
Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams. AWS Glue consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries.
AWS Glue works with structured and semi-structured data very well. It is serverless, there’s no infrastructure to set up or manage. A dynamic frame is introduced, which you can use in your ETL scripts.
Classifiers
Classifier specify the schema for a specific file type.
Connections
Connections store the required connection metadata to establish the connection between glue and the source.
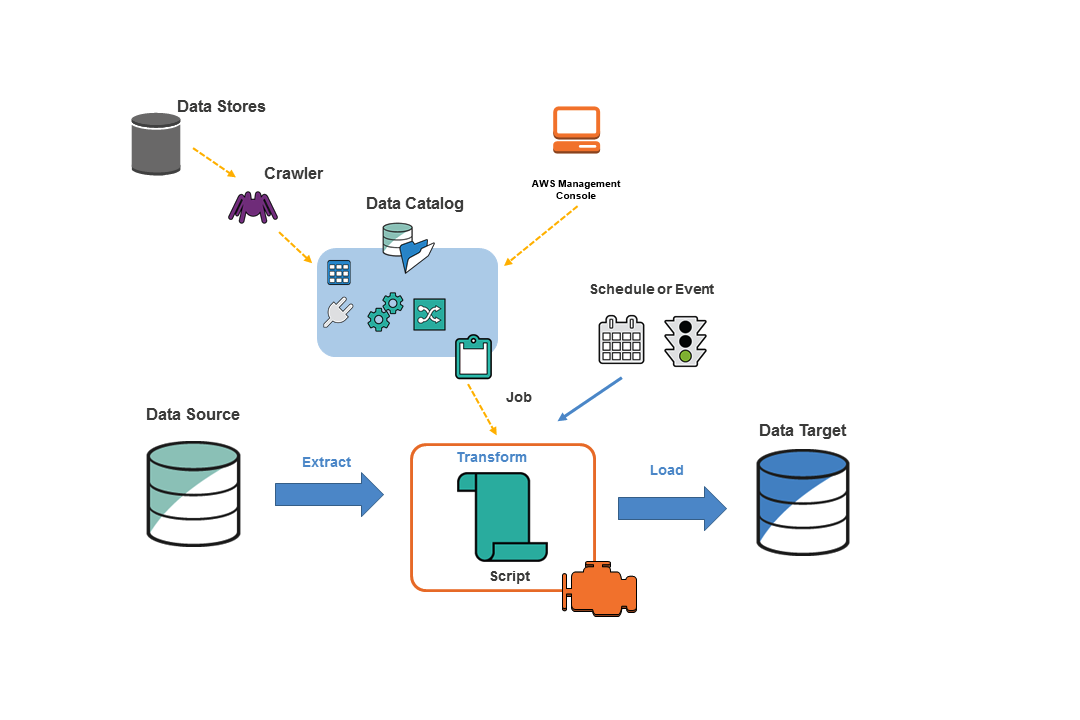
Crawlers
A crawler scans a folder and compares it to classifiers to identify the source file. In case your crawler runs more than once, it will look for newly created or changed files or tables in your data store.
Data catalog

Glue jobs can access data from Data Catalog, a central repository in AWS.
Cloud Watch
It is monitoring service provided by AWS to keep tract of the activities.
Workflow
The workflow runs the artifacts in a sequential manner defined by the user.
Glue Jobs
The AWS Glue job is a script that connects to the source data, processes it, and writes it to the target data. Glue job uses the python and scala language. AWS Glue can write output files in several data formats, including JSON, CSV, ORC (Optimized Row Columnar), Apache Parquet, and Apache Avro.
-
- There are three types of jobs in Glue: Spark, Streaming ETL, and Python shell.
- Streaming ETL: A streaming ETL job is similar to a Spark job, except that it performs ETL on data streams. It uses the Apache Spark Structured Streaming framework. Some Spark job features are not available to streaming ETL jobs.
- Python shell: A Python shell job runs Python scripts as a shell and supports a Python version that depends on the AWS Glue version you are using. You can use these jobs to schedule and run tasks that don’t require an Apache Spark environment.
- Spark: AWS Glue manage spark job running in an Apache Spark environment. In Spark jobs, scripts can be defined as follows:
- Build in Scripts
- Adding glue job (already written in local and uploading it)
- Editing the spark script in the AWS glue.
For Creating the glue job, we need to define some parameters:
-
- Job Name
- Source data
- Worker type
- Number Workers
- Spark version
For more info you can go through the documentation of AWS .
Happy coding!
Nice !
Very well explained. Good Job Akshay!!
Very Informative Akshay.
Good blog!!!
Very Informative blog. Keep it up!!