Data loaded into a TM1 or SPSS model will, in most cases, include files consisting of thousands (or hundreds of thousands) of records. It is not reasonable, given the number of fields and records in files of this size, for you to visually inspect all fields in every record (of every file) for missing or invalid values.
Data Transformations
In TM1, data is usually loaded from an EDW or GL system, so (once the initial testing phase has been completed) the probability that incoming data contains unexpected values (should be) somewhat small. However, the data will (most likely) need to be transformed into a format that the TM1 model can use, or is more optimal for the model’s use. Additionally, if data is being manually input to the model (for example a user entering a (sales) forecast value), then inspecting the data for invalid values is required.
With SPSS Modeler, data may come from sources more “sketchy” – marketing surveys, multiple files merged into one or even manually typed-in data. Obviously, the need for auditing and transforming is critical.
Types of Data Violations
Generally, (with TM1 or SPSS) three different types of data violations may be found during the loading process:
- Values do not comply (with a field’s defined storage type). For example, finding a string value in a numeric field.
- Only a set of values or a range of values are allowed for a field and the incoming value does not exist within the defined set or is greater or less than the acceptable range.
- Undefined (SPSS refers to this as $null$ and has “rules” about how it handles these values) values encountered anywhere (no data!).
Actions
When an invalid value (a value violating one of the three rules) is found, one of five possible actions can be taken:
- Nullify – in SPSS, you can convert the value to undefined ($null$) again, this has a special meaning for SPSS, for TM1, this is not usually a viable option since TM1 does not work well with NULL values.
- Coerce – you can convert the invalid to valid. What invalid and valid is usually determined by the measurement level of the field. In SPSS:
- Flags; if not True or False, then it is False
- Nominal, Ordinal; if invalid, it becomes the first member of the sets values
- Continuous; value less than lower bound-> lower bound, value greater than upper bound -> upper bound
- Undefined ($null$) -> midpoint of range
In TM1, this process is more typically a “remapping” from one value to another. For example, translating a product’s code used in one system to that products code used in another.
- Discard – delete the record – with SPSS, you can Discard the record, in TM1, you might use an ItemReject function;
- Warn – invalids are reported in a message window in SPSS, minor errors may be written to the message log in TM1.
- Abort – In SPSS, the first invalid value encountered can result in an error and the stream execution aborted, with TM1, processes can be terminated with the ProcessError function.
Handling data Violations
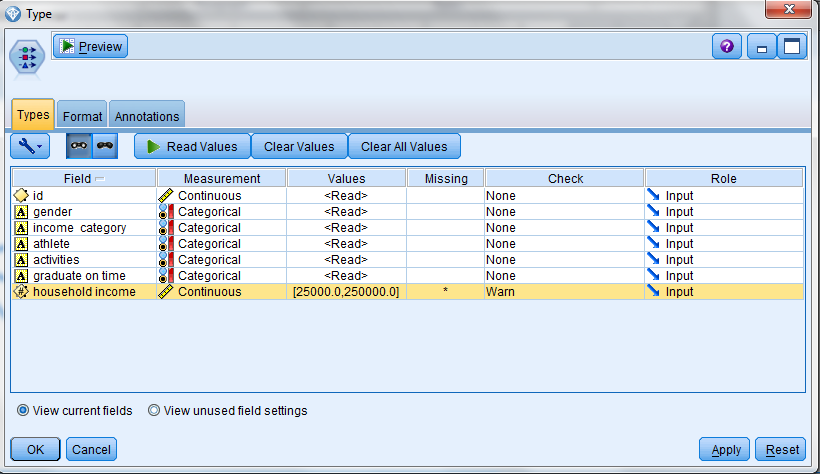
In SPSS Modeler, the Type node enables data checking and transforming. (Checking can also be done using the Types tab in a data source node). To check and transform, you need to specify 1) what the valid values are and 2) the action to be taken:
- Select the Types tab.
- Select the field to check and click in the corresponding cell in the Values column.
- Select Specify values and labels and enter the lower and upper bound.
- Select the action to take when an invalid value is encountered.

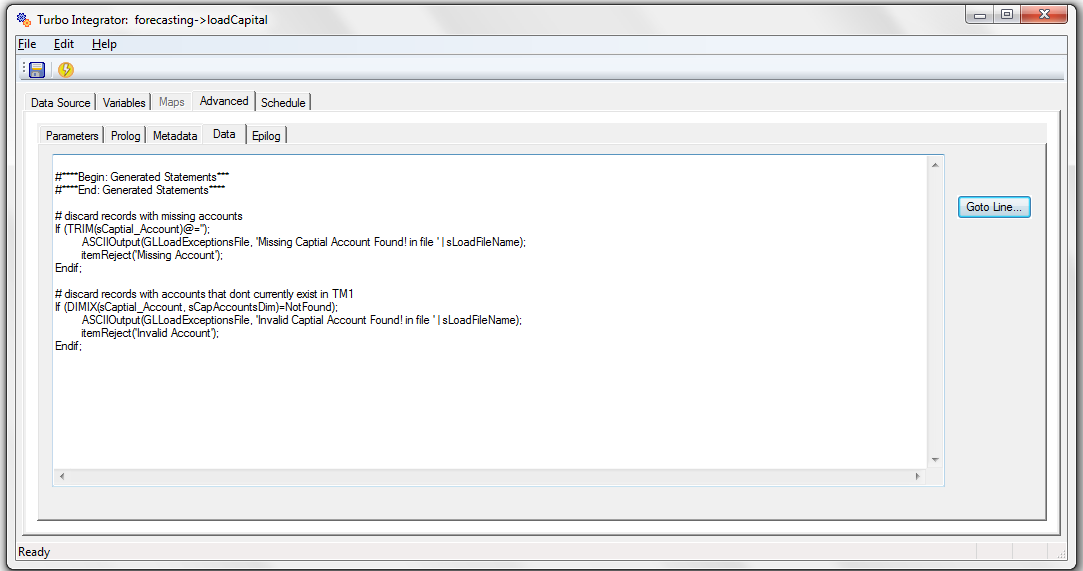
In TM1, checking for and handling (transforming) of invalid values is a little more work.
Using TurboIntegrator processes is the best approach for loading and transforming data in a TM1 model and scripting logic (using predefined functions) is required to evaluate and take action on records being loaded into TM1:
- Select the Data tab.
- Type the script to use the appropriate TM1 functions. Some examples include:
- Checking for invalid data types – Value_Is_String (does the cell contain a string value?)
- Checking data against a set of values – DIMIX (does the value exist in a dimension?)
- Checking data to ensure it is within a range – If (CapitalValue < MaxAllowed & CapitalValue > MinAllowed); (is the value within the allowed range?)
- Checking for missing data (empty fields) – IF (value) @= ‘’ (is the value empty?)
- Save and Run the process.
Conclusion
In both tools you have similar objectives – load data, ensure that the data is “usable” and if it is not, perform an appropriate action (rather than break the model!). SPSS Modeler allows you to do some checking and transforming by selecting values in dialogs, while Cognos TM1 requires you to use TI scripting to accomplish these basic operations. Both can be straight forward or complex and both can be automated and reused on future datasets.