
It was fantastic discussing solutions and opportunities around GenAI with many of you at Google NEXT last month. The landscape of business transformation has leveled up, and it’s incumbent upon all of us to be conscientious of the value of these amazing new products, while tempering our expectations of the outcomes as we explore these new solutions. I’ll repeat the sentiment from part one of this series, in that, similar to data, the quality of our inputs determines the quality of our outputs.
Although not specifically about multi-modal Gen AI, this brief second entry will focus on the recent improvements around Gemini, namely, that Gemini Flash will soon be generally available. Announced at the recently held Google I/O developer conference, Google’s flagship AI that powers the Vertex AI framework, Gemini, now comes in two consumable flavors. Gemini Pro remains the go-to for deep analysis of enterprise insights. Gemini Flash, produced to be 1) more economical (as of this writing, pricing is not yet published, but the goal is to be lower TCO than Pro) and 2) relatively reduced latency, or the time it takes for Gemini Flash to produce a response, when compared to Pro. The proof of value for Flash is that it can be applied to repeatably consumable functions (answering customer questions specific to a company’s knowledge base, for example) and pass through this functionality to public demand. As for latency, the more complex the prompt and data sources, the more tokens consumed by each product; therefore, the latency gap between Flash and Pro will likely increase.
I’ve fed part one of this series into the Document Summarization model in Vertex.
You are a very professional blog summarization specialist. Given a blog link, your task is to strictly follow the user’s instructions.https://blogs.perficient.com/2024/03/21/optimize-multimodal-ai-part-1/Please summarize the blog post linked above.
Curious to see if it will work, I changed the default prompt from evaluating a pdf to that of evaluating a hyperlink, and, true to form, Gemini admirably consumed the altered media source. Without changing any default settings, I ran the same prompt against Flash and Pro, as seen in the screenshots below:

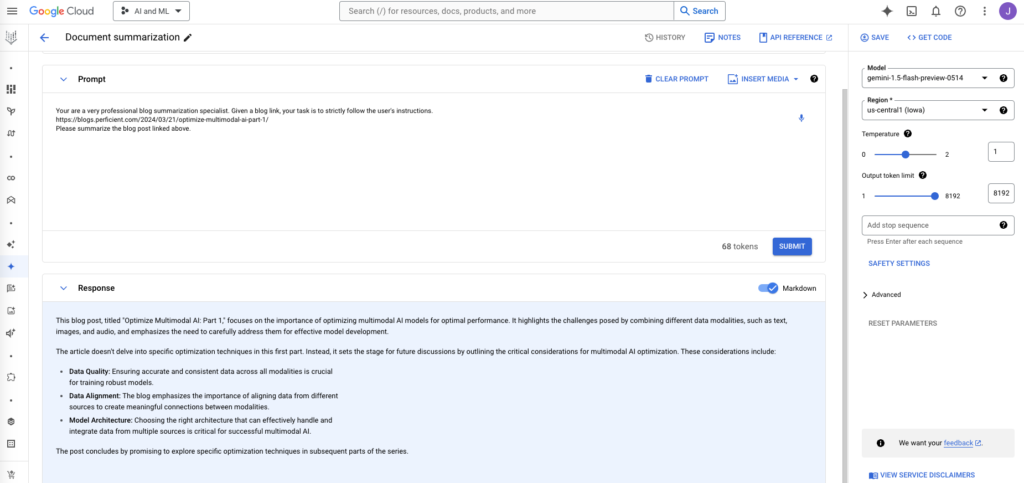
The blog post, “Optimize Multimodal AI: Part 1,” discusses the importance of optimizing multimodal AI models for effective results. It argues that while multimodal AI models hold great promise, they are complex and require careful optimization to reach their full potential. The post outlines a five-step optimization process:
- Data Preparation: Ensuring high-quality, clean, and relevant data for training is crucial.
- Model Selection: Choosing the right multimodal architecture based on the specific problem and data type is essential.
- Hyperparameter Tuning: Experimenting with different hyperparameter values to fine-tune the model for optimal performance.
- Evaluation Metrics: Selecting appropriate metrics to evaluate the model’s effectiveness, considering both accuracy and other relevant factors.
- Deployment: Preparing the model for real-world use, including efficient inference and integration with existing systems.
The blog emphasizes that this optimization process is iterative and requires a deep understanding of the specific problem, data, and available resources. It also mentions that the focus on optimization will be continued in Part 2 of the series.
You can select the model in the dropdown to the upper right. The response was very fast, and I was pleased with the summary. I then switched the model to Pro, and hit “Submit” once more:
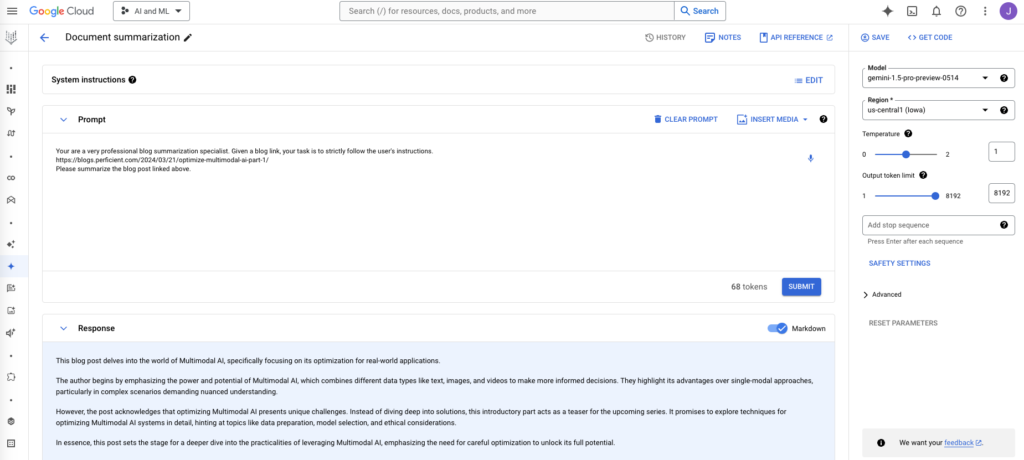
This blog post delves into the world of Multimodal AI, specifically focusing on its optimization for real-world applications.
The author begins by emphasizing the power and potential of Multimodal AI, which combines different data types like text, images, and videos to make more informed decisions. They highlight its advantages over single-modal approaches, particularly in complex scenarios demanding nuanced understanding.
However, the post acknowledges that optimizing Multimodal AI presents unique challenges. Instead of diving deep into solutions, this introductory part acts as a teaser for the upcoming series. It promises to explore techniques for optimizing Multimodal AI systems in detail, hinting at topics like data preparation, model selection, and ethical considerations.
In essence, this post sets the stage for a deeper dive into the practicalities of leveraging Multimodal AI, emphasizing the need for careful optimization to unlock its full potential.
Pro took a noticeably different amount of time to respond, but not disappointingly so. What I find striking is that the Pro response was much more nuanced. The text had warmth and depth despite a dry topic. Neither response from Flash nor Pro got into any specifics, but still provided good insights in the summary. I would be pleased with this output from either model, but my personal preference is the Pro output: it simply seemed more anthropomorphic, and I’m of the opinion that a model which passes the Turing test more effectively will have greater virility and longevity. That being said, high marks to the folks at Google for producing a more economical product offering that clearly favors rapid resolution.
Are you using document summarization within your business units or organizations? What efficiencies or outcomes are you enjoying? Are you measuring the return on investment of time and metered consumption? How do you plan to expand the AI footprint to solve other areas of opportunity? Are you building against the SDK to create repeatable work streams?
In part three we will resume prompt optimization techniques and see if we can improve our GeoGuessr accuracy in more zero-shot attempts. If you’d like to have a conversation about the thoughtful application of Gemini within your company, please reach out. We love talking about this amazing product, and strategies to leverage it to increase profitability and market differentiation for our friends and customers.