
What is a Data Warehouse?
A data warehouse, or enterprise data warehouse (EDW), is a system to aggregate your data from multiple sources, so it’s easy to access and analyze. Data warehouses typically store large amounts of historical data that can be queried by data engineers and business analysts for business intelligence.
Instead of only having access to your data in individual sources, a data warehouse will funnel all your data from disparate sources (transactional systems, relational databases, and operational databases) into one place. Once it’s in the warehouse, it’s accessible and usable across the business to get a holistic view of your customers. When your data is in one place, you can analyze related data from different sources, make better predictions, and ultimately make better business decisions.
There are two ways to go about implementing a new data warehouse. You can have one on-premise, designed and maintained by your team at your physical location, or you can use a cloud data warehouse—one that lives entirely online and doesn’t require any physical hardware. Cloud data warehouse architecture makes it easier to implement and scale, and they’re typically less expensive than on-premise data warehouse systems. Below, we’ll discuss what to consider and your options for the best data warehouses.
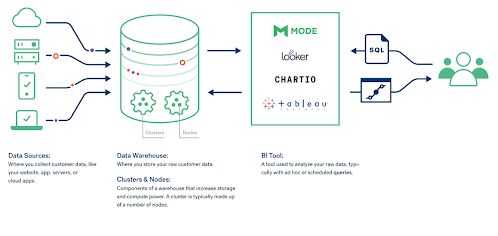
Data Warehouses vs. Databases: How They’re Different
Databases and data warehouses are related but not the same.
A database is a way to record and access information from a single source. A database often handles real-time data to support day-to-day business processes like transaction processing.
A data warehouse is a way to store historical information from multiple sources to allow you to analyze and report on related data (e.g., your sales transaction data, mobile app data, and CRM data). Unlike a database, the information isn’t updated in real-time and is better for data analysis of broader trends.
Data Warehouses vs. Data Lakes: How They’re Different
A data lake is for storing any and all raw data that may or may not yet have an intended use case. On the other hand, a data warehouse holds already processed and filtered data, ready to be used and analyzed.
A data lake, hosted on big data platforms like IBM or Hadoop, is ideal for data scientists and analysts to store raw data until they know what they want to do with it or as a repository to store large amounts of unstructured data.
A data warehouse is perfect for giving access to structured and semi-structured data to multiple business users so they can run queries against it and make decisions quickly.
When and Why to Use a Data Warehouse
If you’re bored with the insights your current analytics tools can provide, it’s time to integrate a data warehouse into your tech stack. You’ll be able to dive deeper than you can with individual database management.
When to Use a Data Warehouse
You should consider a data warehouse if you want to:
- store all of your historical data in a central repository
- analyze your web, mobile, CRM, and other applications together in a single place
- get deeper business insights than traditional analytics tools by querying data directly with SQL
- provide multiple people access to the same data set simultaneously
Why to Use a Data Warehouse
Data warehousing helps you answer those tough analytical questions that your board may be asking that aren’t possible to address with your standard data analytics tool. Reports and analyses you run in data warehouses can include elements from every one of the data sources you’ve connected to it—pretty powerful stuff! This data integration means you can analyze data from your website and app and other platforms you may use, like Salesforce, Zendesk, Stripe, and more.
For example, Google Analytics can give you a good sense of customers’ actions on your website or app. However, you’re limited to asking questions that can be answered with the number of variables, properties, and types of charts that it provides. When you hook up Google Analytics to your data warehouse, you can tie that information to data from your CRM, sales platform, and so on for a complete view of your customers.
When you have all your data in one place, you can efficiently run queries directly in your warehouse or through a business intelligence tool like Tableau, Looker, or Mode to automate and visualize those queries and aid decision-making.
6 Factors to Consider When Choosing a Data Warehouse
Now you know the benefits of a data warehouse—but how do you pick one? Consider these factors when determining which data warehouse best suits your business needs.
1. Data Types
There are three types of data that you might want to store for your business: structured, unstructured, and semi-structured. Most data warehouses support structured and semi-structured data management, but unstructured data is better for data lakes.
- Structured data is quantifiable data that can be organized neatly into rows and columns (e.g., sales records or customer contacts).
- Unstructured data is data that can’t be easily managed and analyzed. Think of written content (like blog posts or answers to open-ended survey questions), images, videos, audio files, and PDFs. If you’re looking to store purely unstructured data, you should consider a data lake instead of a data warehouse.
- Semi-structured data is a mix of structured and unstructured data. Take an email, for example. The content of that email is unstructured, but there are quantifiable aspects to the email, such as who sent it, when they sent it, when it was opened, etc. Similarly, an image itself is unstructured, but you also often have access to structured data, like when the photo was taken, device type, photo size, geotags, etc.
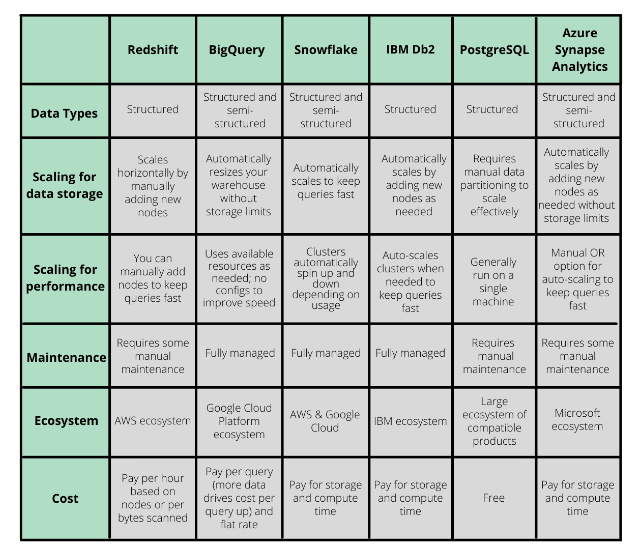
If semi-structured data is essential to you, BigQuery and Snowflake are two data warehouses known for having the best infrastructure to support storage and queries for semi-structured data.
2. Scaling for Data Storage
Most data warehouses typically allow you to store massive amounts of data without much overhead cost. You probably won’t need more than what they offer, especially if analytics is the primary use case.
However, you’ll want to consider how a particular warehouse scales data storage during times of demand. For example, Amazon Redshift will require you to manually add more nodes (the basic structures in data warehousing that store data and execute queries) when you need more storage and computing power. On the other hand, Snowflake offers an auto-scale function that dynamically adds and removes clusters of nodes as needed.
3. Scaling for Performance
The performance of a data warehouse refers to how fast your queries can run and how you maintain that speed in times of high demand. As you can imagine, scaling for performance and data storage are closely connected. Like storage, performance will increase as you scale up the nodes in your warehouse.
These days, speed is a non-issue. Every warehouse is about as fast as the others. What you really want to consider regarding performance is how much control you want over your speed.
Like a data warehouse’s storage scales, you can add and remove nodes for faster queries. For some warehouses, like Redshift, you need to do that manually, but you’ll be able to tune it as precisely as you like. For others, like Snowflake, it will happen automatically for a hands-off experience.
4. Maintenance
You likely want your engineers focused on building and maintaining your products instead of worrying about ETL pipelines and the day-to-day management of your warehouse—especially if you have a small team. In that case, you’ll want a self-optimizing data warehouse like BigQuery, Snowflake, or IBM Db2.
However, by maintaining your warehouse manually, experienced data warehouse architects can have greater control and flexibility to optimize it precisely for your company’s needs. If you want this level of control over your warehouse’s performance and cost, Redshift and PostgreSQL are your best options.
5. Ecosystem
Consider using a data warehouse within the ecosystem of the applications you already use. For example, Azure Synapse Analytics is in the ecosystem of Microsoft products, Redshift within AWS, and BigQuery within the Google Cloud ecosystem. This will simplify implementation since you already have an infrastructure in place.
Otherwise, you’ll need your engineers to develop multiple custom ETL pipelines to get your data where it needs to be. You may still need to write a custom ETL to get data into your warehouse from specific data sources, but the goal is to minimize that work.
6. Cost
Many factors go into data warehouse pricing, including storage, warehouse size, run time, and queries. For Redshift, you pay per hour based on nodes or per bytes scanned. BigQuery, however, has both a flat-rate and a per-query model. Snowflake, IBM Db2, and Azure are based on storage and compute time.
Ultimately, you want to choose the data warehouse that will do what you need, not just the cheapest option.
PostgreSQL is a great free option for companies with a limited budget and still has plenty of features. When you’re ready to upgrade, switching data warehouses is easy, especially if you’re using a customer data platform like Segment that can communicate seamlessly between the two warehouses.
The Best Data Warehouses in 2022
You should have a good idea of what you need based on the factors above. Here’s how the top data warehouses on the market compare. The good news is: They all integrate with Segment, so you can load your data in minutes.
Find the Right Data Warehouse for your Business
Ready to add a data warehouse to your stack? Before you choose a tool, don’t forget to consider:
- the type and amount of data you want to store
- how dynamically do you need it to scale
- how fast do you need your queries
- whether you want manual or automatic maintenance
- the compatibility of the data warehouse with your existing tech stack
- the cost
Once you’ve picked a data warehouse, you’ll be well on getting better access to your business data. You’ll be able to analyze it, identify trends, make better predictions for the future—and ultimately make better business decisions.
Excellent Content. So nicely explained.
Really very informative !! Have a great blog !!!
I’ll be coming back to your blog for more soon.