
Google has made Googlebot evergreen as of May 2019, which improves rendering capacity significantly, including JavaScript rendering, JavaScript processing, and processing speed. But does it mean Google will also understand JavaScript on your page?
In this episode of the award-winning Here’s Why digital marketing video series, Mats Tolander joins Eric Enge to explain why content, links, and URLs are key to JavaScript for SEO.
Don’t miss a single episode of Here’s Why. Click the subscribe button below to be notified via email each time a new video is published.
Resources
- Why You Must Know about the New Evergreen Googlebot – Here’s Why #217
- See all of our Here’s Why Videos | Subscribe to our YouTube Channel
Transcript
Eric: In this episode of Here’s Why. We have Mats Tolander with us. Mats is our Technical SEO Director, and you might have guessed, he helps us with technical SEO with a lot of our clients. Today, we want to talk about JavaScript and SEO. What was really interesting was that last year, in May, Google updated its Googlebot – well, basically what they said is that they made it evergreen. What they meant by that is that they are now ensuring that Googlebot will more or less always be running the same version of the Chrome Web Dev Kit as the Chrome browser. So, if Chrome can render it, in theory, Googlebot should be able to render it. But that wasn’t always the case, Mats. What was the problem before the existence of the evergreen Googlebot?
Mats: Before the evergreen update, Google was stuck with the rendering capabilities of Chrome 41, a version of Chrome from 2015. That version had an increasingly outdated understanding of JavaScript, which meant that even though Googlebot could render a lot of JavaScript, there was an increasing amount that it could no longer process. Here’s an example of JavaScript that Google published in late 2015 to showcase the capabilities of Chrome 46.
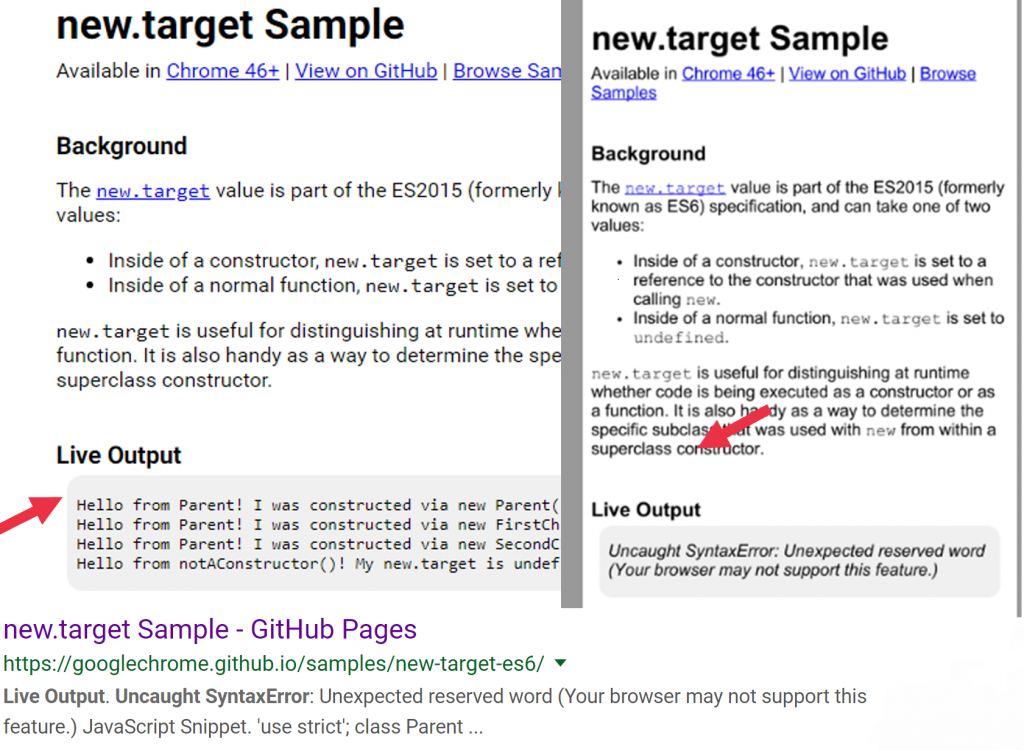
Unfortunately, Google couldn’t process that script, and it stayed that way for years. If you retrieve their embedded content using JavaScript, there was a distinct possibility that Google couldn’t see that content. And Google basically can’t index or rank content that it can’t see.
Eric: But that wasn’t the only challenge for web publishers who rely on JavaScript. Isn’t that right?
Mats: That is correct. In addition to Google struggling with some JavaScript, it could also take a significant amount of time for the search engine to process JavaScript in the page that it crawled – as much as a couple of weeks, which obviously isn’t great if your content is even somewhat time-sensitive, even if Google can see the content when it is rendered.
Eric: So, why did it take Google so long to process to JavaScript?
Mats: Google crawls a webpage in basically two steps. First, it reads the HTML file that it requested from the URL. It then renders the page, meaning it executes the JavaScript and reads the CSS associated with the page to fully understand the content and the layout of the page. The rendering wave is much more resource-intensive, and that’s where Google queued and kind of rationed the processing.

Eric: Got it. So, you had a situation where Googlebot’s support for JavaScript was increasingly spotty. What changed in May of 2019?
Mats: First was the rollout of the evergreen Googlebot, as you mentioned earlier. The updated bot and rendering system, broadly speaking, have the same capabilities as the Chrome browser that is currently in the market, hence the word evergreen.
Eric: Got it.
Mats: In addition, Google’s rendering capacity has improved significantly, and, according to Martin Splitt from Google, the median wait time between parsing and rendering is only five seconds now.
Eric: Five seconds is not bad, but does that mean there’s no reason to worry about JavaScript at all when it comes to SEO?
Mats: It doesn’t mean that because, just as you can do things with HTML that are not good for SEO, you can do things with JavaScript that are not good for SEO.
Eric: So, what do you mean? I mean, if Google can see the same thing I can see in my browser, what’s the problem?
Mats: Fundamentally, there are three things to keep in mind: content, URLs, and links. With JavaScript, it’s easy to build websites that work well for a human but not for a search engine bot. A search engine like Google requests a URL, reads the content in that URL, and adds it to the index. When a person is searching for something that is specific to that content, the search result might include the link to the page. This isn’t difficult when the content is embedded in the HTML. It’s trickier when the content has to be retrieved and processed and added to the page by the JavaScript. The key is to make sure all the content you want to have indexed for the specific page is in the rendered HTML when the page has finished loading. The second factor is the URLs. With JavaScript, it’s easier to create a so-called single-page application that a user can navigate. But, because it’s a single page, it becomes impossible for a search engine to associate content to any URL other than the homepage of the single-page application.
Eric: So, one of the things you’re talking about there – just to clarify for people – the user does something on the page, the content and the page changes, and the URL doesn’t change. The result is that Google doesn’t do that. They don’t pull that content out. So, it’s effectively invisible to them.
Mats: That’s exactly right. One way around this is to make sure that the SPA does, in fact, have a unique URL for every page. And this is where we get to another potential pitfall with JavaScript. A URL can contain different parts, including a path, a query string, and a fragment. Paths and query strings can be used to create unique indexable URLs, but fragments cannot. A fragment URL, or URL fragment, really just points to a specific spot in a page, but it is itself not a page.
But with JavaScript, it’s possible to use a fragment to determine what content to show on the page. That works for a user, but not for a search engine because a search engine, and certainly Google, will consolidate fragment URLs to the canonical non-fragment URL. This won’t always happen right away, but you should expect it to happen. Again, if you use fragments to show a user the content in question, you will render those pieces of content, in effect, invisible to Google search.

Eric: So, if you want to do well on organic search, you need to make sure that each page has a unique and indexable URL.
Mats: Yes, that’s right.
Eric: So, Mats, you mentioned links as a third potential pitfall, but what does that have to do with JavaScript?
Mats: In HTML, a link is a specific piece of code that tells the browser to load the new document when the link is clicked. In fact, HTML stands for Hypertext Markup Language, and the link is what creates hypertext. With JavaScript, you don’t need the link to request new content.
 You can use what’s called an event – for example, a mouse click or a screen tap. And if that’s not tied to an actual link, Google won’t see it and won’t use it to pass along important signals.
You can use what’s called an event – for example, a mouse click or a screen tap. And if that’s not tied to an actual link, Google won’t see it and won’t use it to pass along important signals.
Eric: So, if I make sure Google can understand the JavaScript that gets the content for a specific page, and that page has a unique URL, and the page uses real links to link to other pages, then I don’t have to worry about JavaScript’s impact on SEO. Is that correct?
Mats: There’s always a reason to worry. For example, if Google, for some reason, fails to execute the JavaScript that pulls in the content, it won’t see the page properly. And there are also bots and apps out there that may not have Google’s JavaScript capabilities.
Don’t miss a single episode of Here’s Why. Click the subscribe button below to be notified via email each time a new video is published.
See all of our Here’s Why Videos | Subscribe to our YouTube Channel