
In the bustling city of Tech Ville, where data flows like rivers and companies thrive on insights, there lived a dedicated data engineer named Tara. With over five years of experience under her belt, Tara had navigated the vast ocean of data engineering, constantly learning, and evolving with the ever-changing tides.
One crisp morning, Tara was called into a meeting with the analytics team at the company she worked for. The team had been facing significant delays in processing their massive datasets, which was hampering their ability to generate timely insights. Tara’s mission was clear: optimize the performance of their Apache Spark jobs to ensure faster and more efficient data processing.
The Analysis
Tara began her quest by diving deep into the existing Spark jobs. She knew that to optimize performance, she first needed to understand where the bottlenecks were. she started with the following steps:
1. Reviewing Spark UI: Tara meticulously analyzed the Spark UI for the running jobs, focusing on stages and tasks that were taking the longest time to execute. she noticed that certain stages had tasks with high execution times and frequent shuffling.

2. Examining Cluster Resources: she checked the cluster’s resource utilization. The CPU and memory usage graphs indicated that some of the executor nodes were underutilized while others were overwhelmed, suggesting an imbalance in resource allocation.
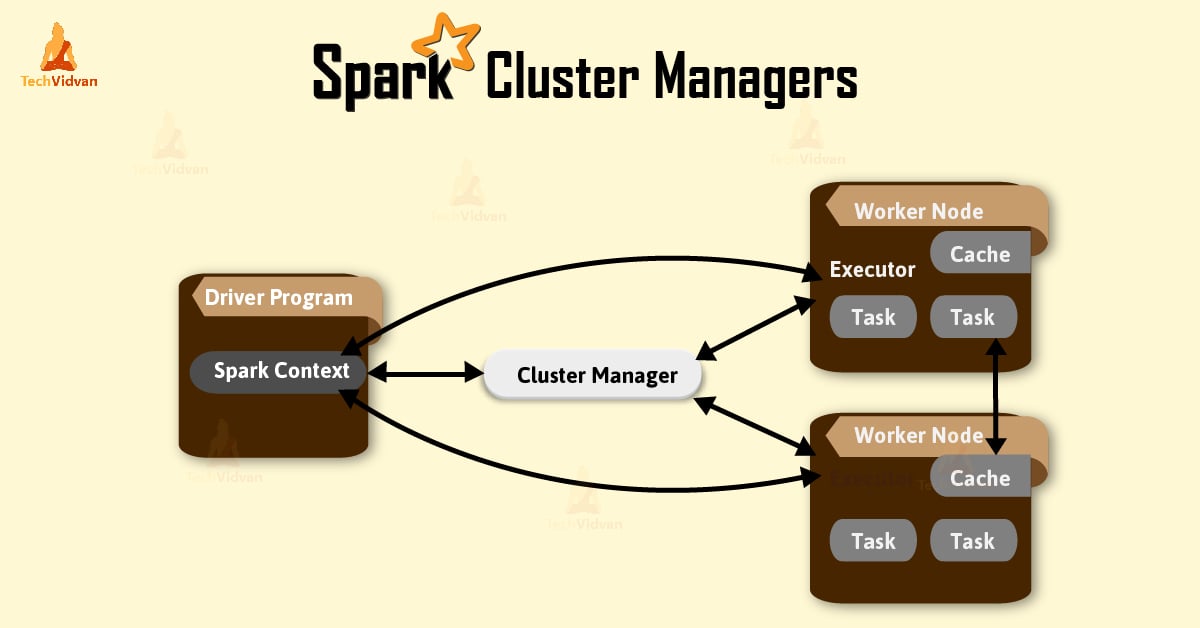
The Optimization Strategy
Armed with this knowledge, Tara formulated a multi-faceted optimization strategy:

1. Data Serialization: she decided to switch from the default Java serialization to Kryo serialization, which is faster and more efficient.
conf = SparkConf().set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
2. Tuning Parallelism: Tara adjusted the level of parallelism to better match the cluster’s resources. By setting `spark.default.parallelism` and `spark.sql.shuffle.partitions` to a higher value, she aimed to reduce the duration of shuffle operations.
conf = conf.set(“spark.default.parallelism”, “200”)
conf = conf.set(“spark.sql.shuffle.partitions”, “200”)
3. Optimizing Joins: she optimized the join operations by leveraging broadcast joins for smaller datasets. This reduced the amount of data shuffled across the network.
small_df = spark.read.parquet(“hdfs://path/to/small_dataset”)
large_df = spark.read.parquet(“hdfs://path/to/large_dataset”)
small_df_broadcast = broadcast(small_df)
result_df = large_df.join(small_df_broadcast, “join_key”)


4. Caching and Persisting: Tara identified frequently accessed DataFrames and cached them to avoid redundant computations.
df = spark.read.parquet(“hdfs://path/to/important_dataset”).cache()
df.count() – Triggering cache action
5. Resource Allocation: she reconfigured the cluster’s resource allocation, ensuring a more balanced distribution of CPU and memory resources across executor nodes.
conf = conf.set(“spark.executor.memory”, “4g”)
conf = conf.set(“spark.executor.cores”, “2”)
conf = conf.set(“spark.executor.instances”, “10”)

The Implementation
With the optimizations planned, Tara implemented the changes and closely monitored their impact. she kicked off a series of test runs, carefully comparing the performance metrics before and after the optimizations. The results were promising:
– The overall job execution time reduced by 40%.
– The resource utilization across the cluster was more balanced.
– The shuffle read and write times decreased significantly.
– The stability of the jobs improved, with fewer retries and failures.
The Victory
Tara presented the results to the analytics team and the management. The improvements not only sped up their data processing pipelines but also enabled the team to run more complex analyses without worrying about performance bottlenecks. The insights were now delivered faster, enabling better decision-making, and driving the company’s growth.
The Continuous Journey
While Tara had achieved a significant milestone, she knew that the world of data engineering is ever evolving. she remained committed to learning and adapting, ready to tackle new challenges and optimize further as the data landscape continued to grow.
And so, in the vibrant city of Tech Ville, Tara’s journey as a data engineer continued, navigating the vast ocean of data with skill, knowledge, and an unquenchable thirst for improvement.