
You’ll find plenty of articles about how amazing GraphQL is (including mine), but after some time of using it, I’ve got some considerations with the technology and want to share some bitter thoughts about it.
![Gq Image[1]](https://blogs.perficient.com/files/gq-image1-1-300x87.png)
History of GraphQL
How did it all start? The best way to answer this question is to go back to the original problem Facebook faced.
Back in 2012, we began an effort to rebuild Facebook’s native mobile applications. At the time, our iOS and Android apps were thin wrappers around views of our mobile website. While this brought us close to a platonic ideal of the “write once, run anywhere” mobile application, in practice, it pushed our mobile web view apps beyond their limits. As Facebook’s mobile apps became more complex, they suffered poor performance and frequently crashed. As we transitioned to natively implemented models and views, we found ourselves for the first time needing an API data version of News Feed — which up until that point had only been delivered as HTML.
We evaluated our options for delivering News Feed data to our mobile apps, including RESTful server resources and FQL tables (Facebook’s SQL-like API). We were frustrated with the differences between the data we wanted to use in our apps and the server queries they required. We don’t think of data in terms of resource URLs, secondary keys, or join tables; we think about it in terms of a graph of objects.
Facebook came across a specific problem and created its own solution: GraphQL. To represent data in the form of a graph, the company designed a hierarchical query language. In other words, GraphQL naturally follows the relationships between objects. You can now receive nested objects and return them all in a single HTTPS request. Back in the day, it was crucial for global users not to always have cheap/unlimited mobile tariff plans, so the GraphQL protocol was optimized, allowing only what users needed to be transmitted.
Therefore, GraphQL solves Facebook’s problems. Does it solve yours?
First, let’s recap the advantages
- Single request, multiple resources: Compared to REST, which requires multiple network requests to be made to each endpoint, with GraphQL you can request all resources with a single call.
- Receive accurate data: GraphQL minimizes the amount of data transferred over the wires, selectively selecting it based on the needs of the client application. Thus, a mobile client with a small screen may receive less information.
- Strong typing: Every request, input, and response objects have a type. In web browsers, the lack of types in JavaScript has become a weakness that various tools (Google’s Dart, and Microsoft’s TypeScript) try to compensate for. GraphQL allows you to exchange types between the backend and frontend.
- Better tooling and developer friendliness: The introspective server can be queried about the types it supports, allowing for API explorer, autocompletion, and editor warnings. No more relying on backend developers to document their APIs. Simply explore the endpoints and get the data you need.
- Version independent: the type of data returned is determined solely by the client request, so servers become simpler. When new server-side features are added to the product, new fields can be added without affecting existing clients.
Thanks to the “single request, multiple resources” principle, front-end code has become much simpler with GraphQL. Imagine a situation where a user wants to get details about a specific writer, for example (name, id, books, etc.). In a traditional intuitive REST pattern, this would require a lot of cross-requests between the two endpoints /writers and /books, which the frontend would then have to merge. However, thanks to GraphQL, we can define all the necessary data in the request, as shown below:
writers(id: "1") {
id
name
avatarUrl
books(limit: 2) {
name
urlSlug
}
}
The main advantage of this pattern is to simplify the client code. However, some developers expected to use it to optimize network calls and speed up application startup. You don’t make the code faster; you simply transfer the complexity to the backend, which has more computing power. Also for many scenarios, metrics show that using the REST API appeared faster than GraphQL.
This is mostly relevant for mobile apps. If you’re working with a desktop app or a machine-to-machine API, there’s no added value in terms of performance.
Another point is that you may indeed save some kilobytes with GraphQL, but if you really want to optimize loading times, it’s better to focus on loading lower-quality images for mobile, as we’ll see, GraphQL doesn’t work very well with documents.
But let’s see what actually is wrong or could be better with GraphQL.
Strongly Typing

GraphQL defines all API types, commands, and queries in the graphql.schema file. However, I’ve found that typing with GraphQL can be confusing. First of all, there is a lot of duplication here. GraphQL defines the type in the schema, however we need to override the types for our backend (TypeScript with node.js). You have to spend additional effort to make it all work with Zod or create some cumbersome code generation for types.
Debugging
It’s hard to find what you’re looking for in the Chrome inspector because all the endpoints look the same. In REST you can tell what data you’re getting just by looking at the URL:
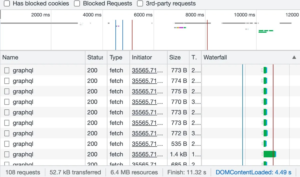
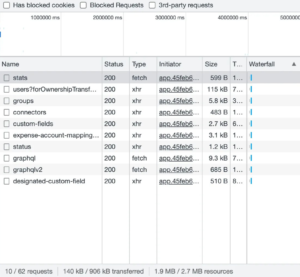
Do you see the difference?
No support for status codes
REST allows you to use HTTP error codes like “404 not found”, “500 server error” and so on, but GraphQL does not. GraphQL forces a 200 error code to be returned in the response payload. To understand which endpoint failed, you need to check each payload. Same applies for Monitoring: HTTP error monitoring is very easy compared to GraphQL because they all have their own error code while troubleshooting GraphQL requires parsing JSON objects.
Additionally, some objects may be empty either because they cannot be found or because an error occurred. It can be difficult to distinguish the difference at a glance.
Versioning
Everything has its price. When modifying the GraphQL API, you can make some fields obsolete, but you are forced to maintain backward compatibility. They should still remain there for older clients who use them. You don’t need to support GraphQL versioning, at the price of maintaining each field.
To be fair, REST versioning is also a pain point, but it does provide an interesting feature for expiring functionality. In REST, everything is an endpoint, so you can easily block legacy endpoints for a new user and measure who is still using the old endpoint. Redirects could also simplify versioning from older to newer in some cases.
Pagination
GraphQL Best Practices suggests the following:
The GraphQL specification is deliberately silent on several important API-related issues, such as networking, authorization, and pagination.
How “convenient” (not!). In general, as it turns out, pagination in GraphQL is very painful.
Caching
The point of caching is to receive a server response faster by storing the results of previous calculations. In REST, the URLs are unique identifiers of the resources that users are trying to access. Therefore, you can perform caching at the resource level. Caching is a part of HTTP specification. Additionally, the browser and mobile device can also use this URL and cache the resources locally (same as they do with images and CSS).
In GraphQL this gets tricky because each query can be different even though it’s working on the same entity. It requires field-level caching, which is not easy to do with GraphQL because it uses a single endpoint. Libraries like Prisma and Dataloader have been developed to help with such scenarios, but they still fall short of REST capabilities.
Media types
GraphQL does not support uploading documents to the server, which is used multipart-form-data by default. Apollo developers have been working on a file-uploads solution, but it is difficult to set up. Additionally, GraphQL does not support a media types header when retrieving a document, which allows the browser to display the file correctly.
I previously made a post about the steps one must take in order to upload an image to Sitecore Media Library (either XM Cloud or XM 10.3 or newer) by using Authoring GraphQL API.
Security
When working with GraphQL, you can query exactly what you need, but you should be aware that this comes with complex security implications. If an attacker tries to send a costly request with attachments to overload the server, then may experience it as a DDoS attack.
They will also be able to access fields that are not intended for public access. When using REST, you can control permissions at the URL level. For GraphQL this should be the field level:
user {
username <-- anyone can see that
email <-- private field
post {
title <-- some of the posts are private
}
}
Conclusion
REST has become the new SOAP; now GraphQL is the new REST. History repeats itself. It’s hard to say whether GraphQL will just be a popular new trend that will gradually be forgotten, or whether it will truly change the rules of the game. One thing is certain: it still requires some development to obtain more maturity.


