
A common symptom of organizations operating at suboptimal performance is when there is a prevalent challenge of dealing with data fragmentation. The fact that enterprise data is siloed within disparate business and operational systems is not the crux to resolve, since there will always be multiple systems. In fact, businesses must adapt to an ever-growing need for additional data sources. However, with this comes the challenge of mashing up data across systems to provide a holistic view of the business. This is the case for example for a customer 360 view that provides insight into all aspects of customer interactions, no matter where that information comes from, or whether it’s financial, operational or customer experience related. In addition, data movements are complex and costly. Organizations need the agility to adapt quickly to the additional sources, while maintaining a unified business view.
Data Virtualization As a Key Component Of a Data Fabric
That’s where the concept of data virtualization provides an adequate solution. Data stays where it is, but we report on it as if it’s stored together. This concept plays a key role in a data fabric architecture which aims at isolating the complexity of data management and minimizing disruption for data consumers. Besides data-intensive activities such as data storage management and data transformation, a robust data fabric requires a data virtualization layer as a sole interfacing logical layer that integrates all enterprise data across various source applications. While complex data management activities may be decentralized across various cloud and on-premises systems maintained by various teams, the virtual layer provides a centralized metadata layer with well-defined governance and security.
How Does This Relate To a Data Mesh?
What I’m describing here is also compatible with a data mesh approach whereby a central IT team is supplemented with products owners of diverse data assets that relate to various business domains. It’s referred to as the hub-and-spoke model where business domain owners are the spokes, but the data platforms and standards are maintained by a central IT hub team. Again, the data mesh decentralizes data assets across different subject matter experts but centralizes enterprise analytics standards. Typically, a data mesh is applicable for large scale enterprises with several teams working on different data assets. In this case, an advanced common enterprise semantic layer is needed to support collaboration among the different teams while maintaining segregated ownerships. For example, common dimensions are shared across all product owners allowing them to report on the company’s master data such as product hierarchies and organization rollups. But the various product owners are responsible for consuming these common dimensions and providing appropriate linkages within their domain-specific data assets, such as financial transactions or customer support requests.
Oracle Analytics for Data Virtualization

Data Virtualization is achieved with the Oracle Analytics Enterprise Semantic Model. Both the Cloud version, Oracle Analytics Cloud (OAC) and the on-premises version, Oracle Analytics Server (OAS), enable the deployment of the semantic model. The semantic model virtualizes underlying data stores to simplify data access by consumers. In addition, it defines metadata for linkages across the data sources and enterprise standards such as common dimensions, KPIs and attribute/metric definitions. Below is a schematic of how the Oracle semantic model works with its three layers.
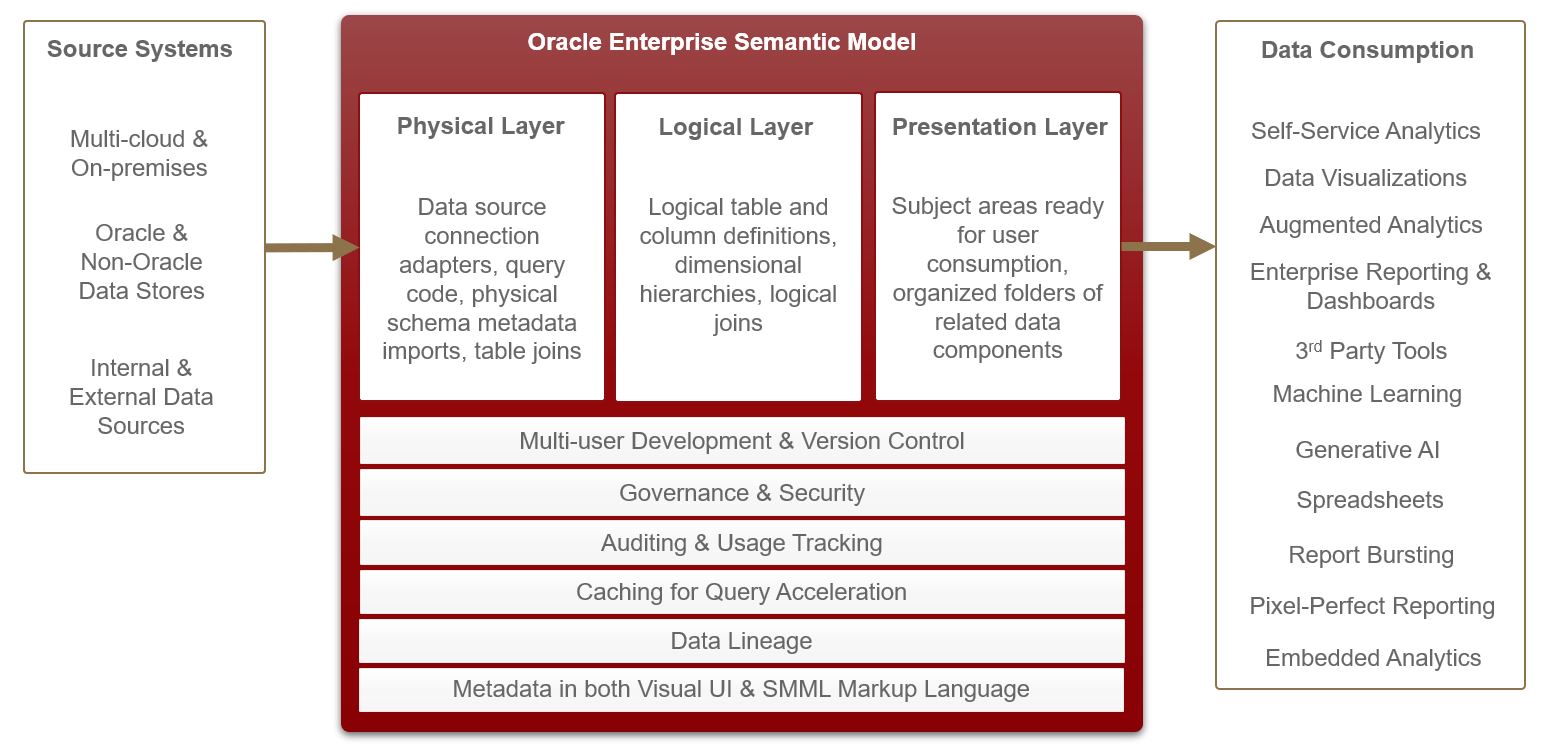
Outcomes of Implementing the Oracle Semantic Model
Whether you have a focused data intelligence initiative or a wide-scale program covering multi-cloud and on-premises data sources, the common semantic model has benefits in all cases, for both business and IT.
- Enhanced Business Experience
With Oracle data virtualization, business users tap into a single source of truth for their enterprise data. The information available out of the Presentation Layer is trusted and is reported on reliably, no matter what front end reporting tool is used: such as self-service data visualization, dashboards, MS Excel, Machine Learning prediction models, Generative AI, or MS Power BI.
Another value-add for the business is that they can access new data sources quicker and in real-time now that the semantic layer requires no data movement or replication. IT can leverage the semantic model to provide this access to the business quickly and cost-effectively.
- Future Proof Investment
The three layers that constitute the Oracle semantic model provide an abstraction of source systems from the presentation layer accessible by data consumers. Consequently, as source systems undergo modernization initiatives, such as cloud migrations, upgrades and even replacement with totally new systems, data consuming artifacts, such as dashboards, alerts, and AI models remain unaffected. This is a great way for IT to ensure any analytics investment’s lifespan is prolonged beyond any source system.
- Enterprise Level Standardization
The semantic model enables IT to enforce governance when it comes to enterprise data shared across several departments and entities within an organization. In addition, very fine-grained object and data levels security configurations are applied to cater for varying levels of access and different types of analytics personas.
Connect with us for consultation on your data intelligence and business analytics initiatives.