivial process, but still requiring lines of script to be written. Something (assuming you perhaps initialized the period being loaded to all False values) like:
MODELER’s Approach
In SPSS MODELER, the SetToFlag node (found in the Field Ops palette) enables you to create the flags you need and to aggregate the data (based on a grouping, or aggregate key fields) at the same time – without writing any script.
In order to have the SetToFlag node populated with the values of the categorical field, the field has to be instantiated so that MODELER knows the values for which to create flag fields. (In practice, this means that your data has to be read in a Type node prior to the SetToFlag node.) The procedure to create flag fields from the file is:
- Add a SetToFlag node to your stream.
- Edit the SetToFlag node to set the options for the SetToFlag operation.

Editing the SetToFlag
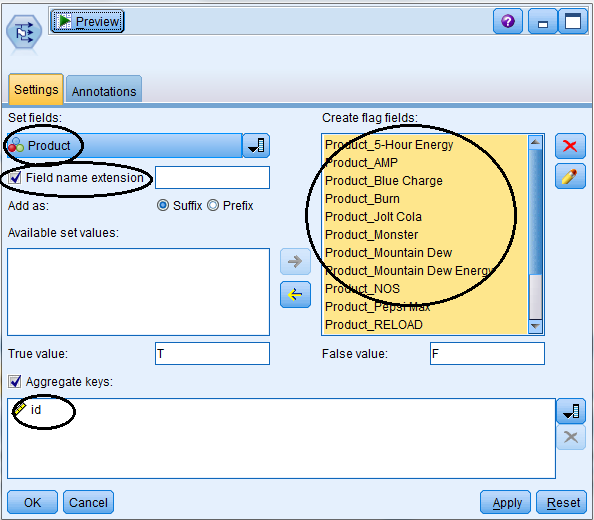
Once you have added your SetToFlag node, you use the Settings tab to:
- Select the categorical field to be expanded in flags (I selected “Product”). The Available set value box is populated with its categories (when the data are instantiated).
- Optionally, add a field name extension for the new flag field’s names, either as suffix or prefix (I left this blank).
- Select the categories for which one wishes to create flag fields in the Create flag fields list box and move them to Create flag fields (I selected all of the products).
- True and False value can be changed, if desired (I left it blank – no changed).
- Optionally, aggregate records by checking the Aggregate keys check box and selecting the appropriate key field(s) – I selected “id”.
Conclusion
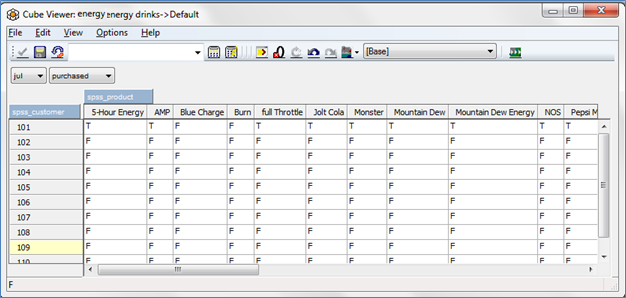
If you go back to the TM1 example, you now have a cube loaded that you can view by customer and period to which products each customer purchased within the period:
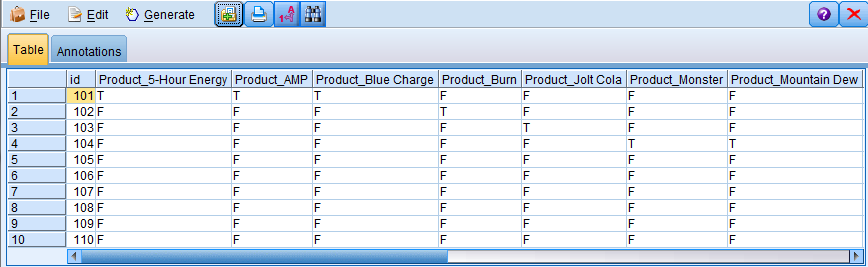
In SPSS Modeler, the output from the SetToFlag node is similar:
Next up – Data Sampling Patterns!
I enjoy what you guys are up too. Such clever work and exposure!
Keep up the wonderful works guys I’ve added you guys to blogroll.