
Following up on my previous post which highlights different approaches of accessing Oracle Fusion Cloud Apps Data from Databricks, I present in this post details of Approach D, which leverages the Perficient accelerator solution. And this accelerator applies to all Oracle Fusion Cloud applications: ERP, SCM, HCM and CX.
As demonstrated in the previous post, the Perficient accelerator differs from the other approaches in that it has minimal requirements for additional cloud platform services. The other approaches of extracting data efficiently and in a scalable manner require the deployment of additional cloud services such as data integration/replication services and an intermediary data warehouse. With the Perficient accelerator, however, replication is driven by techniques that are solely reliant on native Oracle Fusion and Databricks. The accelerator consists of a Databricks workflow with configurable tasks to handle the end-to-end process of managing data replication from Oracle Fusion into the silver layer of Databricks tables. When deploying the solution, you get access to all underlying python/SQL notebooks that can be further customized based on your needs.
Why consider deploying the Perficient Accelerator?
There are several benefits to deploying this accelerator as opposed to building data replications from Oracle Fusion from the ground up. Built with automation, the solution is future-proof and enables scalability to accommodate evolving data requirements with ease. The diagram below highlights key considerations.


A Closer Look at How Its Done
In the Oracle Cloud: The Perficient solution leverages Oracle BI Cloud Connector (BICC) which is the preferred method of extracting data in bulk from Oracle Fusion while minimizing the impact to the Fusion application itself. Extracted data and metadata is temporarily made available in the OCI Object Storage buckets for downstream processing. Archival of exported data on the OCI (Oracle Cloud Infrastructure) side is also automatically handled, if required, with purging rules.
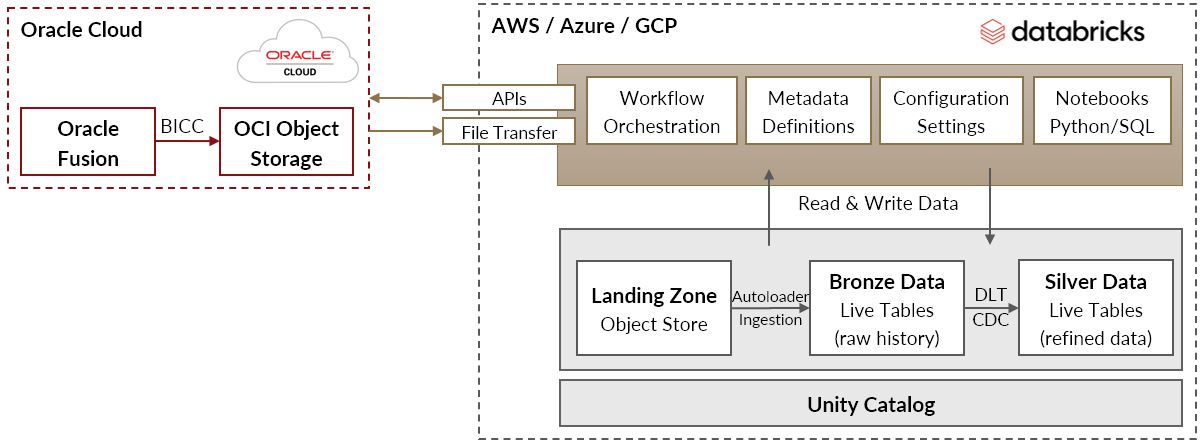
In the Databricks hosting cloud:
- Hosted in one of: AWS, Azure or GCP, the accelerator’s workflow job and notebooks are deployed in the Databricks workspace. The Databricks delta tables schema, configuration and log files are all hosted within the Databricks Unity Catalog.
- Notebooks leverage parametrized code to programmatically determine which Fusion view objects get replicated through the silver tables.
- The Databricks workflow triggers the data extraction from Oracle Fusion BICC based on a predefined Fusion BICC job. The BICC job determines which objects get extracted.
- Files are then transferred over from OCI to a landing zone object store in the cloud that hosts Databricks.
- Databricks AutoLoader handles the ingestion of data into bronze Live Tables which store historical insert, update and delete operations relevant to the extracted objects.
- Databricks silver Live Tables are then loaded from bronze via a Databricks managed DLT Pipeline. The silver tables are de-duped and represent the same level of data granularity for each Fusion view object as it exists in Fusion.
- Incremental table refreshes are set up automatically leveraging Oracle Fusion object metadata that enables incremental data merges within Databricks. This includes inferring any data deletion from Oracle Fusion and processing deletions through to the silver tables.
Whether starting small with a few tables or looking to easily scale to hundreds and thousands of tables, the Perficient Databricks accelerator for Oracle Fusion data handles the end-to-end workflow orchestration. As a result, you end up spending less time with data integration and focus efforts on business facing analytical data models.
For assistance with enabling data integration between Oracle Fusion Applications and Databricks, reach out to mazen.manasseh@perficient.com.