
The Azure Well-Architected Framework was introduced in July of 2020 to help manage the growing complexity of the cloud.
The framework consists of five pillars of architectural excellence:
The pillars of the framework can rarely be implemented individually. As you continue to grow the functional capability of your workloads, the impact it has on the system can be profound. Cost Optimization must be balanced against Performance Efficiency. Conversely, Operational Excellence may complement and enhance Performance Efficiency.
The Azure Well-Architected Framework is a powerful group of tools. Once the workload is in production Azure provides the Azure Advisor to understand changes that occur as features and services are added, so it’s a good practice to review your workloads regularly, and use Azure’s monitoring tools on critical workloads.
Performance Efficiency Pillar – an example
“If the only tool you have is a hammer, it’s hard to eat spaghetti.” ~ David Allen.
The following scenario represents an Azure client’s requirement for Performance targeting the design of a RESTful API service with a requirement for throughput. This requirement was balanced against opposing requirements of Reliability and Cost.
Reliability Patterns are necessary to increase system availability but generally include retry mechanisms that are invisible to the user and are not available in correlation data, therefore perceived performance goes down. Retries or other reliability patterns will log the occurrence and length of time to identify the drop in performance.
Cost can be affected based on the need to scale resource instances. If traffic increases and it is unexpected then the scaling will increase cost, or the cost ceiling configured in Azure would prevent sufficient scaling to meet performance requirements.
Let’s use a scenario with a distributed cloud architecture. I’ll also cover some additional tools like k6, Postman, WireMock, Faker, and Azure Application Insights that were employed and become new tools for your toolbox.
The Challenge of Distributed Architectures
“I don’t need a hard disk in my computer if I can get to the server faster… carrying around these non-connected computers is byzantine by comparison.” ~ – Steve Jobs, Co-founder, former CEO, and Chairman, Apple Inc.
You might have guessed by now that our focus will be a client scenario using a globally distributed architecture, operational data collection, and instrumentation. This scenario uses Azure Application Insights, a feature of Azure Monitor. We are creating a dashboard displaying queried data to identify issues affecting interdependent systems, including the performance of the target solution. Our goal is performance efficiency, which is achieved by matching an application’s available resources against a demand for those resources.
Returning to our project scenario, it uses Azure App Services as its client-facing API resource. There are several reasons for this decision that are out of the scope of our Performance Pillar. However, Azure App Services is a natural design selection for our requirements. With most other options, you would need to instrument your app with Azure App Insights, but App Services has the App Insights Agent integrated by default. By selecting this option, the app has runtime monitoring by default. Installing the App Insights SDK provides extra flexibility but was not required for the project scenario.
Our scenario, if you recall, has a distributed architecture. Our instrumentation has distributed telemetry correlation. Good to go, right? Well, only if you configure the “operation_Id” to the value of the request id.
Listening and Right-Sizing
“When I was growing up, I always wanted to be someone. Now I realize I should have been more specific.” ~ Lily Tomlin
Now that we’ve discussed performance monitoring let’s tackle the scenario’s functional requirements. The client has supplied the team with an arbitrary performance SLA of 3 seconds to handle any request. Fortunately, our solution provides “autoscaling” for our app instances. We could use our instrumentation to ensure that we meet the 3-second requirement by setting an alert. Although, this solution is very reactive. From a production standpoint, we don’t know what throughput looks like historically.
The Baseline – Act on Fact
So, let’s go back to our Performance Efficiency Pillar. Suppose there’s an unexpected storm headed to one of your regional locations. The sales department expects an unplanned rise in traffic to the API. How is the business feeling about that 3-second service level agreement now? We could guess how much additional traffic we’d get from that region and set an upper limit to our autoscaling to accommodate for the speculated cushion. We could keep someone on call to manage the potential need manually.

However, we will request historical data for average and peak traffic because we’ve used the Performance Efficiency Pillar. A facet of cloud engineering while gathering requirements for Performance is ensuring you have both a historical baseline and target baseline for business spikes and expected growth in demand.
At this point, it is crucial to interview, listen, understand, and document a project’s key objectives and metrics. Identify how it will interact within the bounded context and domain, impacting both internal and external customers. Ask leading questions to identify expectations that may turn into gaps. Occasionally this data is tacit knowledge in someone’s recollection. However, most companies retain marketing analytics going back at least several years.
This baseline data may also provide cost benefits should there be event-based slowdowns based on seasonal lines of business, like the skiing industry or pool supplies or economic trends that would likely cause traffic anomalies for our app.
Okay, so now we’ve done our due diligence. We have made our inferences and received acceptance of our conclusions. However, we now need to test our application under average and peak loads, and we have a new requirement from the Product Owner. We’ve been using “Postman” to perform functional testing and automate integration testing for our API, and our client wants to get some reuse from the work that’s gone into these tests.
While it’d be ideal to use JMeter based on its widespread use and therefore reduce staffing issues for the client, it doesn’t provide the interface required with Postman. After some research, we found a product, (k6, 2021), and Microsoft endorses it. It’s a modern cloud tool that integrates with DevOps automated testing and has a minimal footprint. However, it’s been available for less than a year but has a strong reputation, rising use, and excellent documentation. A proof of concept (POC) using the application (with mock responses) and exercising all the throughput models we gathered during the baseline analysis, provided evidence the solution was sound.
Principals
We’ve considered all the Azure Well-Architected Framework principles and arrived at a proposed solution. We’ve evaluated the performance patterns and the trade-offs from a design perspective.
POC and Model Testing
“If an end-user perceives bad performance from your website, her next click will likely be on your-competition.com.” ~ Ian Molyneaux
The design and implementation of the project example uses k6 segmented into URL and Payload, Postman as a Data Source, JavaScript modules, and the inclusion of WireMock, and Faker providing mock test data in the Payload are curtesy of a performance solution. You can develop the modularity necessary for reuse in testing iterative phases when deploying RESTful APIs.
- Generate the URLs and payloads by integrating Postman with “k6”.
- Inject the mock input data using faker based on business rules into placeholders in the payload.
- We define test scenarios based on the global location and the product requested testing both the average and peak scenario. Since our test is isolated, we can ensure supplied test data for the locations before introducing the next phase of testing.
- Tests return average, min, max, mean, 90 and 95 throughput results for each scenario.
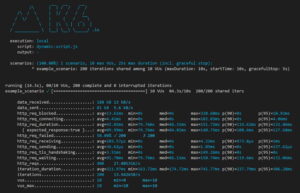
The results were significantly faster than expected, even when triggering retry events. As the global locations are added the throughput normalizes. Although the result above was executed on a demo system, the virtual users, iterations, and duration are consistent with the performance tests that resulted from the client’s baseline.
Checklist
…. Even Han and Chewie use a checklist. ~ Jon Stewart
Now we’ve reached the point in the Azure Well-Architected performance patterns against the applicability to the non-functional and functional requirements. Then we weighed and documented the trade-offs from a design perspective.
We’ve completed performance testing with a representative population accounting for expected latency issues. We’ve completed our Framework Checklist including design recommendations. Performance data captured by Azure Application Insights.
Conclusion
This scenario for Azure Well-Architected Framework serves as an example of the processes performed by the Perficient‘s Microsoft Azure Teams for our clients. Some of the patterns and practices discussed here have been in use for decades, some are more specific to Cloud design. They have design tradeoffs that must be evaluated against requirements.
Providing isolation during performance testing before a release will ensure that only the application and not its dependencies are validated for additional latency. The use of Application Insights provides response times (throughput) for your services and can provide correlation testing when properly configured. The Framework is a guideline and considers Architectural Trade-offs based on domain and functional requirements. The use of the Framework has proven successful in meeting business objectives while providing flexibility.
References
k6. (2021, November). k6 documentation. Retrieved from k6 documentation: https://k6.io/docs/
Microsoft. (2021, December). Performance efficiency checklist. Retrieved from Azure Product documentation: https://docs.microsoft.com/en-us/azure/architecture/framework/scalability/performance-efficiency
Microsoft. (2021, December). Performance Efficiency patterns. Retrieved from Azure Product documentation: https://docs.microsoft.com/en-us/azure/architecture/framework/scalability/performance-efficiency-patterns
Microsoft. (2021, December). Performance efficiency principals. Retrieved from Azure Product documentation: https://docs.microsoft.com/en-us/azure/architecture/framework/scalability/principles
Microsoft. (2022, May). Tradeoffs for performance efficiency. Retrieved from Azure Product documentation: https://docs.microsoft.com/en-us/azure/architecture/framework/scalability/tradeoffs
Microsoft Azure Documentation. (2022, May). Telemetry correlation in Application Insights. Retrieved from Azure Monitor Documentation: https://docs.microsoft.com/en-us/azure/azure-monitor/app/correlation
modularity necessary for reuse in testing iterative phases when deploying RESTful APIs.
Why Perficient?
We’ve helped clients across industries develop strategic solutions and accelerate innovative cloud projects. As a certified Azure Direct Cloud Solution Provider (CSP), we help you drive innovation by providing support to keep your Microsoft Azure operations running.
Whether your IT team lacks certain skills or simply needs support with serving a large business, we’re here to help. Our expertise and comprehensive global support will help you make the most of Azure’s rich features.
Contact our team to learn more.