
SAP Databricks is important because convenient access to governed data to support business initiatives is important. Breaking down silos has been a drumbeat of data professionals since Hadoop, but this SAP <-> Databricks initiative may help to solve one of the more intractable data engineering problems out there. SAP has a large, critical data footprint in many large enterprises. However, SAP has an opaque data model. There was always a long painful process to do the glue work required to move the data while recognizing no real value was being realized in that intermediate process. This caused a lot of projects to be delayed, fail, or not pursued resulting in a pretty significant lost opportunity cost for the client and a potential loss of trust or confidence in the system integrator. SAP recognized this and partnered with a small handful of companies to enhance and enlarge the scope of their offering. Databricks was selected to deliver bi-directional integration with their Databricks Lakehouse platform. When I heard there was going to be a big announcement, I thought we were going to hear about a new Lakehouse Federation Connector. That would have been great; I’m a fan.
This was bigger.
Technical details are still emerging, so I’m going to try to focus on what I heard and what I think I know. I’m also going to hit on some use cases that we’ve worked on that I think could be directly impacted by this today. I think the most important takeaway for data engineers is that you can now combine SAP with your Lakehouse without pipelines. In both directions. With governance. This is big.
SAP Business Data Cloud
I don’t know much about SAP, so you can definitely learn more here. I want to understand more about the architecture from a Databricks perspective and I was able to find out some information from the Introducing SAP Databricks post on the internal Databricks blog page.
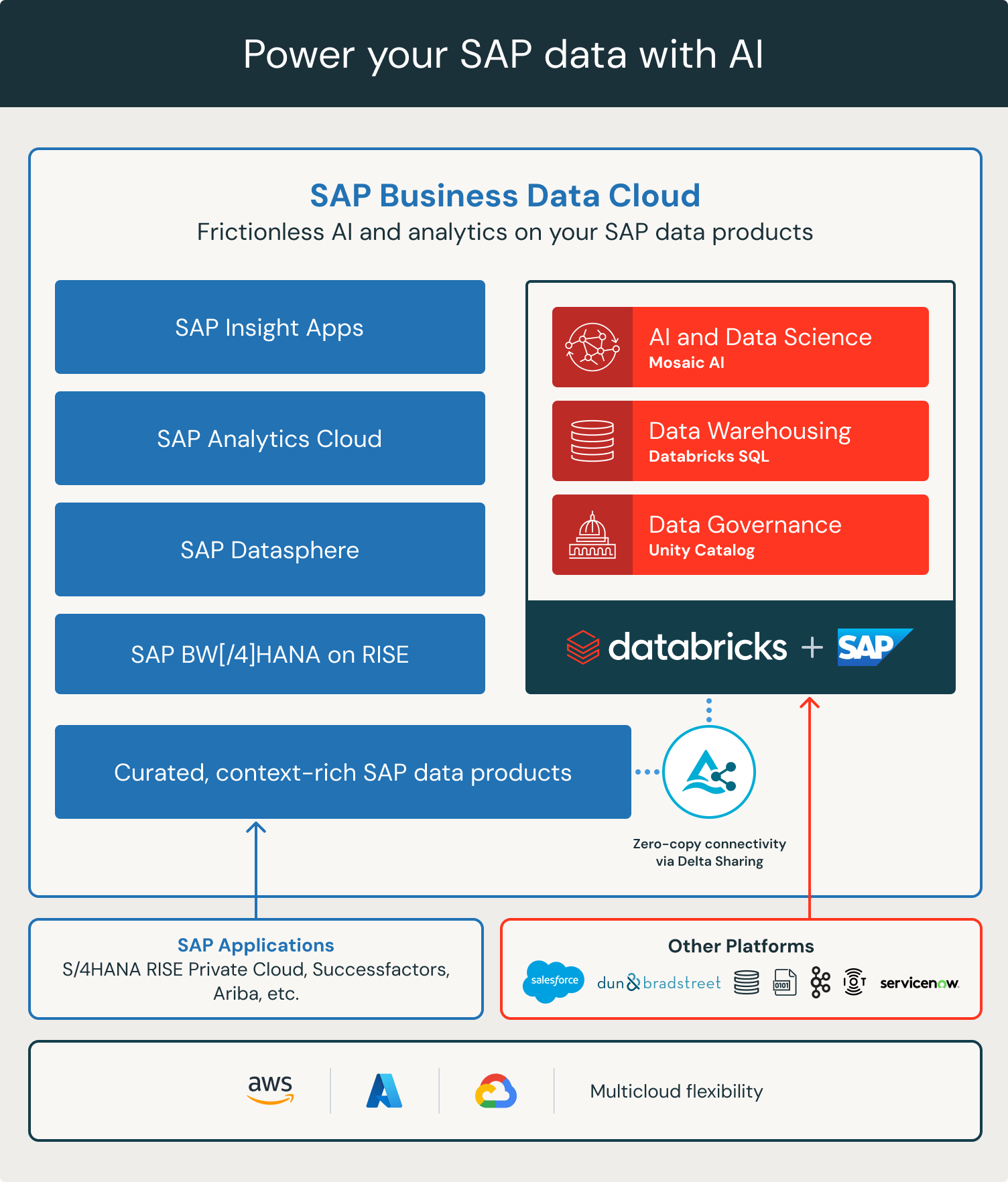 |
This is when it really sunk in that we were not dealing with a new Lakeflow Connector;
SAP Databricks is a native component in the SAP Business Data Cloud and will be sold by SAP as part of their SAP Business Data Cloud offering. It’s not in the diagram here, but you can actually integrate new or existing Databricks instances with SAP Databricks. I don’t want to get ahead of myself, but I would definitely consider putting that other instance of Databricks on another hyperscaler. 🙂 In my mind, the magic is the dotted line from the blue “Curated context-rich SAP data products” up through the Databricks stack. |
Open Source Sharing
The promise of SAP Databricks is the ability to easily combine SAP data with the rest of the enterprise data. In my mind, easily means no pipelines that touch SAP. The diagram we see with the integration point between SAP and Databricks SAP uses Delta Sharing is the underlying enablement technology.
Delta Sharing is an open-source protocol, developed by Databricks and the Linux Foundation, that provides strong governance and security for sharing data, analytics and AI across internal business units, clouds providers and applications. Data remains in its original location with Delta Sharing: you are sharing live data with no replication. Delta Share, in combination with Unity Catalog, allows a provider to grant access to one or more recipients and dictate what data can be seen by those shares using row and column-level security.
Open Source Governance
Databricks leverages Unity Catalog for security and governance across the platform including Delta Share. Unity Catalog offers strong authentication, asset-level access control and secure credential vending to provide a single, unified, open solution for protecting both (semi- & un-)structured data and AI assets. Unity Catalog offers a comprehensive solution for enhancing data governance, operational efficiency, and technological performance. By centralizing metadata management, access controls, and data lineage tracking, it simplifies compliance, reduces complexity, and improves query performance across diverse data environments. The seamless integration with Delta Lake unlocks advanced technical features like predictive optimization, leading to faster data access and cost savings. Unity Catalog plays a crucial role in machine learning and AI by providing centralized data governance and secure access to consistent, high-quality datasets, enabling data scientists to efficiently manage and access the data they need while ensuring compliance and data integrity throughout the model development lifecycle.
Data Warehousing
Databricks is now a first-class Data Warehouse with its Databricks SQL offering. The serverless SQL warehouses have been kind of a game changer for me because they spin up immediately and size elastically. Pro tip: now is a great time to come up with a tagging strategy. You’ll be able to easily connect your BI tool (Tableau, PowerBI, etc) to the warehouse for reporting. There are also a lot of really useful AI/BI opportunities available natively now. If you remember in the introduction, I said that I would have been happy had this only been a Lakehouse Federation offering. You still have the ability to take advantage of Federation to discover, query and govern data from Snowflake, Redshift, Salesforce, Teradata and many others all from within a Databricks instance. I’m still wrapping my head around being able to query Salesforce and SAP Data in a notebook inside Databricks inside SAP.
Mosaic AI + Joule
As a data engineer, I was the most excited about zero-copy, bi-directional SAP data flow into Databricks. This is selfish because it solves my problems, but its relatively short-sighted. The integration between SAP and Databricks will likely deliver the most value through Agentic AI. Lets stipulate that I believe that chat is not the future of GenAI. This is not a bold statement; most people agree with me. Assistants like co-pilots represented a strong path forward. SAP thought so, hence Joule. It appears that SAP is leveraging the Databricks platform in general and MosaicAI in particular to provide a next generation of Joule which will be an AI copilot infused with agents.