
Introduction
On a daily basis, data growth is expanding at a pace greater than the expansion of the universe itself. It makes our lives better, but it also has the capability of reflecting the vulnerabilities of a person or an organization.
Data is like Infinity Gauntlet. If you know how to use it, like Thanos who destroyed half of the universe with the snap of a finger, you can take down a person, an organization or a government with a single click!! Or a single Enter!!
In the 21st century, with the help of the IT sector, organizations use real data from different customers from different domains data banks to forecast, learn, archive, evolve and compete. This opens the door for the sensitive data to be hacked, become public or to be used as leverage during application development, testing or training. Sensitive data is like an atom bomb. It might look small, but the aftermath it can cause once it is released will be devastating. So, shielding and guarding the sensitive data is always a top priority on every organization’s agenda.
Therefore, as a part of this blog, we are going to walk through the steps for shielding sensitive data using a technique called Data Masking. We will also discuss the different types of sensitive data that can be masked with this profound technique. This technique changes the data, which makes it more realistic, sensible and ready to use for application development and testing.
What is Data Masking in Informatica?
As the name suggests, the motive behind data masking is to mask sensitive production data and convert it into realistic test data for a non-production environment. With the help of data transformation in Informatica, data relationships in the masked data along with the referential integrity in the table level is maintained.
Types of Data Masking in Informatica
Now let’s learn more about the different types of data masking functionalities available in Informatica. Before you can find more on data masking transformation, the mentioned pre-requisites have to be fulfilled.
Pre-requisites
In order to demonstrate more on data masking, the primary pre-requisite is the license for data masking transformation in Informatica.
Random Masking
Random masking generates random nondeterministic masked data. The Data Masking transformation returns different values when the same source value occurs in different rows. You can define masking rules that affect the format of data that the Data Masking transformation returns. In random masking, numeric, string, and date values can be masked.

Random masking
Range: Under random masking, the option to change the range of the random data can be configured. The maximum width can be set based on the datatype length.
Mask Format: Under random masking, the output format of the masked data can be configured. Based on the length, the format can be set.
A – Alphabetic characters from a to z or A to Z
D – Digits 0 to 9
N – Alphanumeric characters, a to z, A to Z and 0 to 9
X – Any character, alphanumeric or symbols
+ – No Masking
R – Remaining characters can be any character, must be the last character in the mask format.
Example: DDD+AAAAAA
Source String Characters: An option to mask specific characters or exception characters from the incoming stream. Under this function, we have an option to mask all but certain characters. The other option is to mask only certain characters.
Random masking – source string characters option
Result String Replacement Characters: An option to use specific characters or exception characters in the resulting output stream. Under this function, we have an option to use all but certain characters. The other option is to use only certain characters.
Random masking – result string replacement characters option
Email Address masking
Under data masking transformation, we have the option of masking email columns with the string datatype. In Email address masking, we have two types for email masking.
Standard Masking: Under standard masking, random combinations of characters are used for masking the incoming email data.
Example: KtrIupQAPyk@vdSKh.BIC
Advanced Masking: Under the advanced masking type, the email masking properties can be configured to be more realistic.

Email Address masking
First Name and Last Name columns can be selected to be used as part of the masked output email. This can be done through two methods.
- From Mapping
- From Dictionary
From Mapping: The columns to be used as part of the masked email are fetched from the existing mapping. The below image depicts the drop-down list of the columns from the mapping.
Email masking – From Mapping
From Dictionary: The columns to be used as part of the masked email are fetched externally, either from a flat file or from a relational table.
Relational Table:
Email masking – From Mapping – Relational
Flat File:
Email masking – From Mapping – Flat file
Under the Dictionary method, input columns, as well as dictionary columns, can be used together for the masked email creation. This is possible using the expression method.

Email masking – From Dictionary
By using the configure expression option, any expression can be applied to the selected columns. The columns can be from the source or from the dictionary file/table.
In both Mapping methods as well as the Dictionary method, the length of the Name columns along with the delimiter can be selected. Based on the selected values, the masked output email is created.
Email masking – Name columns
Once the columns to form the email-id has been selected, the domain to be used in the email-id have to be selected. There are two methods to achieve the same outcome.
- Constant: A default domain name is set for all the incoming email data.
- Random: The domain name is selected externally from a dictionary. It can be either from a flat file or from a relational table.
Random – Domain Name selection:
Email masking – Domain Name selection
IP Address masking

The data masking transformation masks the IP address into a masked IP address by splitting into four numerical segments delimited by a period. The randomly generated numbers for the output IP address are always within their respective class range.
For Example, if the incoming IP address is from the class-A format, then the masked IP address will also belong to the class-A format.
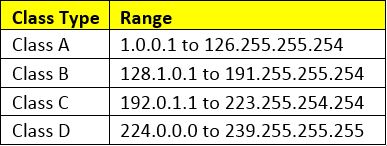
IP masking – Class types
IP masking – Rules
Seed: Seed is the most important component that helps to create the masked output. For every combination of input value and seed value, a unique masked output value is generated. When the same input value occurs in other tables, based on the seed value, Informatica produces the same masked output value. As a result, it maintains the referential integrity in the table level.
The seed values are configured using the below-mentioned methods.
- Default value.
- Manually set the value between 1 and 1000.
- Seed value fetched as a mapping parameter externally.
Repeatable Output: When the repeatable output option is selected, Informatica returns the same masked value for the combination of every similar input value with a seed value.
SSN Masking
A Social Security Number (SSN) consists of nine digits, commonly written as three fields separated by hyphens: AAA-GG-SSSS. The first three-digit field is the “area number”. The central, two-digit field is the “group number”. The final, four-digit field is the “serial number”. In Informatica, the data masking transformation accepts input with nine digits, which can be delimited by any number of characters.
Example: +=54-*9944$#789-,*()”. <has 9 digits alone>
SSN masking – Rules
During SSN Data masking, the segments group number and serial number are masked by random values, whereas the area number remains the same. If the value of the area number in the incoming SSN number is invalid, the column will not be masked.
Credit Card Masking
Informatica uses a built-in mask format for masking the valid credit card number by generating logically correct credit card numbers. The length of the source credit card number must be 13 to 19 digits. The input credit card number must have a valid checksum based on credit card industry rules.
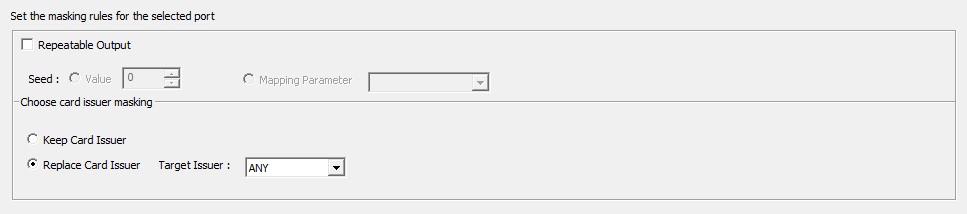
Credit card masking – Card Issuer
In case of invalid credit card number values, the data masking transformation uses a default value and writes an error to the session log.
In credit card masking, the first six digits help us to identify the card issuer. These digits are configured to be either removed or kept. The two options are explained below.
- Keep card Issuer: The first 6 digits are kept as it is, during masking.
- Replace Card Issuer: The first 6 digits are replaced by other card issuers like Visa, Mastermind and etc
Credit card masking – Card Issuer Types
Seed: Seed is the most important component that helps to create the masked output. For every combination of input value and seed value, a unique masked output value is generated. When the same input value occurs in other tables, based on the seed value, Informatica produces the same masked output value. As a result, it maintains the referential integrity in the table level.
The seed values are configured by the below-mentioned methods.
- Default value.
- Manually set the value between 1 and 1000.
- Seed value fetched as a mapping parameter externally.
Repeatable Output: When the repeatable output option is selected, Informatica returns the same masked value for the combination of every similar input value with a seed value.
URL Masking
In order to mask URL’s, Informatica searches for ‘://’ in the incoming data and parses the random substring to it. The incoming URL column can contain numbers as well as letters.
URL masking – Rules
In URL masking, the protocol of the URL will remain unmasked.
Example:
Input: http://www.google.com
Output: http://MgL.aHjCa.VsD/
Seed: Seed is the most important component that helps to create the masked output. For every combination of input value and seed value, a unique masked output value is generated. When the same input value occurs in other tables, based on the seed value, Informatica produces the same masked output value. As a result, it maintains the referential integrity in the table level.
The seed values are configured by the below-mentioned methods.
- Default value.
- Manually set the value between 1 and 1000.
- Seed value fetched as a mapping parameter externally.
Repeatable Output: When the option repeatable output is selected, Informatica returns the same masked value for the combination of every similar input value with a seed value.
Phone masking
Data masking transformation masks the phone column as per the incoming phone format. In the phone format, numbers, spaces, hyphens, and parenthesis are allowed. The rest of the characters will remain unmasked if present in the source data.
Example: (408)382 0658 masked as (607)256 3106.
Seed: Seed is the most important component that helps to create the masked output. For every combination of input value and seed value, a unique masked output value is generated. When the same input value occurs in other tables, based on the seed value, Informatica produces the same masked output value. As a result, it maintains the referential integrity in the table level.
The seed values are configured by the below-mentioned methods.
- Default value.
- Manually set the value between 1 and 1000.
- Seed value fetched as a mapping parameter externally.
Repeatable Output: When the option repeatable output is selected, Informatica returns the same masked value for the combination of every similar input value with seed value.
Phone masking – Rules
Key masking
Key masking comes into the picture when the requirement includes a deterministic and repeatable output for a key value. In other words, wherever the similar input key values occur, the resulting masked output will also be similar. String and numeric data types are masked under key masking.
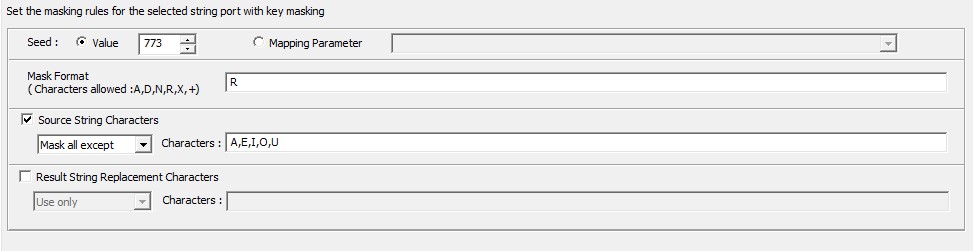
Key masking – Rules
Seed: Seed is the most important component that helps to create the masked output. For every combination of input key value and seed value, a unique masked output value is generated. When the same input key occurs in other tables, based on the seed value, Informatica produces the same masked output value. As a result, it maintains the referential integrity in the table level.
The seed values should be configured by the mentioned methods.
- Default value.
- Manually set the value between 1 and 1000.
- Seed value fetched as a mapping parameter externally.
Mask Format: Under key masking, the output format of the masked data can be configured. Based on the length, the format can be set.
A – Alphabetic characters from a to z or A to Z
D – Digits 0 to 9
N – Alphanumeric characters, a to z, A to Z and 0 to 9
X – Any character, alphanumeric or symbols
+ – No Masking
R – Remaining characters can be any character, must be the last character in the mask format.
Example: DDD+AAAAAA
Source String Characters: An option to mask specific characters or exception characters from the incoming stream. Under this function, we have an option to mask all except certain characters. The other option is to mask only certain characters.
Key masking – Source String Characters
Result String Replacement Characters: An option to use specific characters or exception characters in the resulting output stream. Under this function, we have an option to use all except certain characters. The other option is to use only certain characters.
Key masking – Result String Replacement Characters
Expression masking
As the name suggests, expression masking helps in applying different expressions to the incoming data stream, before displaying as masked output.
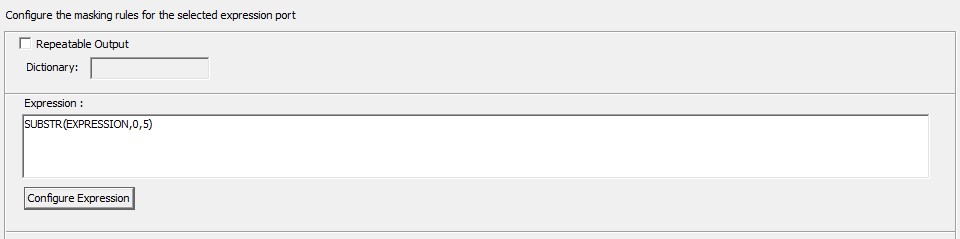
Expression masking – Rules
Repeatable Output: Repeatable expression masking is configured when the source column appears in more than one table and the masked output value for each table has to be similar. Every time the repeatable expression is selected, the Data masking transformation saves the results of the expression in a storage table.
Dictionary: While configuring repeatable expression masking, dictionary name is required. The Dictionary name acts as a key for fetching the same masked output values for the same input values. The same dictionary name has to be defined for every data masking transformation, for utilizing the repeatable expression masking property.
Substitution masking
Substitution masking replaces the value of the input columns with similar but unrelated data. One of the major uses of substitution masking relies on its abilities to mask production data with realistic test data. The substituted values are fetched from a dictionary. Dictionary files can contain string data, date/time values, integers, and floating-point numbers.
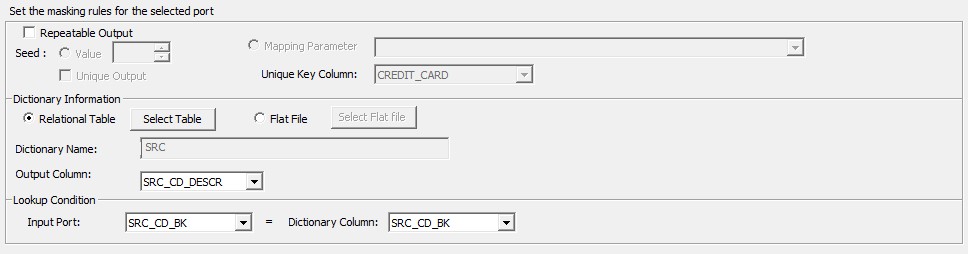
Substitution masking
Dictionary: The form for the dictionary can be a flat file or a relational table. The concept of a dictionary is similar to a lookup transformation in Informatica. A lookup condition is set based on the input column and dictionary column selection. The dictionary column, which will be used for substitution, is selected under the Output Column option. The Output Column option is highlighted below.
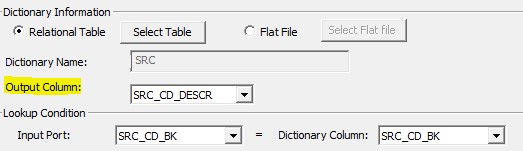
Substitution masking – Dictionary
Dependent masking
Dependent masking substitutes values for multiple columns from the same dictionary. Dependent masking is directly associated with substitution masking. On the condition that substitution masking is used in the current mapping, Dependent masking can be used. For instance, if the ZIP code is used for substitution masking, then columns like city, state that are dependent on ZIP code can be masked under the dependent masking. This masking ensures that the substituted city and state values are valid for the substituted ZIP code value.
Dependent Masking
The dictionary file will contain both the substituted columns along with dependent columns. In the data masking transformation, Dependent Column will be ZIP code and Output column will be City or State columns.
This concludes the detailed explantion of data masking transformation in Informatica.
Thank you
Thank you for sharing your blog, seems to be useful information can’t wait to dig deep!