
Written by Gerald Frilot
AWS offers many useful services that can be customized to meet our growing demands. In this case, we are going to focus on Amazon S3 and Lex to explain how these AWS services can be configured to manage large amounts of data. We will also describe an advanced approach to updating an Amazon Lex instance programmatically.
The following scenario will give us a good example of how Amazon S3 can easily be updated to facilitate data management.
Scenario
An online global distributor for all automotive-related inventory is in the final stages of deploying a call center to assist with sales, technical support, and inventory tracking. All products are contained in a global spreadsheet that gets updated periodically. Let’s consider the following:
- This spreadsheet contains about 2,000 rows of data.
- The data needs to be written to a Lex bot currently used via webchat and IVR (Interactive Voice Response).
- This spreadsheet gets updated at least three times a week.
Now, we will find a step-by-step solution on how to store our global spreadsheet and easily connect it to a Lex bot. We will begin by creating an S3 bucket to store our global spreadsheet, and then we will create a Lex Bot with a custom slot type for related updates. Later, we will update our pipeline to target the custom slot type and perform a write-through containing all the records from the spreadsheet.
Amazon Simple Storage Service (S3)
Let’s first create an S3 bucket to store the global spreadsheet because this action allows us to host our spreadsheet where it can be read and written to. Also, the S3 bucket makes the data accessible.
Log into your AWS account, search for the Amazon S3 service, and follow these steps for
- Select a meaningful name
- Select an AWS Region
- Keep all defaults
- ACLs disabled (Recommended)
- Block all public access (Disable)
- Bucket Versioning (Disable)
- Default encryption (Disable)
- Select Create Bucket (This creates a new S3 instance for data storage)
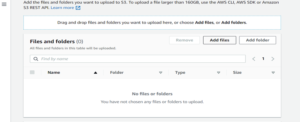
5. Once the bucket is created, we can now upload the global spreadsheet to S3 by selecting Upload and then Add files

Amazon Lex (Custom Slot Type)
We now have a spreadsheet of test products uploaded to an S3 bucket. A single user can easily update the spreadsheet while the rest of the organization can use it as a read-only file.
The next step is to create an additional Lex Bot that will replace the one currently used by our customer. Instead of manually adding new products or services to the Lex bot, we can trigger the pipeline to read any changes made to the file stored in S3. This will also update the custom slot type during the run stage.
Note: The following guidelines use Lex V1.
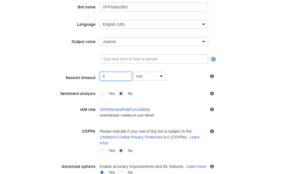
Return to the AWS dashboard, search for Lex, and select Create. Here you can configure values such as the bot’s name, language, output voice, session timeout, and preferred COPPA compliant status.
- Once you have configured your bot, select Create Bot
- Create an intent (NOTE: Intent name must be unique)
- Select Add
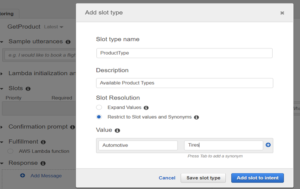
- Create a custom slot type
a. Enter a name for the slot type, a description, and select Restrict to Slot values and Synonyms
b. Manually enter the very first line item from the spreadsheet and select Add slot to intent
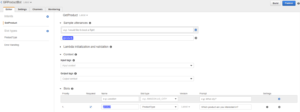
- Update Slots to use the custom slot type that was just created
- Build and Publish the bot
Once the Lex bot has been created, we can modify the pipeline to update the custom slot type with all the records contained in the global spreadsheet.
AWS Code Pipeline
The snippet below is embedded in a YAML file that contains a list of commands to run when the pipeline is triggered.
- Bash Command (Local Repository)
- Install the python package for working with excel files
- Copy the S3 file and save it to a local directory
- Execute a Python script for creating a JSON copy of the CSV file
- Change directory and install/run npm
- Execute a JavaScript file to update the custom slot type
- Copy the JSON file from the local directory to the S3 bucket
# Fetch Product Data and Update Dev Environment
– bash: |
pip3 install openpyxl
aws s3 cp s3://gf-test-products/product_data.xlsx product_data.xlsx –region $AWS_REGION
python3 update_product_data.py
cd pace-cli-utils
npm install
npm run build
node src/commands/updateProductsDataSlotType.js
aws s3 cp /tmp/product_data.json s3://gf-test-products/product_data.json –region $AWS_REGION
displayName: ‘Fetch Product Data and Update Dev Environment’
workingDirectory: tooling/scripts
condition: and(succeeded(), eq(‘${{ parameters.DEPLOY_PRODUCT_DATA }}’, true))
env:
AWS_ACCESS_KEY_ID: $(DEV_AWS_ACCESS_KEY_ID)
AWS_SECRET_ACCESS_KEY: $(DEV_AWS_SECRET_ACCESS_KEY)
AWS_REGION: $(AWS_REGION)
Python Script (update_product_data.py):
Python script creates an instance of an Excel workbook using the openpyxl module. It then loops over the workbook (S3 file previously copied from bash command) and saves the values in an OrderedDict data structure. After the loop terminates, an OrderedDict is initialized with the CSV file in JSON format. This data is then written to a tmp directory to be stored in S3 later.
JavaScript file (updateProductsDataSlotType.js):
JavaScript file requires the aws-sdk and file system modules. The file has an async main function that retrieves both the slot type version and the custom slot type. We begin by reading the JSON file created from the above-mentioned Python script and then we assign it to a variable. An empty array is initialized before iterating over the file. Later, it is edited with values and synonyms needed to update the custom slot type. If there are no errors throughout these actions, we can update the slot type.
AWS Solution Delivered
We have chosen AWS Services because of its flexibility and ability to drive results to the market in a timely manner. In this case, we used the advantages of Amazon Lex and S3 services to effectively manage and utilize a large data set with minimal resources. By directing our attention to AWS Cloud, we solved a real-world problem in an effective and innovative way.
Contact Us
At Perficient, we are an APN Advanced Consulting Partner for Amazon Connect which gives us a unique set of skills to accelerate your cloud, agent, and customer experience.
Perficient takes pride in our personal approach to the customer journey where we help enterprise clients transform and modernize their contact center and CRM experience with platforms like Amazon Connect.For more information on how Perficient can help you get the most out of Amazon Lex, please contact us here.