
In the fast-paced world of artificial intelligence, a new open-source model from Chinese AI firm Minimax is making a significant impact. Released in late October 2025, Minimax M2 has rapidly gained acclaim for its innovative approach to reasoning, impressive performance, and cost-effectiveness, positioning it as a formidable competitor to established proprietary models.
A New Architecture for a New Era
Minimax M2 is a massive Mixture of Experts (MoE) model with a total of 230 billion parameters, but it only activates 10 billion parameters at any given time. This efficient design allows it to achieve an optimal balance of intelligence, speed, and cost, making it a powerful tool for a wide range of applications, particularly in the realm of agentic workflows.
Key Innovations
Minimax M2 introduces several key innovations that set it apart from other reasoning models:
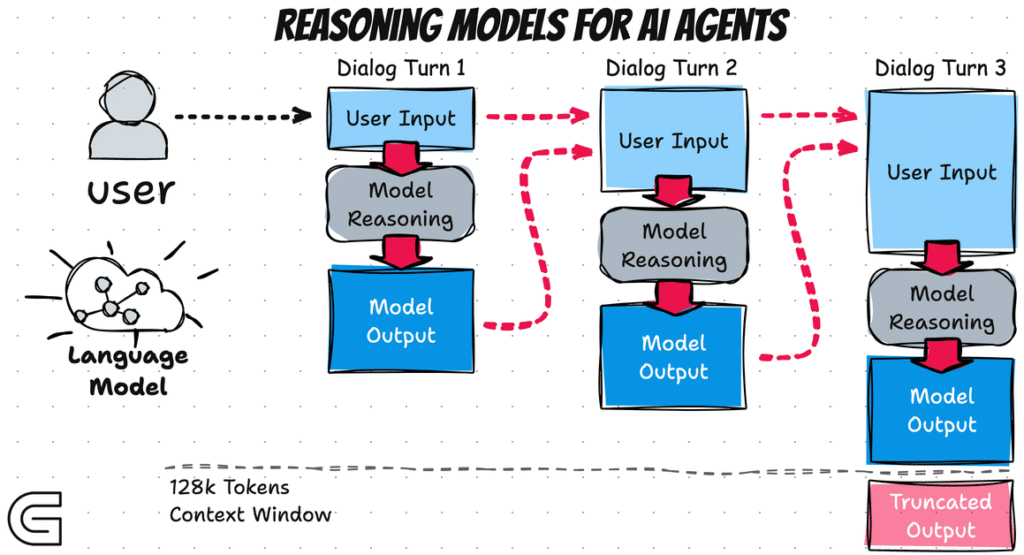
Interleaved Thinking
Traditional reasoning models operate in two distinct phases: first generating reasoning tokens (the “thinking” process) and then generating output tokens (the final response). This can lead to a noticeable delay before the user sees any output. Minimax M2, however, interleaves these two processes, blending reasoning and output tokens together. This “think a bit, output a bit” approach provides a more responsive user experience and is particularly beneficial for agentic workflows, where multi-step agents can now access the reasoning history of previous steps for greater traceability and self-correction.
CISPO Post-Training
Minimax M2 is trained using a novel post-training technique called CISPO (Context-aware Importance Sampling for Policy Optimization). This method, highlighted in Meta’s “Art of Scaling RL Compute,” addresses the instability issues found in traditional methods by adjusting the “importance weight” of entire sequences instead of individual tokens. This makes the training process much more stable, especially for tasks involving long, structured outputs like code generation.
How Minimax M2 Compares to Leading Models

To understand where Minimax M2 stands in the competitive landscape, here’s a detailed comparison with industry leaders GPT-4.1 and Claude Sonnet 4.5:
| Feature | Minimax M2 | GPT-4.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Architecture | Mixture of Experts (MoE) | Dense Transformer | Dense Transformer |
| Total Parameters | 230 Billion | ~1.7 Trillion (estimated) | Undisclosed |
| Active Parameters | 10 Billion | ~1.7 Trillion | Undisclosed |
| Context Window | 128K tokens | 128K tokens | 200K tokens |
| Input Pricing | $0.30 / 1M tokens | $3.00 / 1M tokens | $3.00 / 1M tokens |
| Output Pricing | $1.20 / 1M tokens | $12.00 / 1M tokens | $15.00 / 1M tokens |
| Inference Speed | ~100 tokens/second | ~60 tokens/second | ~50 tokens/second |
| Open Source | ✅ Yes (Apache 2.0) | ❌ No | ❌ No |
| Self-Hosting | ✅ Available | ❌ Not available | ❌ Not available |
| Interleaved Reasoning | ✅ Native support | ❌ No | ❌ No |
| Best Use Cases | Agentic workflows, coding | General purpose, reasoning | Coding, analysis, creative |
Cost Comparison: Real-World Savings
For processing 1 million input tokens and 1 million output tokens:
| Model | Total Cost | Savings vs M2 |
|---|---|---|
| Minimax M2 | $1.50 | Baseline |
| GPT-4.1 | $15.00 | 90% more expensive |
| Claude Sonnet 4.5 | $18.00 | 92% more expensive |
This means that for every $1.50 you spend on Minimax M2, you would spend $15-18 on competing proprietary models for the same workload.
Unprecedented Performance and Cost-Effectiveness
Minimax M2 has demonstrated impressive performance, ranking #1 on OpenRouter’s “Top Today” for agentic workflows and establishing itself as the best open model for coding and agentic tasks. It is also incredibly cost-effective, with an API price of just $0.30 per million input tokens and $1.20 per million output tokens – a mere 8% of the cost of Claude 4.5 Sonnet, with nearly double the inference speed.
| Metric | Value |
|---|---|
| Model Type | Mixture of Experts (MoE) |
| Total Parameters | 230 Billion |
| Active Parameters | 10 Billion |
| Input Token Price | $0.30 / 1M tokens |
| Output Token Price | $1.20 / 1M tokens |
| Inference Speed | ~100 tokens/second |
Why Minimax M2 Matters
The release of Minimax M2 is significant for several reasons:
Cost-Effective Excellence: Minimax M2 delivers high-level intelligence at a fraction of the cost of proprietary models, making advanced AI accessible to startups, indie developers, and cost-conscious enterprises. The 90-92% cost savings compared to GPT-4.1 and Claude Sonnet 4.5 can translate to thousands or even millions of dollars in savings for high-volume applications.
Open-Source Freedom: Being open-source with model weights available under a permissive license allows for self-hosting, inspection, customization, and no per-token fees for on-premises deployment. This is crucial for organizations with strict data privacy requirements or those operating in regulated industries.
Agentic Workflows Champion: The interleaved thinking capability and robust tool use make Minimax M2 the top choice for building complex, multi-step agentic systems. The persistent reasoning traces enable agents to learn from previous steps, self-correct errors, and maintain context across long-running tasks.
Production-Ready Performance: With inference speeds nearly double that of Claude Sonnet 4.5, Minimax M2 can handle high-throughput production workloads without compromising on quality or user experience.
Use Cases
Minimax M2 is well-suited for a variety of applications, including:
- Complex multi-step agentic workflows requiring transparent reasoning
- Self-hosted AI solutions for sensitive projects with data privacy requirements
- Long-running reasoning tasks with tool use and external API integration
- Code generation, analysis, and refactoring at scale
- High-volume production applications where cost efficiency is critical
Read More
Cross-posted from www.linkedin.com/in/matthew-aberham