
IBM Cloud Pak for Data- Data Science MLOPS:
I have been Learning, exploring and working on IBM MLOPS for Data Science and wanted to share my learning and experience here about IBM’s Cloud services and how they are integrated under one umbrella named IBM Cloud Pak for Data.
First, let’s understand what IBM Cloud Pak for Data is.
IBM Cloud Pak for Data is a cloud-native solution that enables you to put your data to work quickly and efficiently.
Your enterprise has lots of data. You need to use your data to generate meaningful insights that can help you avoid problems and reach your goals.
But your data is useless if you can’t trust it or access it. Cloud Pak for Data lets you do both by enabling you to connect to your data, govern it, find it, and use it for analysis. Cloud Pak for Data also enables all of your data users to collaborate from a single, unified interface that supports many services that are designed to work together.
Cloud Pak for Data fosters productivity by enabling users to find existing data or to request access to data. With modern tools that facilitate analytics and remove barriers to collaboration, users can spend less time finding data and more time using it effectively.
And with Cloud Pak for Data, your IT department doesn’t need to deploy multiple applications on disparate systems and then try to figure out how to get them to connect.
Data Science MLOPS POC:
Before you begin an IBM Data Science MLOPS POC you need to have some pre-requisites done:
- You need to have Cloud Pak for Data as a Service (CPDaaS) account as well IBM Cloud Account- Cloud Pak for Data as a Service (CPDaaS) account – https://dataplatform.cloud.ibm.com.
- If you don’t have a CPDaaS account, then you can sign-up for a Free trial account, and the same is true for IBM Cloud Account.
- Please provide all required services using IBM Cloud Account (https://cloud.ibm.com/login) and make such as Watson Studio, Watson Knowledge Catalog, Watson Machine Learning, Watson OpenScale, and DB2 Service.
Data science MLOPS POC was focused on the main capabilities and strengths of Watson Studio and related products. The three main themes of POCs were:
- MLOps: End-to-End data science asset lifecycle
- Low code data science: developing data science assets in visual tools
- Trusted AI: an extension of MLOps with a focus on data/model governance and model monitoring
IBM MLOPS Flow

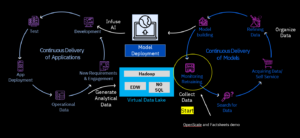
Source of Diagram: IBM Documentation
Learned about MLOPS Phases and how we can approach a Data Science POC:
- Discovery – Identify the data, Set-up data connection, and load the data. Build the Data transformation and Virtualization process
- Ingestion and Preparation – Data Ingestion, Validate the data post-ingestion and data pre-processing.
- Development – Develop the model and automated it. Version control using GIT for any Code changes. Store the Model Repository and maintain it.
- Deployment – Deploy the Model either in a Manual or Automated way. Score the Model and manage the artifacts. Have Change management controls.
- Monitoring – Set up Model Monitoring and Alerts
- Governance – Set up end to end Approval management process.
To build a Data Science POC we perform the followings activities/tasks:
Data Access: This covers Discovery, Ingestion, and Preparation
- In CPD (IBM Cloud Pak for Data) Cluster, I’ve created an Analytics Project.
- Added Data as an Asset to a project and in the Assets Tab uploaded a sample Customer data
- Added DB2 on Cloud Connection to the Project -> Data Asset with all required DB, Hostname, and Port details.
- Form the Add to Project ->Connected Data ->Selected the Source, Schema, and Table names and now the Customer Table has been created and displayed under the Data Assets tab
- Form the Add to Project ->Notebook – Created a Notebook with Python 3.9 and Spark 3.0 environment. This environment will help us with Data Import. This is mainly for Code Generation and importing data via Pandas and Spark data frame.
- By Navigating to Notebook -> You can select the Insert to Code for your Data Asset (Customer Table)->Execute it and load the data into the data frame
- Similar way you can write data to a database using notebook code.
- You can also create a connection to IBM Cloud Object Storage and load the data
- Added Created Data Assets as above to Catalog by creating a new Catalog.
- Promoted data assets to a deployment space.
- Worked on Storage Volume where you can access files from a shared file system like NFS.
Watson Studio- Open Source and GIT with cpdctl for automated CI/CD deployment process: This Covers Development and Deployment
- Performed Watson Studio-Git integration by creating a new Project in IBM Watson Studio. This is required for building and updating scripts using Python and Jupyter Lab
- GIT can be used here from MLOPS CI/CD and can be integrated with Jenkins/Travis.
- In Jupyter Lab-created 2 Notebooks with sample code and set up 2 User IDs in CPD one with Editor and the other as Collaborator.
- User 1 Committed the Code to Git Repo and Push the changes.
- With other User IDs as Collaborators Pull the Changes and did some code modifications. Commit the changes to Git Repo.
- User ID 1 Pull the changes and see the updated/modified code.
- Worked on cpdctl (Cloud Pak for Data Command Line Interface) and moved Jupyter Lab Notebook Scripts to Project and to Deployment space. With cpdctl you can automate an end-to-end flow that includes training a model, saving it, creating a deployment space, and deploying the model.
- Performed Package Management – Install Libraries such as Anaconda in Notebook to do quick testing
- Jobs in Watson Studio – Created a Job for Notebook Developed and invoked the Job.
- Data Science Deployment (Model, Scripts, Functions) –
- There are mainly two types of Deployment Batch and Online.
- Online: a real-time request/response deployment option. When this deployment option is used, models or functions are invoked with a REST API. A single row or multiple rows of data can be passed in with the REST request.
- Batch: a deployment option that reads and writes from/to a static data source. A batch deployment can be invoked with a REST API.
a. In CPD, Created a new Deployment Space ->Online– Selected the Customer Data Predict notebook->Execute and Save the Model using WML Object.
b. From the Projects -Assets view -> Locate the Model -> Promoted the Model by Selecting Deployment Space.
c. From Deployment Space -> Select the Model and Deploy it by clicking the Deploy button.
d. Similar way created Deployment Space for Batch -> Created Job -> Selected Customer data CSV as the source and executed it.
e. This is how we do automatic deployment of the model to a deployment space.
Monitoring and Governance – IBM Watson OpenScale is used for Monitoring the model in terms of Fairness, Quality, Drift, and other details.
Conclusion: IBM Cloud Pak for Data is a powerful Cloud Data, Analytics, and AI platform solution that provides end-users quick governed data access, increased productivity, and cost savings.
Note: Please note that some of the diagrams and details are taken from IBM (ibm.com/docs and other reference materials).
If you are interested in exploring and learning IBM Cloud Pak for Data and its services then please go through below tutorial:
Announcing hands-on tutorials for the IBM data fabric use cases