
As organizations accumulate massive amounts of structured and unstructured data, consequently, the need for flexible, scalable, and cost-effective data architectures becomes more important than ever. Moreover, with the increasing complexity of data environments, organizations must prioritize solutions that can adapt and grow. In addition, the demand for real-time insights and seamless integration across platforms further underscores the importance of robust data architecture. As a result, Data Lakehouse — combining the best of data lakes and data warehouses — comes into play. In this blog post, we’ll walk through how to build a serverless, pay-per-query Data Lakehouse using Amazon S3 and Amazon Athena.
What Is a Data Lakehouse?
A Data Lakehouse is a modern architecture that blends the flexibility and scalability of data lakes with the structured querying capabilities and performance of data warehouses.
- Data Lakes (e.g., Amazon S3) allow storing raw, unstructured, semi-structured, or structured data at scale.
- Data Warehouses (e.g., Redshift, Snowflake) offer fast SQL-based analytics but can be expensive and rigid.
Lakehouse unify both, enabling:
- Schema enforcement and governance
- Fast SQL querying over raw data
- Simplified architecture and lower cost
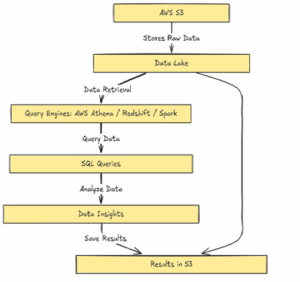
Tools We’ll Use
- Amazon S3: For storing structured or semi-structured data (CSV, JSON, Parquet, etc.)
- Amazon Athena: For querying that data using standard SQL
This setup is perfect for teams that want low cost, fast setup, and minimal maintenance.
Step 1: Organize Your S3 Bucket
Structure your data in S3 in a way that supports performance:
s3://Sample-lakehouse/
└── transactions/
└── year=2024/
└── month=04/
└── data.parquet

Best practices:
- Use columnar formats like Parquet or ORC
- Partition by date or region for faster filtering
- In addition, compressing files (e.g., Snappy or GZIP) can help reduce scan costs.
Step 2: Create a Table in Athena
You can create an Athena table manually via SQL. Athena uses a built-in Data Catalog
CREATE EXTERNAL TABLE IF NOT EXISTS transactions (
transaction_id STRING,
customer_id STRING,
amount DOUBLE,
transaction_date STRING
)
PARTITIONED BY (year STRING, month STRING)
STORED AS PARQUET
LOCATION ‘s3://sample-lakehouse/transactions/’;
Then run:
MSCK REPAIR TABLE transactions;
This tells Athena to scan the S3 directory and register your partitions.
Step 3: Query the Data
Once the table is created, querying is as simple as:
SELECT year, month, SUM(amount) AS total_sales
FROM transactions
WHERE year = ‘2024’ AND month = ’04’
GROUP BY year, month;
Benefits of This Minimal Setup
| Benefit | Description |
| Serverless | No infrastructure to manage |
| Fast Setup | Just create a table and query |
| Cost-effective | Pay only for storage and queries |
| Flexible | Works with various data formats |
| Scalable | Store petabytes in S3 with ease |
Building a data Lakehouse using Amazon S3 and Athena offers a modern, scalable, and cost-effective approach to data analytics. With minimal setup and no server management, you can unlock insights from your data quickly while maintaining flexibility and governance. Furthermore, this streamlined approach reduces operational overhead and accelerates time-to-value. Whether you’re a startup or an enterprise, this setup provides the foundation for data-driven decision-making at scale. In fact, it empowers teams to focus more on innovation and less on infrastructure.