
Different organizations will have different needs for cluster memory management. For the same, there is no set of recommendations for resource allocation. Instead, it can be calculated from the available cluster resources. In this blog post, I will discuss best practices for YARN resource management with the optimum distribution of Memory, Executors, and Cores for a Spark Application within the available resources.
Based on the available resources, YARN negotiates resource requests from applications running in the cluster. This wouldn’t cause any issue unless you are dealing with a small group. Cluster with a limited resource needs to give importance to execute any spark jobs with ideal resource allocation to manage the traffic. A wrong approach to this critical aspect will cause spark job to consume entire cluster resources and make other applications starve.
Here are common errors we usually encounter,
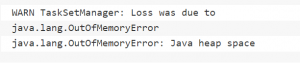
![]()
![]()
These can be caused by various reasons,
- Incorrect usage of Spark
- High concurrency
- Inefficient queries
- Incorrect configuration
To understand this, we’ll take a step back and look in simple terms how Spark works,

Spark Applications include two JVM Processes, and often OOM (Out of Memory) occurs either at Driver Level or Executor Level. Common OOM are
- Java Heap Space OOM
- Exceeding Executor Memory
- Exceeding Physical Memory
- Exceeding Virtual memory
Spark applications are compelling when configured in the right way. However, it becomes challenging to manage when they don’t go according to the plan. We personally face different issues where an application that was running well starts to misbehave due to multiple reasons like resource starvation, data change, query change, and many more. So, understanding underlying components will help us make an informed decision when things go wrong.
Here is the list of components important for every job,
- spark.executor.cores
- spark.executor.instances
- spark.executor.memory
- spark.driver.memory
- spark.driver.cores
And here is the list of components to be considered depending upon the job,
- spark.yarn.executor.memoryOverhead
- spark.executor.extraJavaOptions
- spark.driver.extraJavaOptions
- spark.memory.fraction
- spark.memory.storageFraction
- spark.memory.offHeap.enabled
- spark.memory.offHeap.size
- spark.sql.autoBroadcastJoinThreshold
Demonstration to calculate Spark Configurations and its recommended approach to manage memory allocation.
Consider,
10 Node Cluster ( 1 Master Node, 9 Worker Nodes)
Each 16VCores and 64GB RAM

spark.executor.cores
Tiny Approach – Allocating one executor per core. This will not leave enough memory overhead for YARN and accumulates cached variables (broadcast and accumulator), causing no benefit running multiple tasks in the same JVM.
Fat Approach – Allocating one executor per Node. This adds up having 10 executors per core, causing excessive Garbage results.
Balanced approach – 5 virtual cores for each executor is ideal to achieve optimal results in any sized cluster.(Recommended)
spark.excutor.cores = 5
spark.executor.instances
No. of executors/instance = (total number of virtual cores per instance – 1)/spark.executors.cores
[1 reserve it for the Hadoop daemons]
= (16-1)/5
=15/5 = 3
spark.executor.instances = (number of executors per instance * number of core instances) – 1
[1 for driver]
= (3 * 9) – 1
= 27-1 = 26
spark.executor.memory
Total executor memory = total RAM per instance / number of executors per instance
= 63/3 = 21
Leave 1 GB for the Hadoop daemons.
This total executor memory includes both executor memory and overheap in the ratio of 90% and 10%.
So,
spark.executor.memory = 21 * 0.90 = 19GB
spark.yarn.executor.memoryOverhead = 21 * 0.10 = 2GB
spark.driver.memory
spark.driver.memory = spark.executors.memory
spark.driver.cores
spark.driver.cores= spark.executors.cores