
Today I write my first blog with the hope of posting more in the future. I call myself as data enthusiast who likes to analyze and understand data in order to write my solutions because, ultimately, it’s the data that is critical for any application. Without further ado, let’s jump into the today’s topic—cloning on the two Data Warehouse systems:
- Snowflake
- BigQuery
I’ve watched numerous movies, and I remember in Marvel Heroes when Loki clones himself many ways at same time! Such cloning may not be possible in the real world but it’s possible in the world of technology. For example, cloning the code to a local machine (git clone is a primary example).
Now what about databases (DB)? Why not clone them? Well, we used to do that, but that was really a copy of the DB that consumed space. You might be wondering why do we need to clone a DB without consuming space? Well, there are many answers. Before we delve into that further, lets pause for a moment on why we do cloning (aka Copy). The primary reason for cloning is to resolve issues in production; when we move our application live and we say “Oops, I never encountered this kind of data or envisioned this data,” “I wish I had such data in my Development/Test environment so that I could have covered this scenario,” or “We don’t have such volume of data in my development/test environment and I could not un-earth these issues!”
Cloning also helps with, to name few:
- Enhancing the application and underlying data structure by using a production like copy of the data
- Performance tuning, which is most critical as Dev/Test environments lack data sets.
We used to clone (aka copy production data to our Dev and Test environments and perform our tests) the monolithic databases like Oracle, DB2, and SQL Server on-Prem. We used to call this cloning but if you observe we are not actually cloning them, but rather copying them. Copying has multiple disadvantages including:
- Duplication of data
- Manual effort (Or Some additional tool to perform activity)
- Days to replicate (If volume is high)
- Data is out of sync with Production
- Additional Storage
I personally dealt with the copy of extra-large databases, which took anywhere between 2 to 4 days, excluding the time to do post copy set up (analyzing, etc.).
I used to wish we had a simple command to use that would clone the DB without occupying space and get my job done in few commands without depending my DBAs. Voila, this turned out to be true when I started doing my Snowflake Pro Core certification and studying and playing with Snowflake.
Snowflake
Let me step back and talk about Snowflake. Snowflake is Multi-Cloud Data-Lake/Warehouse tool that is fully built on cloud, for cloud, and its architecture is defined on a Shared-disk and Shared-nothing database architecture. It has 3 architecture layers:
- Cloud Services: The coordinator and collection of Services.
- Query Processing: Brain of the system, where query execution is performed using “virtual warehouses”.
- Database Storage: Which physically stores the data in Columnar mode.
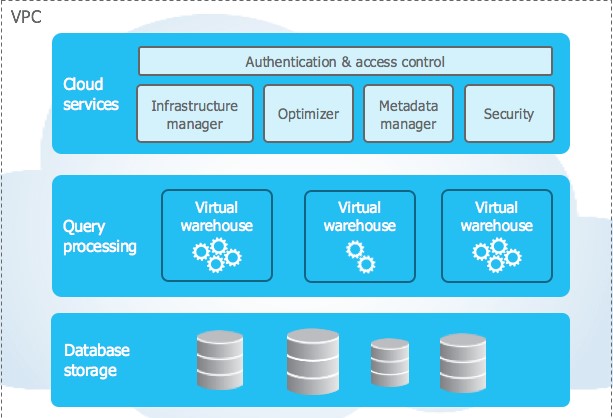
Source: Snowflake Documentation
This tool leverages Cloud providers (AWS/Google/Azure) strengths by using :
- Compute Engine (which is extensively used at the Query Processing layer and they call it a Virtual Warehouse)
- Cloud Storage (GCS in case of Google, S3 in case of AWS, and Blob Storage in case of Azure)
- VPC (networking and other security layer for its different versions)
Snowflake has a wonderful utility called Cloning (they call it Zero Copy clone) which can clone a Database/Table seamlessly in a simple command (example create or replace database clone_sales_db clone sales;). This command would clone an entire database (with certain restrictions; refer to Snowflake documentation for restrictions). The beauty of it comes from our college days study called Pointers/references! When you give a command to Clone a database, it simply does the following:
- Creates the New Database (An Object Name in the cloud services as normal)
- All objects underneath the database (note there are some restrictions in which certain objects do not get cloned) are created (again object name in the Service layer)
One would expect data is copied and held as “replica” but it’s not; what Snowflake smartly does is it creates a pointer/reference to the Source Database/Tables from the cloned Object, which gives a huge advantage of not only replicating data(logically) but savings in storage costs. When a user queries for a table from cloned object, the Cloud services will simply fetch the data from the actual source, making the data as up-to-date as possible. In addition, this does not consume time to create the clone—it takes as much time as you do to create a table.
See this an example:
- Say I created a table called “Transactions” and loaded about 200K records, the total size of this table is 8.6 MB:


- Observe the metadata of this table:

-
- ID: Unique ID for this table
- CLONE_GROUP_ID: From what ID of the Object this is cloned from (so its same as the ID)
- Now, I will create a clone of Transactions call it “Transactions_Clone”. Now, the Table will show the same volume of the records:

- We might be wondering if it has “copied” the entire “Transactions” Table and replicated it, but it has not. So how do we know it did not copy? See the Metadata of the table below:

- Observe the following
- ID: New table got its own Unique ID
- CLONE_GROUP_ID: It points to the ID of the “Transactions” Table. Isn’t it smart!
- So technically, when I query TRANSACTIONS_CLONE It simply refers to the Data location of “TRANSACTIONS”
- When we add data to the master, you will not see that in TRANSACTIONS_CLONE! (which was expected)
- Now, lets say, I delete the data from TRANSACTIONS_CLONE (60 of them), I will not see these 60, but still the other data will be referenced from its original Source “TRANSACTIONS“

- And my active bytes is still 0
- Now I loaded about 100K records to this and take a look at the Number of records!, It takes the new data from the recently added location and the rest from the Source.

If any user makes changes to the table or object, all Snowflake does is it will have the additional data (or deleted data) from the new pointers/references. This involves storage costs for only added data. When you delete the data, the original data is untouched, but its Cloud service layer holds the necessary information of what was removed and added making it a “True” Zero copy.
Similarly, if you make any structural changes, Snowflake handles the changes in its Cloud services layer and brings the necessary data accordingly.
This gives a real power of cloning with out consuming any space and you can replicate the table in matter of minutes if not seconds. Also giving speed to your development and testing with much better efficiency.
BigQuery
BigQuery is one of the most popular databases, or we should call Cloud Data Warehouse, that offers rich features for storing data and extreme performance and scalability of the data. This is a fully managed database so you do not need to worry about Storage or which compute engines to use. Unlike in Snowflake, one has to pick up a Virtual Warehouse (aka compute engine) to run your query, and if the query is not faring better, then you can pick up Higher configured warehouse to let the query run better.
In BigQuery you don’t need to worry of these and simply focus on writing the query and executing it. You will only be charged for the data that you retrieve.
BigQuery is similar to Snowflake, but until now, it did not have the ability to Clone the DB. During Google Next ’21, it was announced that soon you can:
- Take a Snapshot
- Clone the DB
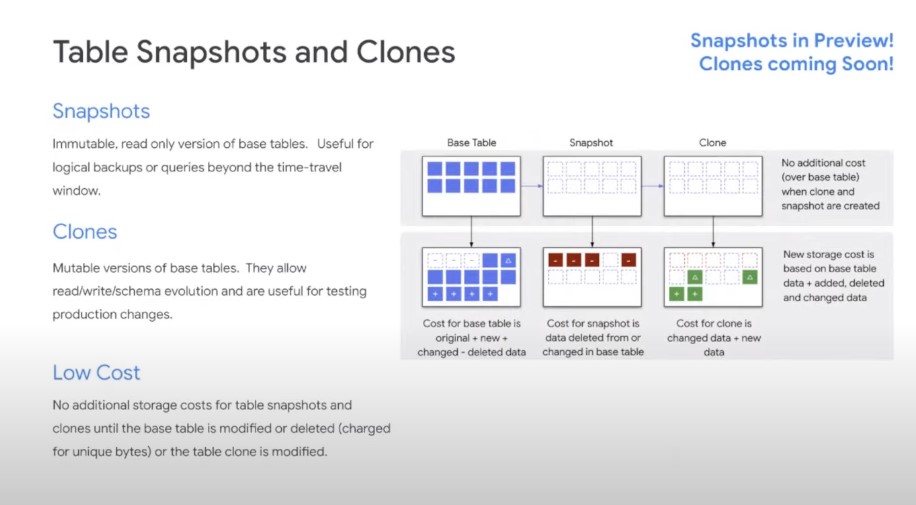
Source: Google Next ’21 Session
As per the slide above, Snapshots are immutable but a helpful feature that you can use to go back in time with out incurring any charges. This helps with savings because copying the table incurs in storage costs.
Cloning has been introduced (though it’s not yet available) but the concepts run through in similar fashion of the Snowflake (we still need to wait for official announcement until then we may need to assume) in which you will only incur charges on the new or modified data but not on others. This saves a huge cost when your table runs into TB or PB.
This is a feature that every developer/tester is waiting to see on BigQuery and once cloning is in place it will give a tremendous boost to the teams in analyzing production issues without going to the Prod. Specifically, you can simply clone and run your queries on Development area without any down time to the production boxes. Time is of the essence, and everyone wants to have things done faster and smarter and wants to minimize the manual effort.
There is more to come on these features once they are officially released. We will see how it fares against the Cloning of Snowflake Vs Amazon RDS Aurora cloning.
In future blogs, I will do a deep dive into the technicalities of the tool, features, and explore more solutions. Until then, signing off!