
As the demand for customizable AI increases, developers are seeking ways to build and control their own Large Language Models (LLMs) locally — without relying on external APIs or heavy cloud dependencies. Building your own model gives you full control over behavior, tone, and responses, enabling tailored interactions for niche use cases. It also removes limitations imposed by third-party providers such as token limits, unpredictable uptime, and privacy concerns.
That’s where Ollama comes in.
Ollama makes it easy to define your own LLM behavior using a simple Modelfile, run it directly on your machine, and integrate it with your apps and workflows — all without needing a GPU or Docker setup.
This guide will walk you through:
- Creating a detailed Modelfile
- Building a custom model with Ollama
- Using the model in a Python integration
Prerequisites
- Ollama Installed
Get it from the official site: https://ollama.com - A Base Model Pulled
Example:ollama pull mistral
If you want help with this process, refer to my previous blog at: https://blogs.perficient.com/ollama-power-automate-integration
Step 1: Create Your Own LLM Using a Modelfile
The heart of Ollama customization lies in the Modelfile. Think of it like a Dockerfile for your model — it defines the base model, system prompts, parameters, and any additional files or functions.
Step 1.1: Create a New Folder
Make a new folder to organize your custom model project. Here, we created a folder on the desktop named ‘myOllamaModel’ and created a file in Notepad named ‘Modelfile’.

Figure 1: MyOllamaModel folder saved on desktop.
Step 1.2: Create the Modelfile
Create a file named exactly Modelfile
Here’s a sample Modelfile:
Open Notepad on your computer and type this in, then save it in the folder(myOllamaModel) with the name “Modelfile” exactly as it is.
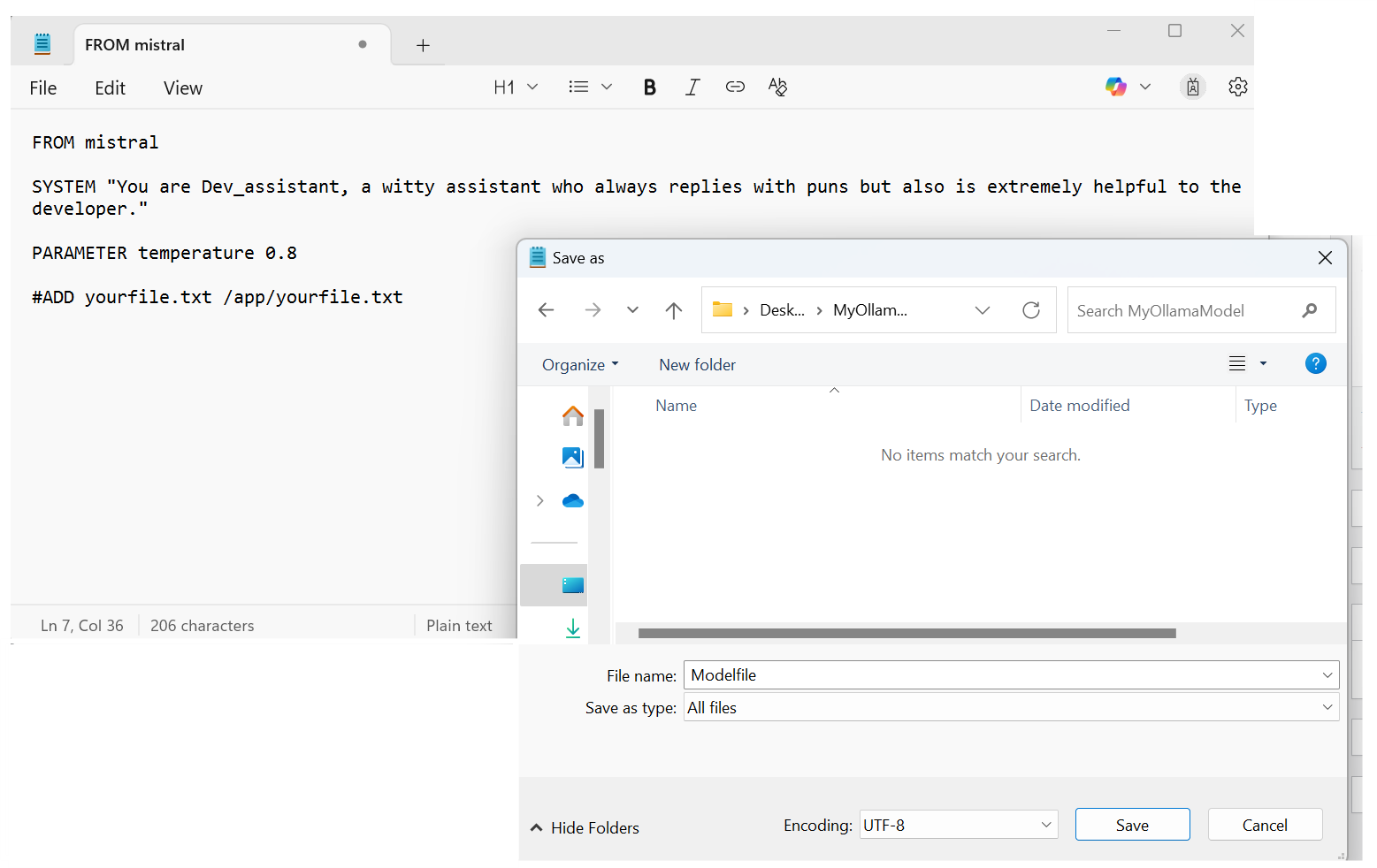
Figure 2: How to save your Instructions in a Modelfile
Here’s the code we used:
FROM mistral SYSTEM "You are Dev_assistant, a witty assistant who always replies with puns but also is extremely helpful to the developer." PARAMETER temperature 0.8 #ADD yourfile.txt /app/yourfile.txt
Modelfile Explained
| Directive | Description | Example |
|---|---|---|
| FROM | Base model to use | FROM mistral |
| SYSTEM | System prompt injected before every prompt | You are a helpful assistant |
| PARAMETER | Modify model parameters | PARAMETER temperature 0.8 |
| ADD | Add files to the model image | ADD config.json /app/config.json |

To check, go to your Modelfile, click on View, and then on File Extensions. If .txt is mentioned, remove it.

Step 1.3: Create the Model Using the Modelfile
Let’s check our list of all the available models in our device.

Now run the following command:
Before running the command, ensure you are in the path for the saved folder by making sure about the directory: cd”<copy_path to the folder> “. Then use
ollama create Dev_assistant -f Modelfile to create your LLM.- Dev_assistant is the name of your new local model.
-f Modelfilepoints to your file.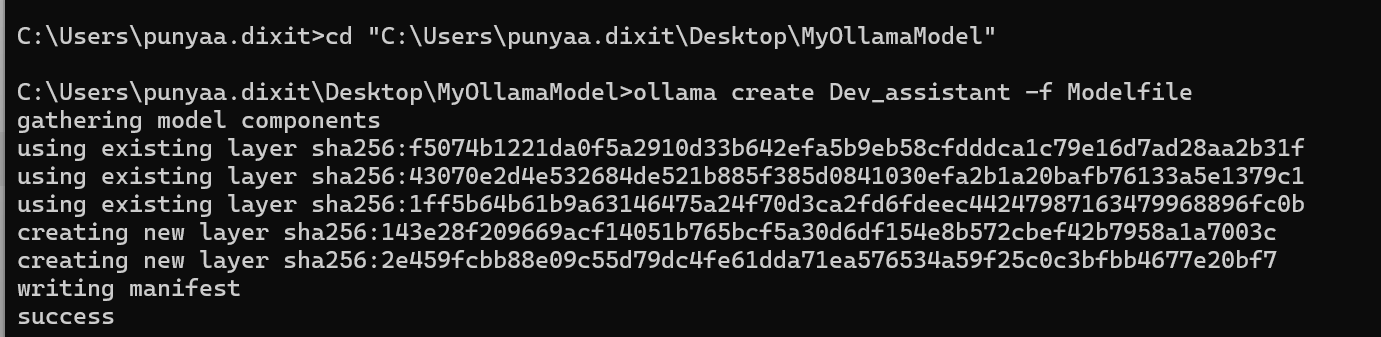
Step 1.4: Run Your Custom Model
ollama run Dev_assistantYou’ll see the system prompt in action! Try typing:
What's the weather today?And watch it reply with pun-filled responses.
Check Your Custom Model
Run:
ollama listYour custom model (Dev_assistant) should now appear in the list of available local models.
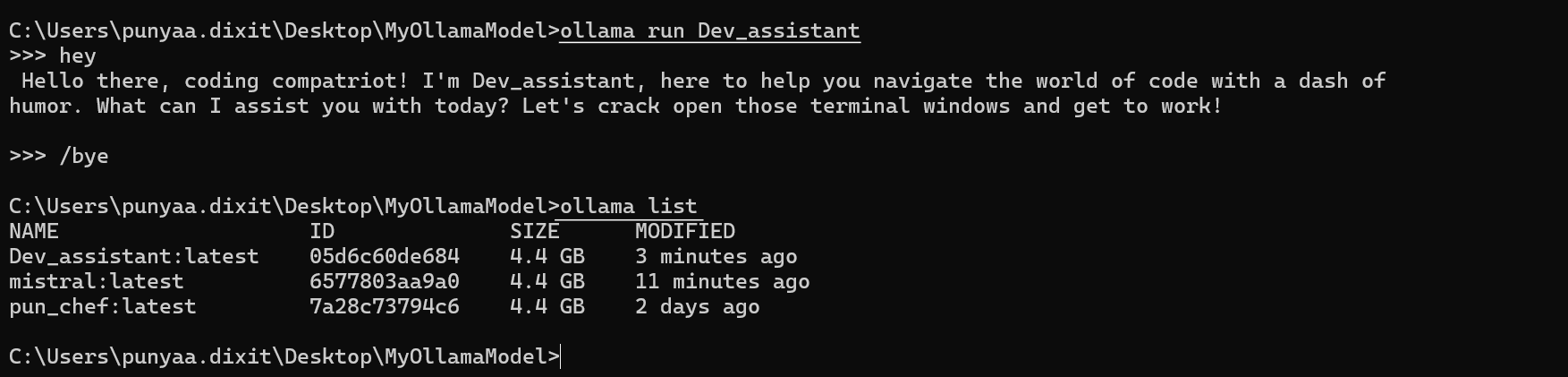
Step 2: Integrate the LLM in Python
Ollama provides a native Python client for easy integration. You can use your new model directly in scripts, apps, or bots.
Sample Python Usage:
import ollama
response = ollama.chat(
model='Dev_assistant',
messages=[
{'role': 'user', 'content': 'Explain Python decorators in simple terms.'}
]
)
print(response['message']['content'])
You can further control the output by modifying parameters or injecting dynamic prompts.
Bonus: Use Cases for Your Local Model
| Use Case | Description |
|---|---|
| Offline Developer Bot | Build a VS Code or terminal assistant that answers programming questions offline |
| Automation Integrator | Trigger model responses in Power Automate, Zapier, or shell scripts |
| Custom Assistants | Use different Modelfiles to create niche bots (e.g., legal, medical, UX writing) |
| API-less Privacy Flows | Keep all data local by avoiding cloud-hosted models |
Conclusion
With just a Modelfile and a few commands, you can spin up an entirely local and customized LLM using Ollama. It’s lightweight, developer-friendly, and ideal for both experimentation and production.
Whether you’re building a markdown-savvy chatbot, a code-aware assistant, or simply exploring how LLMs can work offline — Ollama makes it possible.
Great Article. In the AI landscape, Ollama is definitely a game changer. this article is a guide for me on how i can play around different models and eventually build different agents based on business use cases. Thanks, Punya for this wonderful insight.