
Spark Persistence is an optimization technique, which saves the results of RDD evaluation. Spark provides a convenient method for working with datasets by storing them in memory throughout various operations. When you persist a dataset, Spark stores the data on disk or in memory, or a combination of the two, so that it can be retrieved quickly the next time it is needed. It reduces the computation overhead.
Methods Of Persistence Storage Levels
We can Persist RDD in two ways. One is cache() and other is persist(). Caching or persisting a Spark DataFrame or Dataset is a lazy operation, implying that the DataFrame won’t be cached until you initiate an action. This lazy approach to caching allows Spark to optimize the execution plan and avoid unnecessary caching of intermediate data that may not be used in subsequent computations. It helps in efficiently utilizing resources and improving overall performance.
Cache()
cache() method by default saves it to MEMORY_AND_DISK storage level where as with persist() method we can persist data on multiple storage levels.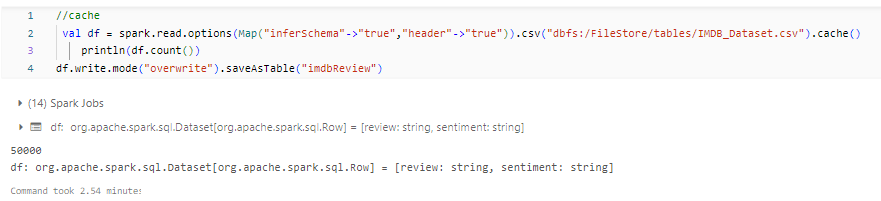
Persist()

The persist method is used to persist an RDD (Resilient Distributed Dataset) or DataFrame in memory so that it can be reused efficiently across multiple Spark operations. The persist() method can be used to specify the level of storage for the persisted data. The available storage levels include MEMORY_ONLY, MEMORY_ONLY_SER, MEMORY_AND_DISK, MEMORY_AND_DISK_SER, DISK_ONLY, and OFF_HEAP. The MEMORY_ONLY and MEMORY_ONLY_SER levels store the data in memory, while the MEMORY_AND_DISK and MEMORY_AND_DISK_SER levels store the data in memory and on disk. The DISK_ONLY level stores the data on disk only, while the OFF_HEAP level stores the data in off-heap memory.
When you use the persist() method without specifying a storage level, it defaults to MEMORY_ONLY storage level. 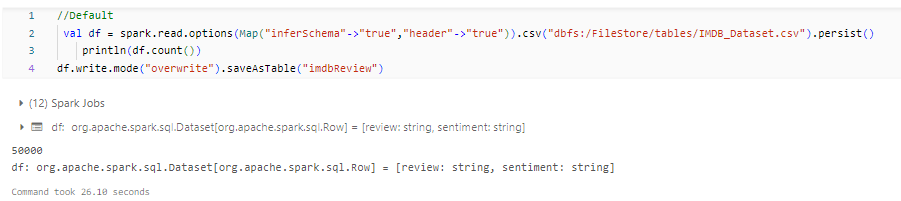
Types of Storage levels
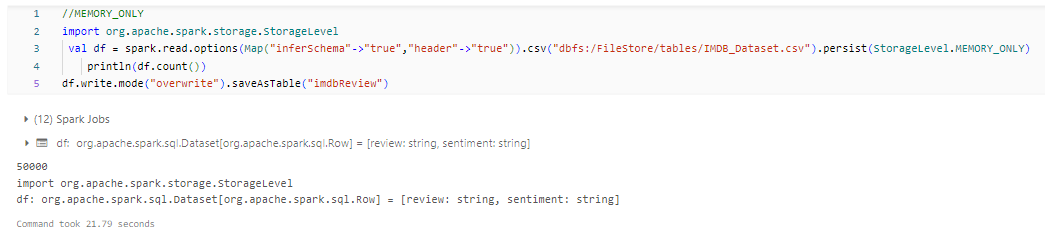
- MEMORY_ONLY: This storage level stores the RDD or DataFrame as deserialized Java objects in the JVM heap. This provides fast access to the data but consumes more memory.
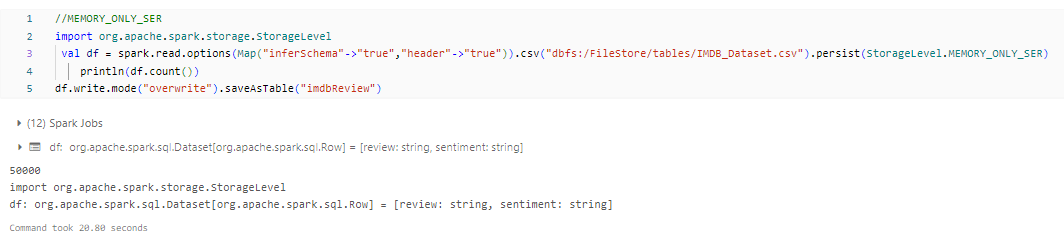
- MEMORY_ONLY_SER: This is the same as MEMORY_ONLY but the difference being it stores RDD as serialized objects to JVM memory. This reduces memory usage but requires deserialization when the data is accessed.
- MEMORY_AND_DISK: It stores partitions that do not fit in memory on disk and keeps the rest in memory. This can be useful when working with datasets that are larger than the available memory.
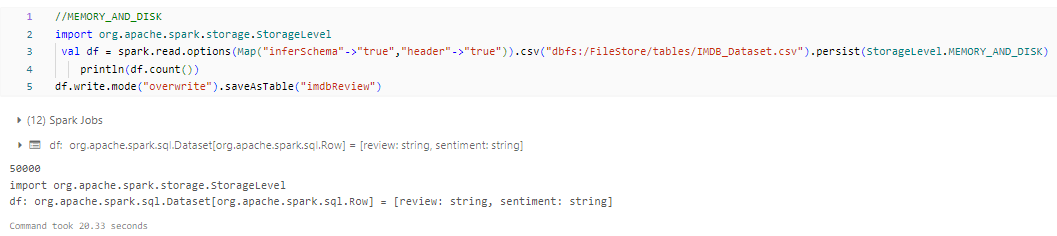
- MEMORY_AND_DISK_SER: Similar to MEMORY_AND_DISK, but stores serialized Java objects on disk.
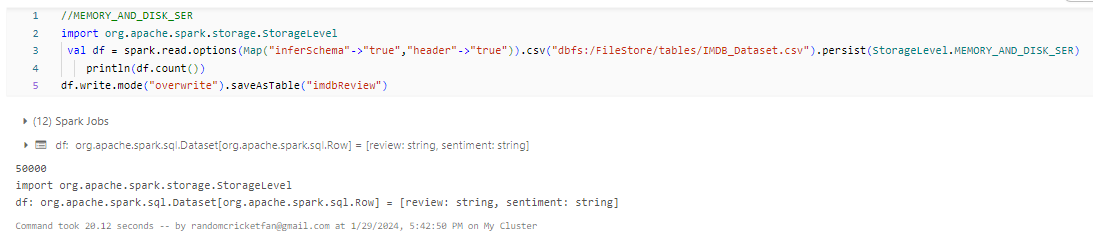
- DISK_ONLY: Data is stored only on disk, and it is read into memory on-demand when accessed. This storage level has the least memory usage but may result in slower access times.
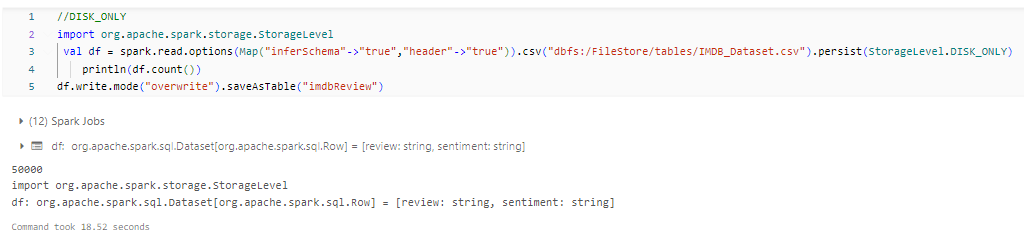
- OFF_HEAP: The data is stored off the JVM heap in serialized form. This can be useful for large data sets that do not fit into the heap.
These examples illustrate the use of different storage levels with the persist method in Spark Scala, showcasing how to cache RDDs in memory or on disk for better performance in subsequent Spark operations. These storage levels provide flexibility in managing the trade-off between performance and memory usage based on your specific needs and available resources. Choose the storage level based on your specific use case and the characteristics of your data.
When to Use What
- Use MEMORY_ONLY or MEMORY_ONLY_SER when:
-
- Sufficient memory is available.
- Minimal CPU overhead is desired.
- No need for data spill to disk.
- Use MEMORY_AND_DISK or MEMORY_AND_DISK_SER when:
-
- Memory is limited.
- A balance between memory usage and CPU time is required.
- Some data can be spilled to disk.
- Use DISK_ONLY when:
-
- The dataset is too large to fit in memory.
- Disk I/O is acceptable.
- Recomputation is acceptable.
Which is the Best Method
There is no one-size-fits-all answer; the best method depends on your specific use case.
- Considerations:
-
- If you have enough memory to store the entire dataset, MEMORY_ONLY is efficient.
- If memory is a concern, MEMORY_AND_DISK or MEMORY_AND_DISK_SER provide a balance.
- Use DISK_ONLY only when the dataset is extremely large and cannot fit in memory.
- Trade-offs:
-
- MEMORY_ONLY and MEMORY_ONLY_SER provide the best performance when the data fits entirely in memory.
- MEMORY_AND_DISK and MEMORY_AND_DISK_SER offer a trade-off between memory usage and recomputation speed.
- DISK_ONLY is suitable for very large datasets but comes with increased recomputation time.
Unpersist RDD in Spark
When you persist a dataset in Spark, it will store the data in the specified storage level until you explicitly remove it from memory or disk. You can remove a persisted dataset using the unpersist() method. 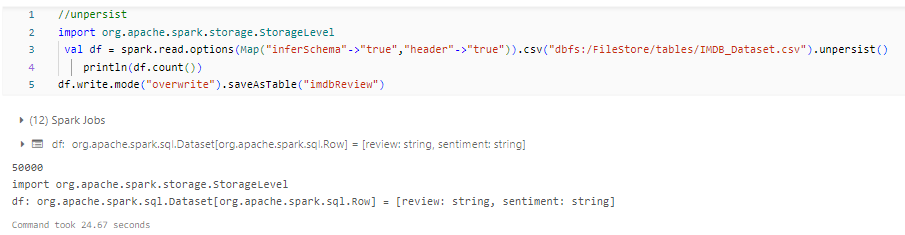
Conclusion
Utilizing caching and persistence in Spark constitutes effective mechanisms for accelerating data processing. Caching or persisting a dataset allows you to keep the data in memory or on disk, enabling quick retrieval the next time you need it. These methods prove particularly advantageous when dealing with repetitive operations on the same dataset. However, being safe is advised during the caching or persisting process, as it may result in Considerable amount of memory or disk space consumption. Strategic prioritization of datasets for caching or persistence is crucial, and it should be based on their significance within your processing workflow.