
Snowflake’s Stream
Stream
Stream is a CHANGE DATA CAPTURE methodology in Snowflake; it records the DML changes made to tables, including (Insert/Update/delete). When a stream is created for a table, it will create a pair of hidden columns to track the metadata.
create or replace stream s_emp on table emp append_only=false;
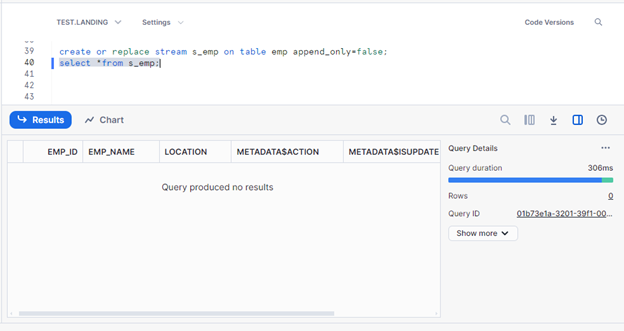
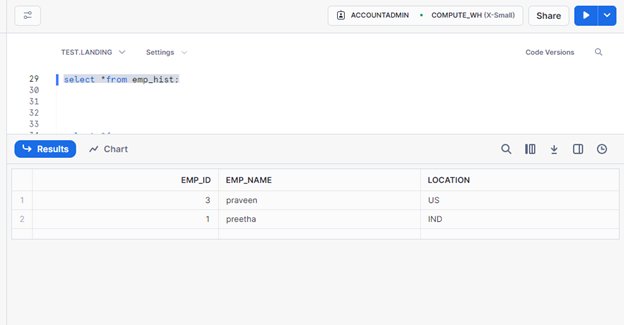
I have two tables, emp and emp_hist. Emp is my source table, and emp_hist will be my target.
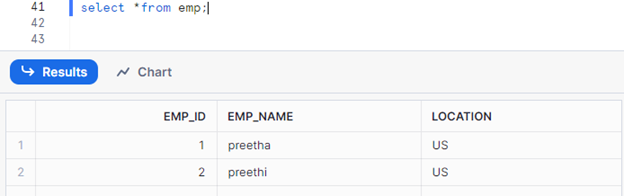
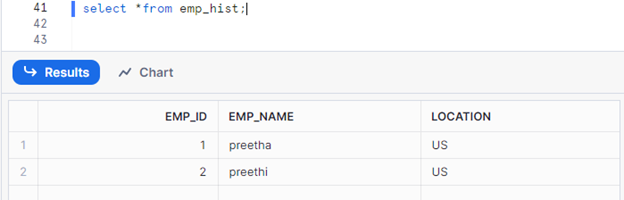
Now, I will insert a new row in my source table to capture the data in my stream.
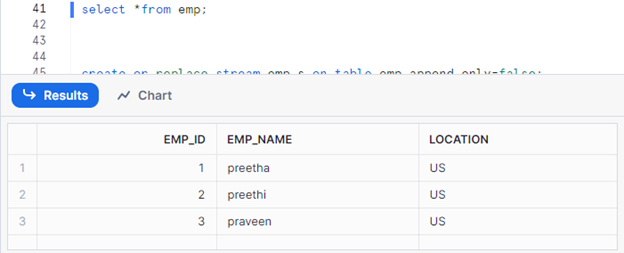
Let’s see our stream result.
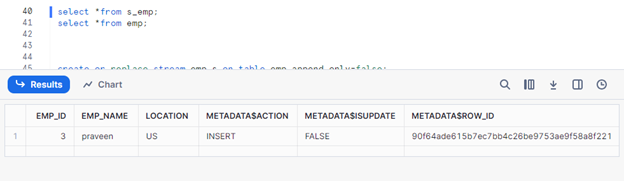
In the same way, I’m going to delete and update my source table.
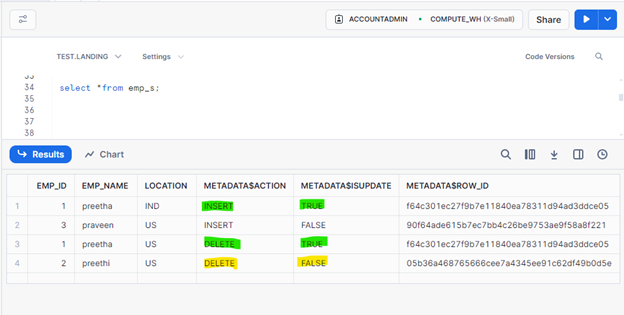
I deleted one record and made an update in a row, but here in the stream, we could see two deleted actions.
- The first delete action was for the row that I deleted, and the second one is for the row that I updated.
- If the row is deleted from the source, the stream will capture the METADATA$ACTION as DELETE and METADATA@ISUPDATE as FALSE.
- If the row is updated in the source, the stream will capture both the delete and insert actions, so it will capture the old row as delete and the updated row as insert.
Create a Merge Query to Store the Stream Data into the Final Table
I’m using the below merge query to capture the newly insert and updated record (SCD1) into my final table.
merge into emp_hist t1
using (select * from s_emp where not(METADATA$ACTION=’DELETE’ and METADATA$ISUPDATE=’TRUE’) ) t2
on t1.emp_id=t2.emp_id

when matched and t2.METADATA$ACTION=’DELETE’ and METADATA$ISUPDATE=’FALSE’ then delete
when matched and t2.METADATA$ACTION=’INSERT’ and METADATA$ISUPDATE=’TRUE’
then update set t1.emp_name=t2.emp_name, t1.location=t2.location
when not matched then
insert (emp_id,emp_name,location) values(t2.emp_id,t2.emp_name,t2.location);

Query for SCD2
BEGIN;
update empl_hist t1
set t1.emp_name=t2.emp_name , t1.location=t2.location,t1.end_date=current_timestamp :: timestamp_ntz
from (select emp_id,emp_name,location from s_empl where METADATA$ACTION=’DELETE’) t2
where t1.emp_id=t2.emp_id;
insert into empl_hist select t2.emp_id,t2.emp_name,t2.location,current_timestamp,NULL
from s_empl t2 where t2.METADATA$ACTION=’INSERT’;
commit;
Tasks
Tasks use user-defined functions to automate and schedule business processes. A single task can perform a simple to complex function in your data pipeline.
I have created a task for the above-mentioned merge query. Instead of running this query manually every time, we can create a task. Here, I have added a condition system$stream_has_data(’emp_s’) in my task creation. So, if data is available in the stream, then the task will run and load it to the target table, or else it will be skipped.
create task mytask warehouse=compute_wh
schedule=’1 minute’ when
system$stream_has_data(’emp_s’)
as merge into emp_hist t1
using (select * from emp_s where not(METADATA$ACTION=’DELETE’ and METADATA$ISUPDATE=’TRUE’) ) t2
on t1.emp_id=t2.emp_id
when matched and t2.METADATA$ACTION=’DELETE’ and METADATA$ISUPDATE=’FALSE’ then delete
when matched and t2.METADATA$ACTION=’INSERT’ and METADATA$ISUPDATE=’TRUE’
then update set t1.emp_name=t2.emp_name, t1.location=t2.location
when not matched then
insert (emp_id,emp_name,location) values(t2.emp_id,t2.emp_name,t2.location);