
Log file analysis is an important tool in any technical SEO audit and really, any regular analysis where you need to better understand how your site is being accessed and crawled by search engines.
What Are Log Files and Why Use Them for SEO?
Most web servers maintain a log of all access to a website by humans and search engines. Data that is usually logged includes the date and time of access, the filename(s) accessed, the user’s IP address, the referring web page, the user’s browser software and version, and cookie data.
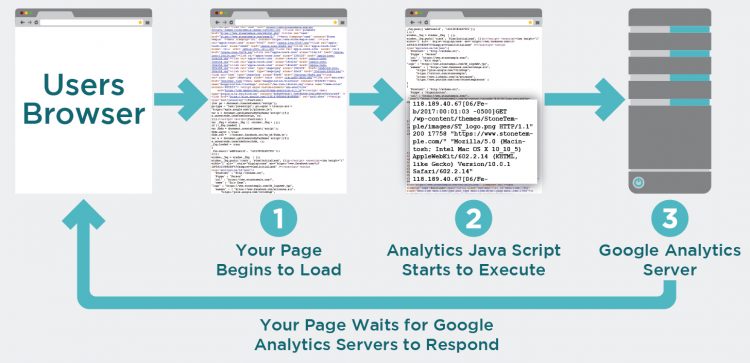
Log file data provides an essential function that other JavaScript-based web analytics tools cannot: they record search engine crawler activity on your website.
[Tweet “Log file data provides an essential function that other JavaScript-based web analytics tools cannot.”]
Although search engine crawling behavior changes daily, log files allow you to see longer-term trends to identify crawl patterns (for example, if it’s trending up or down). In addition, you can check to see if specific pages of your site, or sections, are being crawled.
This is rich data you can use in your technical SEO analysis. Because log files contain the click-by-click history of all requests to your web server, you want to make sure you have access to this and know how to use it.
Other ways log files provide benefits over web analytics include:
- It’s not possible to see the history of your analytics data prior to having analytics set up or modified. In contrast with log files, you can go back as far in time as you like. Quick caution: for many web hosts the prior statement is true, but you should check with your web host to make sure they are keeping your log files available to you, otherwise they may delete them after a period of time.
- Web analytics require you to install JavaScript on all the pages of your site. This has the following limitations:
- If this is done incorrectly, or some pages are missed, your data will be wrong and these problems can be hard to find.
- When the JavaScript executes, it generally makes a call to a third-party server (the analytics provider), and that slows down page execution.
- Custom tagging is needed in analytics for more complex analysis, such as seeing how many people clicked on certain links.
I’m not saying you shouldn’t use JavaScript-based analytics, but just be aware that log files offer some capabilities that analytics don’t. For that reason, the first two points above are the most important.
If you’re using a third-party hosting provider, you may be able to get access to a log file analytics package from the vendor. You can then use Excel to analyze those files by converting them into an Excel format.
Log File Analysis: What You Can Find
There are seemingly endless ways you can slice and dice your log file data. Let’s look at just a handful of scenarios you can get insights into.
Crawlers Accessing Your Site

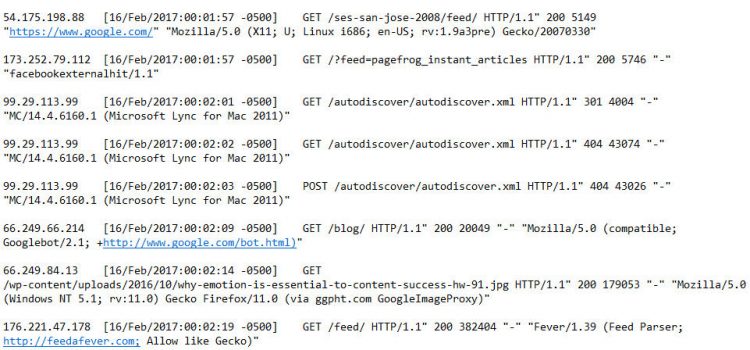
Do you want to ensure your site is crawled by specific search engines? Log files can tell you the types of web crawlers accessing your site and how many requests from them you get per day. This includes tracking people who may be scraping your web site. You can also view the last crawl date.
Crawl Budget Waste
Search engines like Google have a specific number of pages they will crawl on any given website on any given day (aka “crawl budget”). Here is an important excerpt from my May 2016 virtual keynote with Gary Illyes on the concept of crawl budget:
Eric: So historically people have talked about Google having a crawl budget. Is that a correct notion? Like, Google comes and they’re going to take 327 pages from your site today?
Gary: It’s not by page, like how many pages do we want to crawl? We have a notion internally which we call host-load, and that’s basically how much load do we think a site can handle from us. But it’s not based on a number of pages. It’s more like, what’s the limit? Or what’s the threshold after which the server becomes slower
I think what you are talking about is actually scheduling. Basically how many pages do we ask from indexing side to be crawled by Googlebot? That’s driven mainly by the importance of the pages on a site, not by number of URLs or how many URLs we want to crawl. It doesn’t have anything to do with host-load. It’s more like, if…this is just an example…but for example, if this URL is in a sitemap, then we will probably want to crawl it sooner or more often because you deem that page more important by putting it sitemap.
We can also learn that this might not be true when sitemaps are automatically generated. Like, for every single URL, there is a URL entering the sitemap. And then we’ll use other signals. For example, high PageRank URLs…and now I did want to say PageRank…probably should be crawled more often. And we have a bunch of other signals that we use that I will not say, but basically the more important the URL is, the more often it will be re-crawled.
And once we re-crawl a bucket of URLs, high-importance URLS, then we will just stop. We will probably not go further. Every single…I will say day, but it’s probably not a day…we create a bucket of URLs that we want to crawl from a site, and we fill that bucket with URLS sorted by the signals that we use for scheduling, which is site minutes, PageRank, whatever. And then from the top, we start crawling and crawling. And if we can finish the bucket, fine. If we see that the servers slowed down, then we will stop.
To translate that a bit, there are a specific set of priorities Google will have for crawling a site. It may not be a specific number of pages, but that may still lead to Google spending time crawling pages that you have marked with NoIndex tags, rel=canonical tags, or other pages that are more or less a waste of its time. Log file analysis can help you discover just how much of this is going on.
Crawl Priority
Search engines may not be crawling the most important pages of your website. Through log file analysis, you can see which sections (folders) or pages (URLs) are crawled and the frequency of those crawls. You want to ensure major search engines like Google and Bing are accessing the files you want and including them in their index. You can help set crawl priority via your XML Sitemap. https://support.google.com/webmasters/answer/183668?hl=en
The basic way to do that is to import your log file into Excel and filter on the presence of the URL or folder names. More complicated Excel analysis of the search engine crawl priorities requires a more in-depth knowledge of Excel that I’ll go through in an upcoming article.
Duplicate URLs Crawled
Crawlers can waste crawl budget on irrelevant URLs. For example, when URL parameters are tagged onto a URL, created for the purposes of tracking performance, like a marketing campaign, https://ga-dev-tools.appspot.com/campaign-url-builder/ like this:
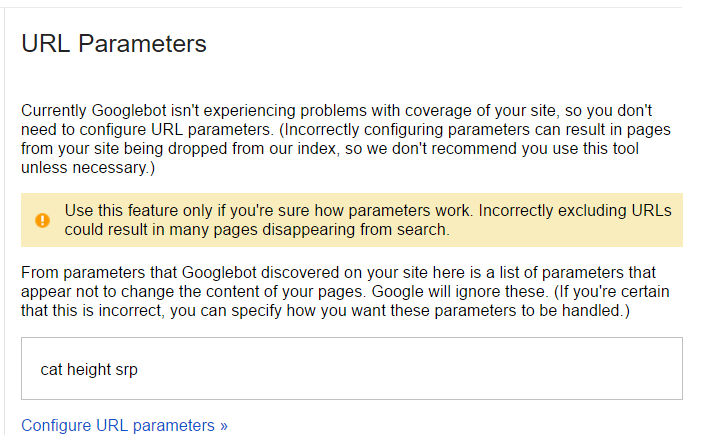
Once you’ve identified these, there are ways to address it by going into the site’s Google Search Console account, selecting “Crawl”, and then “URL Parameters.” Here’s a screenshot of what you might find (this is just an example, and the message you receive might be very different):
Response Code Errors
If you’re working with an SEO platform (like Moz) or a crawler tool (like Screaming Frog SEO Spider), you usually have access to this type of information. However, if you don’t get this info anywhere else, log files can tell you about 404 errors or any 4XX or 5XX errors that could be impacting your site.
When you’re analyzing the data, group the requests by file type (HTML, PDF, CSS, JS, JPG, PNG, etc.). Within each group, cluster by server response code (200, 404, 500 and so on).
Files that are in the site’s crawl path should return the response code 200 or redirect to files that eventually resolve as 200. Your goal: Not to have errors in the site’s crawl path.
Temporary Redirects
Again, many other tools can tell you about things like temporary redirects (302s). But so can log files. It’s worth mentioning that Google said in 2016 that 302 redirects won’t result in PageRank dilution, http://searchengineland.com/google-no-pagerank-dilution-using-301-302-30x-redirects-anymore-254608 but you can still use this data to prioritize the updates that make sense for the site and business, but they can still lead to the wrong page being indexed by Google (they may keep the page that 302 redirects in the index instead of the page that the redirect points to).
Other ways you can use log files to dig into juicy data:
- Look for images that are hot-linked (requested from HTML files on other sites). This will show you when people are using your images in their content, and you can then go verify that they are at least providing some level of attribution.
- Look for unnatural requests for files that do not exist and there’s no reason to be looking for them. This could indicate hacking attempts.
- Look at requests from absurdly outdated user agents. For example, IE5 or NN4, as those could very well be bots that you may want to consider blocking. This is something that you can do in your .htaccess file (Apache servers) or ISAPI rewrite (IIS servers). If you want to take this further, you can also write scripts that can dynamically detect bad bot behavior and block them from accessing your site at all.
- Look for requests to files that may not be included in your standard traffic reporting, for example for PDF or Word documents.
Log files can be an overlooked treasure trove of SEO data that is crucial to uncover. Using log files in addition to your web-based analytics helps inform the diagnosis of a website’s health, and can help you solve tough problems the site may be facing.
Deliciously nerdy stuff! I appreciate the time you guys spend on your articles. Also your presentations at SMX.
Thanks, Charlie!
Question for you: After analyzing some crawl data in Search Console in the sitemap section, I noticed that Google consistently isn’t indexing about 3/4 of the client sites I work on. I began to wonder if maybe Google (and others) have a hard time crawling certain parts of the sites consistently.
To research this, I started using a log file analyzer (Screaming Frog’s version) for some of those clients. After loading the files, I noticed that none of the crawl activity logged by the servers is considered verified. I input one month’s worth of log files, but when I switch the program to show only verified bots, all data disappears. Is it possible for a site not to have any search engines crawling it for a whole month? Given my experience, that seems unlikely, particularly since we’ve been submitting crawl requests. I know that doesn’t guarantee a crawl, but it seems odd that it’s never happening for any search engines across the board.
Context that might be helpful:
* I did check technical settings, and the sites are crawlable.
* The sites do appear in search but seem to be losing organic search traffic.
Thanks for any help you can provide!
Hi Joanna – that does seem strange. This leads me to a few questions for you:
1. Are the sites blocked in robots.txt? (is that what you meant by checking the technical settings?)
2. Do they have any links?
3. How are the sites implemented? I.e. what content management system / dev platform are in use?
Given that you say they show up in search, they must be seeing some crawling activity, or at least have done so at some point. So the other possibility is that you may not have been looking at the log file analyzer results correctly. The other thing you can do is to load the log files in a text editor, and then simply do a search for “Googlebot” in there and see if you see a string similar to this one: “(compatible; Googlebot/2.1; +http://www.google.com/bot.html).