An Interview with Andrew Shuman of Bing
 Key Points from This Interview
Key Points from This Interview
I had a fascinating chat with Andrew Shuman about the adCenter UI and the integration of search and social media. He provided a lot of great insights on what some of the opportunities are, and some of the challenges as well. Here are some of the key points from the interview:
- Re: search and social integration: “There is also a very interesting scale problem there. As with traditional search, we have to query a massive number of servers, but then we also have to take my social graph and overlay that on the search results, modify them, and return this all in milliseconds.”
- “You also have the case where all the people in Seattle seem to be Liking this document. That’s less about me (as a searcher) specifically. Some of those micro-populations become very interesting.”
- Re: the deeper meaning behind a particular search query: “I am not just searching for a restaurant, but I am planning a whole night, and what those things mean for a user, how we can bring together the data in a related fashion.”
- “A restaurant is related to movie theatres that are nearby, right. This creates a new kind of linkage between objects that goes beyond the link graph or the social graph.”
- “It would be really nice that as you just get to restaurant intent, the related intents are there in part of the experience so that as I mouse over or hover over or whatever we come up with it’s probably just another tab then.”
- “Related searches is something where we think we can really experiment a lot more with the placement. For some searches, it may make sense to be more aggressive in the UI with that, as it may be more common for the user to perform follow on searches.”
- “You also have to differentiate a person who does the same search frequently, such as they like to search on Bellevue restaurants a lot. Perhaps the third result is always the restaurant they go to.”
- Re: the strength of social as a signal: “It’s an interesting challenge though, because the more generic signals across the whole web are a much stronger signal. You have billions of clicks versus a hundred friends on Facebook – there is a different science involved in that.”
- Re: how varied people’s intents are: “… not everyone comes to Bing with a specific task in mind, sometimes they are in an exploration mode …”
Full Interview Transcript
Eric Enge: Can you provide a little background on yourself?
Andrew Shuman: I’ve been in Microsoft about nineteen years. I started in Outlook as a developer, and also spent some time with the MSN team. But, now I am at Bing, and it’s been by far my favorite job in Microsoft.
It’s a pretty unique place where you get to work with so many people of varied background in terms of linguistics, and statistics, and math, as well as computer science and that’s fairly fascinating. But then, the problems faced are so rich when you think about the fact that you can type in a three-word search query, and we will show you several results.
But, from a user interface point of view and an application point of view, we are so far away from the joy of a traditional library where you get a sense of the volume of data around you and a sense of where you are within the system.
To help with that, we are constantly looking at different UI models; things like speech and touch that help create the feeling.
Eric Enge: Can you talk a little bit about the challenges of integrating social data and search?
… just because a friend of mine liked a restaurant doesn’t necessarily make it more relevant to me.
Andrew Shuman: One of the interesting areas I was thinking about a little bit this morning is the challenges of tying together the social signal with the other signals, and that it is a very interesting scale problem for us. It obviously is a very different signal to the relevance engine and to the user just because a friend of mine liked a restaurant doesn’t necessarily make it more relevant to me.
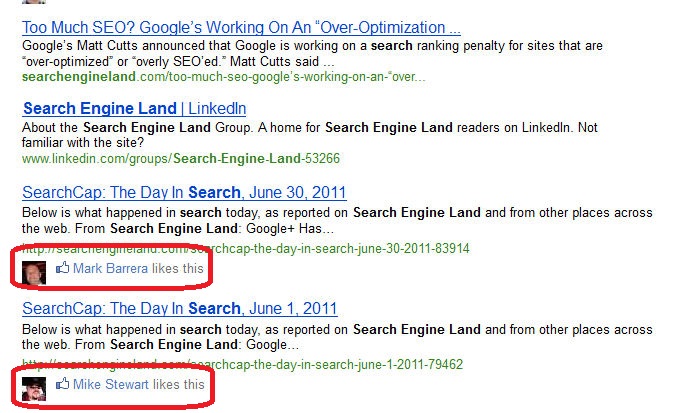 |
The thing that we’ve struggled with in the user interface is how to allow the user to decide if they want those opinions. We have started to play with UI models, and we implemented the Facebook annotations so you could digest the information on your own.
… when it’s a friend who likes a specific article that’s relevant, it’s incredibly useful.
But then, you run into some very interesting poor user experiences. Just because a friend likes Fox News doesn’t necessarily help me at all in my search results. Yet, when it’s a friend who likes a specific article that’s relevant, it’s incredibly useful.
There is also a very interesting scale problem there. As with traditional search, we have to query a massive number of servers, but then we also have to take my social graph and overlay that on the search results, modify them, and return this all in milliseconds. When you think about how we manage our performance and manage our ability to do the calls and the infrastructure that becomes a very interesting technical challenge for us.
We must have the right serving technology to map out the social graph of the user, and then overlay it on the web documents we got back. We may have crawled the document a while ago, but your friend only liked it a minute ago.
Eric Enge: So, if somebody liked it a minute ago, does that mean that you have to recheck the content of the document?
Andrew Shuman: We keep them separate so we have the document in the index, and then at run time we can do the matching of which users Like the documents.
You also have the case where all the people in Seattle seem to be Liking this document. That’s less about me (as a searcher) specifically. Some of those micro-populations become very interesting.
Eric Enge: Let’s talk about user intent.
Andrew Shuman: This is a big area for us. We think a lot about how we can get beyond just the documents to more of the underlying tasks and start to make sure that a segment of tasks really lights up for a user. I am not just searching for a restaurant, but I am planning a whole night, and what those things mean for a user, how we can bring together the data in a related fashion.
This creates a new kind of linkage between objects that goes beyond the link graph or the social graph.

That’s where the ideas of entities underlying the data is really interesting so that I understand that this document references this restaurant, and this restaurant is a first class thing in our system. You can also understand what things are related to that. A restaurant is related to movie theatres that are nearby, right. This creates a new kind of linkage between objects that goes beyond the link graph or the social graph.
Eric Enge: So someone searches on “Seattle Italian Restaurant.” They book something on Open Table, and when they search for a movie you show them the movie theatre close to the restaurant?
Andrew Shuman: Yes, but there are different usage scenarios and this is the struggle we had. Some people just want the website of the restaurant.
But, it’s nice to also allow them to explore, so, in a way we would like to get beyond the basic results without the user even having to type anything more, especially on tablet devices, where typing is such a pain in the butt.
It would be really nice that as you just get to restaurant intent, the related intents are there in part of the experience so that as I mouse over or hover over or whatever we come up with it’s probably just another tab then. I can see the related things, I can find the movies; I can do things very natively without having to do very much.
Eric Enge: How do you approach that?
Andrew Shuman: One approach is bottom’s up – what do the clicks on a query show us? Given that a user typed in a restaurant, and then clicked on a restaurant, and then typed in a movie, and clicked on a movie, we might not even care what those things were. We just know that this query, and this site, we are all related enough of a population that it could be golf courses and golf balls.
It could any kinds of related things. We just recognize this through session analysis, and that’s a very powerful mechanism although you can’t maybe delight the user as much with that. You can’t say that it’s a thing that’s related in a certain way and set the user expectation the right way.
We can recognize specific user scenarios and deliberately implement a UI solution for that.
The other approach is top-down, where we recognize common scenarios that will happen that we can treat as a traditional software project. We can recognize specific user scenarios and deliberately implement a UI solution for that.
Amazon has a very interesting model where they show you people who bought this product also bought these other products. They can remove the mystery about why you are seeing something, and we’ve struggled with how we can do something similar in search.
Eric Enge: A simple version of that is the related searches logic.
Andrew Shuman: Exactly, that’s a very bottom-up example. We are thinking a lot about this. I would say none of us in any of these sites have done a very good job of this. We basically have the autocomplete models, or the related search modules, or the “did you mean” modules.
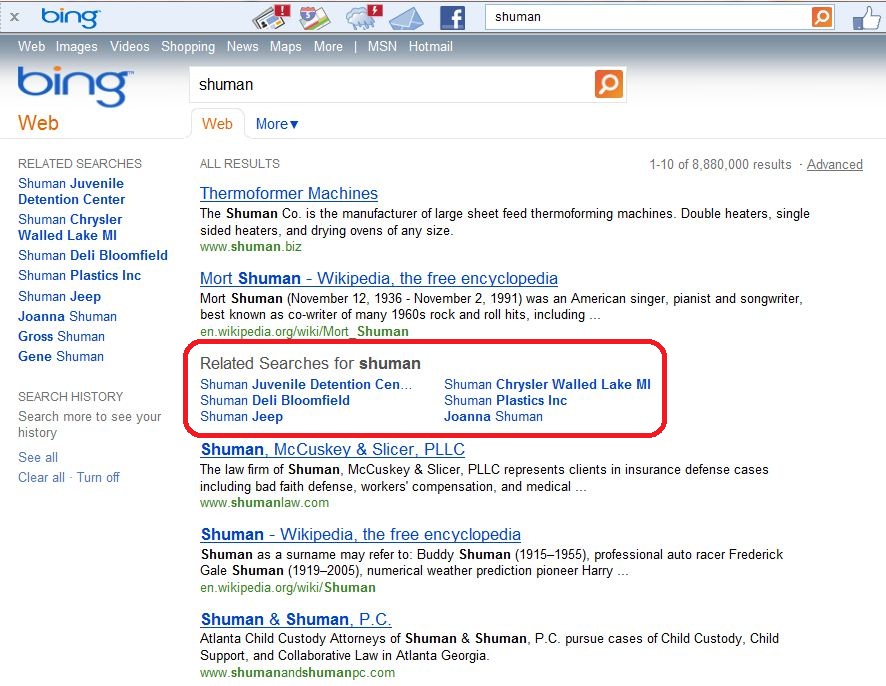
Related searches is something where we think we can really experiment a lot more with the placement.
Related searches is something where we think we can really experiment a lot more with the placement. For some searches, it may make sense to be more aggressive in the UI with that, as it may be more common for the user to perform follow on searches.
They will try more and more words when in fact less is often more useful because their intent is often too broaden, but it doesn’t come across.
People get really frustrated when searching when they are looking for things. They will try more and more words when in fact less is often more useful because their intent is often too broad, but it doesn’t come across. That’s what related search is for.
Eric Enge: You could certainly see a scenario where for certain types of queries the related searches concept gets presented differently in the UI.
Andrew Shuman: Exactly. We do a little bit of this today. You’ll notice at times when we detect a result page that has more diverse click through, so it’s not a clear intent at all, or there is a high impediment. We show related searches right in line at the top.
Eric Enge: What would an example query be?
Andrew Shuman: Queries for places often have it.
 |
Eric Enge: Do you see that happening in the case of related intent queries? Like the example you gave before of a search on “restaurant”, so perhaps you show some related searches for movies. This would be a class of anticipated intent queries.
Andrew Shuman: It’s a really good question. It’s a very hard UI problem to solve in a search engine. We are trying a lot of things around this because the related intent has to happen after your primary intent has been satisfied in many of those cases. We’ve already done some of this with follow-on queries. As you outlined before, right after you’ve found a restaurant in Downtown Bellevue, and you search on movies, we focus on Downtown Bellevue movies theatres.
One thing that I think we would like to play with a lot more is the idea of using different gestures or UI queues to do this (customize UI of the SERPs).
One thing that I think we would like to play with a lot more is the idea of using different gestures or UI queues to do this. For example, what does a scroll mean? It doesn’t necessarily mean you want to see more pages with this text on it.
We could show you more related search suggestions, or even show the results of those related searches on the page.
Eric Enge: You can also imagine a different experience UI where you are inviting people into more of a dashboard experience, such as planning my evening. Then you get a menu of options that shows up, such as a “things to do in Bellevue” box.
Andrew Shuman: Yes. I think the idea of letting you understand what we understand is a strong one.
You also have to differentiate a person who does the same search frequently, such as they like to search on Bellevue restaurants a lot. Perhaps the third result is always the restaurant they go to.
Eric Enge: It’s a complicated problem!
Andrew Shuman: It’s a problem we’ve had since we invented libraries, and we will continue to have it for a long time.
Eric Enge: What if someone searches for nursing schools, and you know from my Facebook profile that I have just graduated high school – you might not show the masters in nursing responses. You might focus on associate programs, or certificate programs. Do you see the potential to draw in other kinds of data sources like that?
Andrew Shuman: Yes, absolutely. There are some really interesting things you could do just based on demographics.
Eric Enge: Right. There is this notion of Bing having a contract with the user where they share that information with you.
Andrew Shuman: Right. It’s an interesting challenge though, because the more generic signals across the whole web are a much stronger signal. You have billions of clicks versus a hundred friends on Facebook – there is a different science involved in that.
Eric Enge: It gets back to just what percentage of audience is sending useful signals from social sites. You have your hundred friends that might be sending out signals that might help you with search for a restaurant in the local area.
Maybe I’ll ask them about it, maybe I’ll check it out, and you create some follow-on action. It gets a little more complex if you are looking for tips on some surgical procedure. You are unlikely to have a friend that had that same procedure.
Do you see any major UX changes coming in the near future?
The home page image with the mouseovers we created had a great response from users.
Andrew Shuman: We are always looking for new things. The home page image with the mouseovers we created had a great response from users. We are eager to do another turn of the crank and how we think of the search results page and really jump out to people again.
Eric Enge: People have really responded to the homepage image?
Andrew Shuman: Yes, we get endless nice feedback on that, it’s worked very well. The nice thing is it promotes the idea of exploration. People really are fascinated, not everyone comes to Bing with a specific task in mind, sometimes they are in an exploration mode, and they can click on the hotspots, they can learn more about the image, and go off on a whole educational or entertaining diversion.
Eric Enge: It’s a little bit serendipity. Have the home page videos worked well for that purpose?
Andrew Shuman: Yes, we had a huge bump in feedback of people loving it. There are a lot more Facebook Shares of the homepage since we started doing that. We only do the videos periodically so we don’t overdo it.
Eric Enge: Thanks Andrew!
Andrew Shuman: Thank you Eric!
About Andrew
Andrew Shuman is the Partner Development Manager for the Bing Experiences Team at Microsoft. He manages the team responsible for Bing Experiences, including the homepage, results page, rich clients, multimedia, and more. Andrew has held several positions in his time at Microsoft where he’s been since 1993.