
Everything is data and everyone is data!
Everybody says we live in the technology age, the age of the internet, the age of space and cosmos, the age of the digital world etc. But all of these developments and advancements have been made possible by the Holy Grail called Data. We learned how to store data, evolved to see patterns in data and extract the information we need. Therefore, I would say we actually live in the Data Age.
Organizations use this data, study it, mine it and they work to understand the science behind the data to get the key information they need. Hence, handling mountains and mountains of data is not a special trait or niche skill anymore. It has become a basic mandate for an IT sector to stay relevant in this fast-paced world.
So, as a part of this blog, we are going to examine how to handle this huge amount of data for data warehousing purposes using the Informatica ETL tool without any compromise on the performance. I will also discuss the do’s and don’ts of this approach.
What is Bulk Mode?
In Informatica, the bulk-loading option increases the performance of a session where huge volumes of data are involved. Bulk load configuration is applicable in:
- DB2
- Sybase ASE
- Oracle
- Microsoft SQL Server databases.
During bulk loading, the Integration Service bypasses the database log, which results in performance improvement. Without writing to the database log, however, the target database cannot perform a rollback. As a result, recovery will not be possible. While using bulk loading, the need for improved session performance must be weighed against the ability to recover an incomplete session.
Differences Between Normal and Bulk Load

Comparison between Bulk and Normal mode
Advantages and Disadvantages of Bulk Loading
Advantages: The major advantage of using bulk load is in the significant improvement of performance. Especially in the large volume table, bulk loading speeds up the process.
Disadvantages: If the Informatica job fails, the recovery is not possible due to the bypass of database logs. The only option during job failure is truncate and re-load.
Right Platform for Using Bulk Loading
Bulk loading requires the right set of platforms to work at its best. The guidelines for selecting a bulk mode for any platform have been listed below:
- Databases such as DB2, Sybase ASE, Oracle, or Microsoft SQL Server databases.
- The table should not have any auto-generating feature (auto-increment feature).
- The indexes along with constraints have to be dropped and created before and after job run.
- The table should not have any identity columns in it.
- The table should not have a row change timestamp feature in its columns.
Bulk Loading in Informatica
Now let’s learn more details about implementing the bulk mode in Informatica. Before the demonstration of bulk loading, the following pre-requisites have to be fulfilled.
Pre-requisites
For demonstrating bulk mode in Informatica, the database being used is DB2. An existing mapping with Normal mode will be used for bulk loading for better comparison. The table for which bulk load is being implemented will have the following features:
- Auto-generating Identity column
- Indexes
- Constraints
- Auto-generating timestamp column (row change timestamp)
The first step in bulk load implementation is creating the pre and post-session commands for dropping and re-creating the indexes, constraints and so on. Now let’s dive deep into the implementation.
Step 1: Informatica bulk loading does not work on a table with identity columns in it. Identify the identity columns in the table and remove them.

DB statement:
alter table schema_name.table_name alter column identity_column drop identity;
Step 2(a): Since Informatica bulk mode processes data in large packets, auto-generating features like sequence is not possible. Identify all the auto-generating columns in the table and drop them. In place of the auto-generating column like a surrogate key, a sequence generator should be used in the mapping level.
The auto-generating property of the surrogate key has to be dropped.
DB statement:
alter table schema_name.table_name alter column surrogate_key drop generated;
Step 2(b): The other auto-generating column in the table was a row change timestamp type. This feature automatically updates the timestamp column with the current timestamp when the record is updated or inserted.
The auto-generating property of the timestamp column has to be dropped.
DB statement:
alter table schema_name.table_name drop column timestamp_column;
Step 3: Indexes are not allowed for the table which will be loaded via the bulk mode approach. Identify all the indexes and constraints in the table, Make a list of pre and post commands for dropping and re-creating the indexes and constraints.
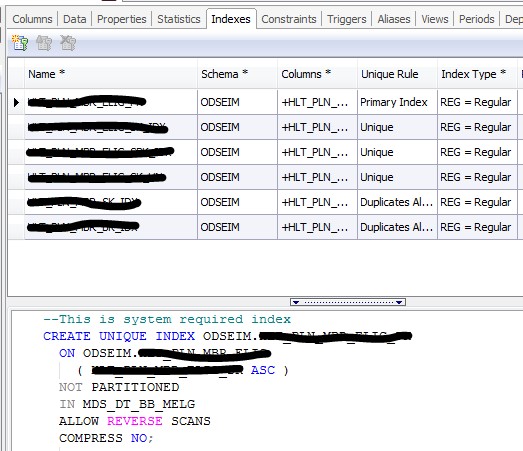
Identify all the Indexes of the table.
Pre-Session Database statements:
drop index schema_name.index_name1;
drop index schema_name.index_name2;
alter table schema_name.table_name alter foreign key constraint_name not enforced;
alter table schema_name.table_name
drop unique constraint_name;
Post-Session Database statements:
create unique index schema_name.index_name1
on schema_name.table_name ( index_name1 asc )
not partitioned in tablespace_name allow reverse scans compress no;
create unique index schema_name.index_name2
on schema_name.table_name ( index_name2 asc )
not partitioned in tablespace_name allow reverse scans compress no;
alter table schema_name.table_name alter foreign key constraint_name enforced;
alter table schema_name.table_name
add constraint constraint_name unique (column1, column2);
Challenges Faced During Implementation:
Once Steps 1-3 are implemented, the testing of the bulk-loading process was initiated. The execution of pre-session commands were completed successfully. The bulk fetch and loading were also completed successfully. However, during the execution of the post-session commands, the job failed with the error given below.
Error Message:
[IBM][CLI Driver][DB2/AIX64] SQL0668N Operation not allowed for reason code “1” on table “SCHEMA_NAME.TABLE_NAME”. SQLSTATE=57016
sqlstate = 57016
Cause of the error: The table is in the Set Integrity Pending No Access state. The integrity of the table is not enforced and the content of the table may be invalid. An operation on a parent table or an underlying table that is not in the Set Integrity Pending No Access state may also receive this error if a dependent table is in the Set Integrity Pending No Access state.
Solution: In order to change the table back to the Accessible state, the below database command was added to the post-session command list.
DB statement:
set integrity for schema_name.schema_name immediate checked;
I hope the above-mentioned information was sufficient for implementing Bulk mode in Informatica.
It’s Helped@@!!Got it Thnx
Thanks for the knowledge sharing.