
 As I woke up this morning and turned on the coffee maker, the buttons would not work. Trying the light switch, and the lights would not turn on. Sometime during the night my power went out. I realized this was the day to write about disaster recovery for Adobe Experience Manager, but in my case the blocker was not about my computer (plenty of battery), or Internet (thank you tethering), but about how to survive for the next few hours without a hot cup of coffee. Here goes.
As I woke up this morning and turned on the coffee maker, the buttons would not work. Trying the light switch, and the lights would not turn on. Sometime during the night my power went out. I realized this was the day to write about disaster recovery for Adobe Experience Manager, but in my case the blocker was not about my computer (plenty of battery), or Internet (thank you tethering), but about how to survive for the next few hours without a hot cup of coffee. Here goes.
When planning an Adobe Experience Manager on premise deployment, I always ask the the question “What is your tolerance for a site outage?” And the answer is almost always “None.” This is not surprising as I knew the answer before I asked the question.
It may seem obvious that loss of your ecommerce site, even temporarily, can be severely detrimental to sales. But the truth is that all types of businesses suffer–expectations are high that your site is always available or your corporate image may be tarnished. Why then is redundancy and disaster recovery not a part of all AEM stand-ups?
Cost? Most IT organizations have disaster recovery plans and initiatives in place, and when properly planned, an AEM infrastructure that is regionally fault tolerant is not necessarily an expensive proposition. Once I explain the options, it’ll be hard to say no.
Author Instances
First let’s look at a fault tolerant authoring instance. As you’ll see in other blog posts, I’m not a fan of Oak clustering as an answer for fault tolerance, and there are very specific use cases that need to be met before I’ll bless a 6.x clustering design. Clustering increases complexity, is slower than native TarMK and requires specialized DBAs to manage MongoDB instances. DBA resources that few customers have. With AEM 6.x there are other database options, but they require “Engineering / Support approval” and few, if any customers are actually running this in production. Do you want to be first?
A better alternative is to use the TarMK Cold Standby feature, spanning the standbys across physical data centers. Sure, a Cold Standby requires a short amount of downtime as they must be manually activated, but most organizations can tolerate Authoring outages for short periods of time.

Publish Instances
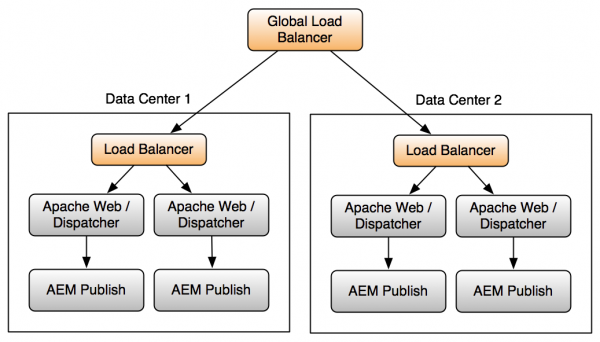
It’s simpler than you think. Load balanced publishers in multiple data centers protect against complete data center outages and if licensed, can provide increased capacity. A global load balancer can route traffic among data centers handing out IP addresses to visitors. Talk to your Adobe rep about licensing for instances that will be accepting traffic (an active/active scenario), versus instances that will only accept traffic in a disaster recovery situation (active/passive).
Configure dependent services like LDAP, SMTP and federated search with fallback when possible.
Creating a Disaster Recovery Plan
Your organization likely already has a disaster recovery plan template created for other projects, and may require you use the template when creating your AEM disaster recovery plan. Using a common template provides documentation consistency for system administrators while executing a plan in a real DR situation. Elements a disaster recovery plan should include:
- Basic information around the plan purpose, scope, objectives and strategies;
- Primary contacts and call lists;
- Hardware and software inventories with sizing, mounts, IP, DNS names, login information, and any other special information required to understand the platform;
- Infrastructure diagrams to visually show connectivity and interaction between devices, including port numbers, firewalls, IP addresses and DNS names;
- Upstream dependencies, how to validate and who to contact;
- Tasking orders with detailed recovery procedures, and return to normal procedures;
- Detailed testing procedures and the results when initially tested (always test your plan!);
When writing a disaster recovery plan, assume the reader knows literally nothing about the platform. This helps you write and test with clarity to help ensure success during recovery.
And yes, pouring hot water through a coffee filter into a cup does render a decent cup of coffee. Thank you. Disaster averted.
Adobe Resources