In TM1, missing data usually means that there is a defect in the logic of your ETL script or you need to check your SQL. In SPSS Modeler, missing values arise for a variety of reasons and they must be considered carefully.
You might expect that missing values imply errors or should those records be thrown away, but that is not always the case. In fact, (in the SPSS world) analysts have found that missing values can be useful information.
What to do
Assuming you TM1 developers have your ETL and SQL under control, we can focus on SPSS. When your data contains missing data the first step is to assess the type and amount of missing values (for each field) in your file, the second step is to determine how to handle it.
Modeler recognizes types of “missing values”. They are:
- System undefined values (represented as $null$).
- Predefined (or user-defined) values (that represent missing information).
Blanks
You’ll know (as a TM1 developer) that you need to understand that there is a difference in how you handle the programming of numeric missing data as opposed to string missing data (but that’s another story for another time as this discussion is focused on SPSS MODELER).
In MODELER, missing information is “dealt with” by declaring them as “blanks”. Note: You need to declare your missing information because by default, neither of the two types of missing information (mentioned above) is defined as a blank value by MODELER. For example, if a field, sex is checked against values Male and Female, with action Abort attached to it, then stream execution is aborted if an empty space is encountered. If it is desired that stream execution is not interrupted in this situation, you need to declare these values as blank values.
Blanks for Strings
String fields with missing values require additional considerations.
- A string value can be empty, which means that it contains nothing (this is called an empty string).
- A string value can be a series of spaces (this is called white space).
Global Knowledge – Introduction to Data Mining: “It is important to distinguish between the normal use of the word “blank” and Modelers use of it; to avoid misunderstanding, the use of the wording “series of spaces” instead of “series of blanks” here – blanks are predefined codes representing missing data”.
Blanks in Your Analysis
It is important to understand that defining blanks does not necessarily have a direct effect on how MODELER treats that value for a field in all nodes.
For example, if the value 99 is defined as a blank value for a field children (number of children); a histogram will include the blank value. One way to work around this would be to replace blank values with the undefined value ($null$), because that value is excluded from graphical displays.

It should be emphasized that how you handle your missing data when developing a model has some complications. If you use only valid records to develop a model to predict and outcome, then you cannot use the model successfully on new data unless all the fields in that file have non missing data.
Defining Blanks
To define blanks in SPSS Modeler, you can use the Missing column on the Type tab of a Type node. The Type node is a general approach to defining blanks and can be inserted at any point in a stream:
- Chick on the Types tab.
- Click in the column Missing for the field that needs blank definitions and select Specify… from the context menu.
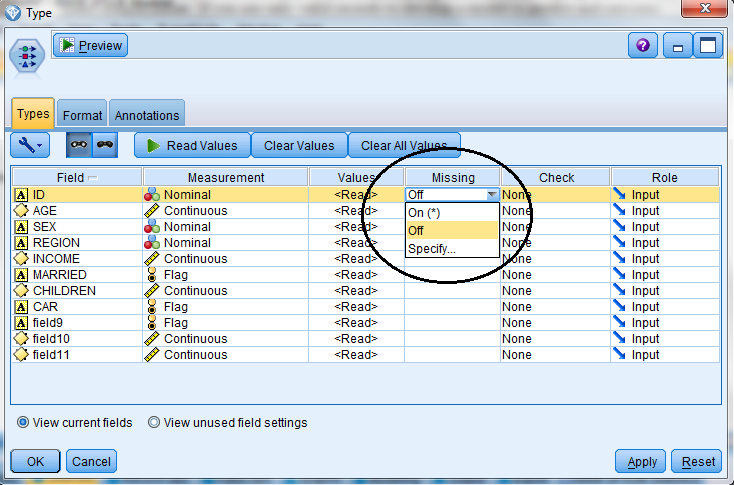
(Once blanks have been defined for a field, an asterisk in the cell in the Missing column indicates that missing values have been defined for that field!)
Numeric v. String
Although the dialogs are the same for numeric and string fields, it is important to note that when we talk about numeric fields we use “blanks whereas with strings, it’s “missing”.
Cheers!