
While there are many reasons to push data integration projects forward, healthcare organizations are often held back from using their data by incompatible formats, limitations of databases and systems, and the inability to combine data from multiple sources. This is why cloud-based data lakes have replaced the enterprise data warehouse (EDW) as the core of a modern healthcare data architecture.
Unlike a data warehouse, a data lake is a collection of all data types: structured, semi-structured, and unstructured. Data is stored in its raw format without the need for any structure or schema. In fact, data structure doesn’t need to be defined when being captured, only when being read. Because data lakes are highly scalable, you can support larger volumes of data at a cheaper price.
With a data lake, data can also be stored from relational sources (like databases) and from non-relational sources (IoT devices/machines, social media, etc.) without ETL (extract, transform, load), allowing data to be available for analysis much faster.
The enterprise data warehouse (EDW) as we know it is neither dead nor will it be any time soon. However, it’s no longer the centerpiece of an enterprise’s data architecture strategy. The EDW remains a mission-critical component in a company’s overall information technology architecture, but it should now be viewed as a “downstream application” — a destination, but not the center of your data universe.
Next Steps in Building a Modern Enterprise Data Architecture
The journey to building a modern enterprise data architecture can seem long and challenging, but with the right framework and principles, you can successfully make this transformation sooner than you think.
Data lakes are built intentionally to be flexible, expandable and connectivity to a variety of data sources and systems. By bringing together systems, we can load/extract, curate/transform and publish/load disparate data across the healthcare organization. When designed well, a data lake is an effective data-driven design pattern for capturing a wide range of data types, both old and new, at large scale. By definition, a data lake is optimized for the quick ingestion of raw, detailed source data plus on-the-fly processing of such data for exploration, analytics and operations.
Organizations are adopting the data lake design pattern (whether on Hadoop or a relational database) because lakes provision the kind of raw data that users need for data exploration and discovery-oriented forms of advanced analytics. A data lake can also be a consolidation point for both new and traditional data, thereby enabling analytics correlations across all data.
The Data Lake’s Strength leads to a Weakness.
A data lake will grow by leaps and bound by its very nature, if left attended. It can ingest data at a variety of speeds, from batch to real-time. Its unstructured data comes in all shapes and forms, leading to an accumulation of ‘noise’ or data without meaning or purpose. Garner’s Hype Cycle for 2017 reveals that the excitement of the data lake is revealing that there is a growing disillusionment with the unrealistic expectations.
Originally, data lakes were predicted to solve the problems with outcomes. Instead of solving them, data lakes became data swamps.
The Four Zones of a Data Lake
To get around the problem of the ‘Data Swamp’, we need to understand and create four zones within the data lake. Through the process of data governance, we can control the quality and quantity of the information we use and report on. Distinct data zones allow us to define, analyze, govern, archive and standardize our data to give it meaning and organization for a multitude of platforms and analytical systems.

To define these zones, the ebook Big Data Science and Advanced Analytics identifies a need to separate the physical data structures and systems from the logical models. By using servers and clusters, we can virtualize the data in a variety of configurations, feeding different downstream applications through the control and governance. Healthcare analytics depend on a reliable and consistent feed of information from the legacy and transactional systems, such as member eligibility, benefits and pricing, utilization provider networks and claims adjudication.
By creating unique zones, the data lake is able to consume the variety of incoming information, transform it and merge it with other cross walks of lookups, then feed it to analytical systems.
Data lakes are divided into four zones (Figure 1). Different healthcare organization may call them by different names but their functions are essentially the same.
- Raw Data Zone
- Trusted Data Zone
- Refined Data Zone
- Sandbox Data Zone
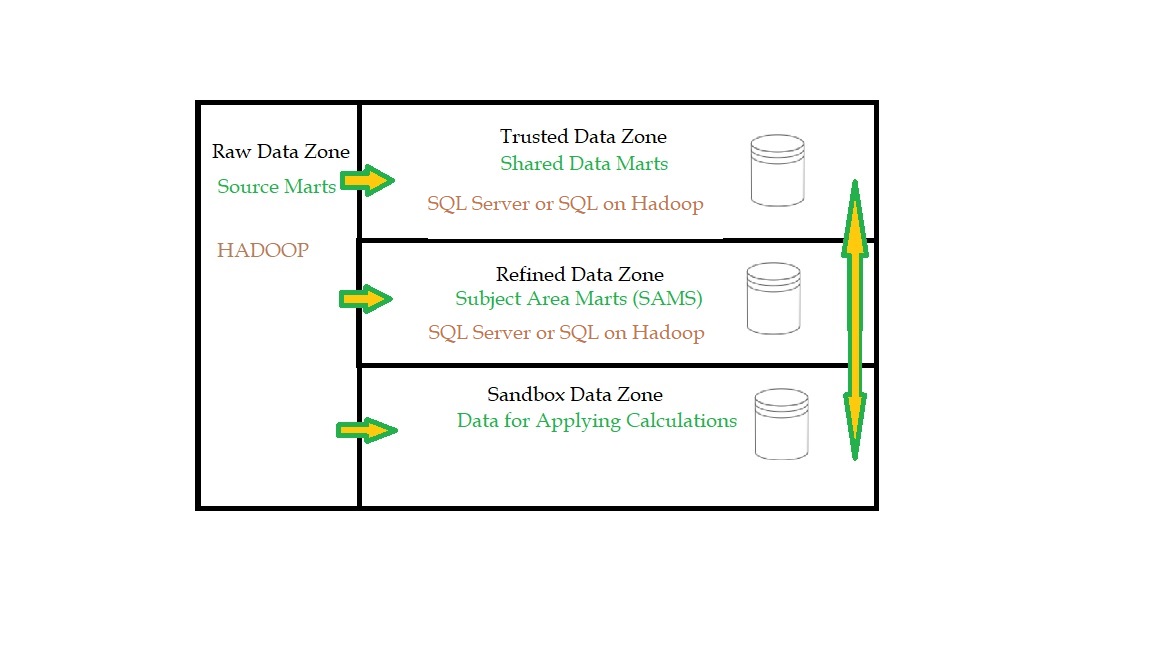
Raw Data Zone
In the Raw Data Zone, data is moved in its native format, without transformation or conversion. It is brought over ‘as is’. This ensure that the information is brought over without change. It allows the raw data to be seen as it was in its originally format from their source systems.
It is too complex for less technical users. Typically users are ETL developers, data scientists, who are able to derive new meaning and structure from their original values by sifting through the vastness of data. This new information is then pushed into other zones.
Trusted Data Zone
In the Trusted Data Zone, Source data is transformed and curated into meaningful information. It is prepared for common use, merged with other data, crosswalked and translated. Terminology is standardized by data governance rules.
Data dictionaries are created. This data becomes the building blocks that extend across the enterprise. Trusted Data such as claims, capitation, laboratory results, utilization, admissions, and member eligibility are the foundation to accurate underwriting and risk analysis.
Refined Data Zone
The Refined Data Zone is where Trusted Data is curated and published to be used in external Enterprise Data Warehouse and datamarts. Meaning is derived from raw data. It is integrated into a common format, refined and grouped into Subject Area Marts (SAM). SAM are used to analyze and complex inquiry.
SAM provide Executive leadership with analytical support for corporate decisions and complex. SAM are used for standardized ‘member per month’ and other operational support reporting.
SAM become the source of truth and the merging data from different original sources. They take subsets of data from a larger pool and add value and meaning that is useful to a finance, budgeting and forecasting, member and provider utilization, clinical, claims adjudication/payment and other administrative areas. Refined data is used by a broad group of people.
Refined data is promoted to the Trusted Zone after it has been confirmed and verified by data governance or subject matter experts.
Sandbox Data Zone
The Sandbox is also known as the ‘exploration’ zone. It is used for adhoc analysis and reporting. Users move data from the raw zone, trusted zone and refined zone here for private use. Once the data is verified, it can then be promoted for use in the refined data zone.
The Future of the Data Lakes
As the volume of healthcare data continues to grow, IT and enterprise architecture, and business governance must continue to review their platforms and their integrations. Hardware and software needs of the business guide the decisions being made to guide the healthcare organization’s vision and leadership into the future. We need to look at the use of the data, regulatory compliance, archiving and removal processes.
Data governance plays a critical role in determining what data needs are required in the data lake, and in each data zone. They must look at their business capabilities needed to perform their critical functions and protect their assets. Afterwards, analytics and its related business services can be built to support these capabilities and function.
For more information on the role of Data Lakes in healthcare, please refer to the Perficient White Paper The Role of Data Lakes in Healthcare
By Steven Vacca, Technical Analyst, Perficient