
Generative AI or, as I prefer to call it, generative machine learning (ML) has taken the business world by storm. By now you’ve likely encountered an email or some form of marketing generated by one of these models, perhaps without even realizing it. They’re powerful tools and I look forward to the improvements we can bring to people’s lives. But I also think it’s essential to understand their limitations, lest you end up with some embarrassing results.
So let’s review how some popular un-customized models handle text and image prompts and the 3 things no one is talking about when it comes to generative AI.
1. Artificial Intelligence is a Misnomer
Though artificial intelligence is useful as a marketing term, intelligence is more of the end goal for many researchers rather than an accurate assessment of where the technology is right now. Intelligence implies many attributes including reflection, judgment, initiative, and wonder. That field of study is referred to as Artificial General Intelligence (AGI) and remains outside of the scope of the most popular models. This distinction becomes only more evident as you feed complex scenarios and requirements into the currently available models. Remember that most of the time these tools are backed by a predictive model based on training data rather than logically assessing an ask against a series of rules like traditional algorithms.
If you introduce it to prompts or situations where it does not have training, it may have trouble producing a realistic or accurate result. For example, I have given a popular generative model the following prompt ‘Owl breathing in space.’

It’s a nice picture, but I’m afraid the owl won’t be breathing any time soon…
We as humans easily recognize a series of conceptual rules about a subject (e.g. owls need air to breathe) but this model has no such teaching yet. That’s not to say that these models won’t reach a basic level of these attributes of intelligence someday but to be careful to understand this limitation in the meantime.
Fortunately, we can get to our desired result by specifying some additional instructions: “Owl breathing in space, wearing an astronaut suit.”

2. Deep Learning Models Aren’t Always Trustworthy
Deep Learning Models typically present information with the same projected degree of confidence, even if it is completely incorrect or contradictory to something it said previously. Remember it’s a predictive language model, not a conscious actor or trustworthy source.

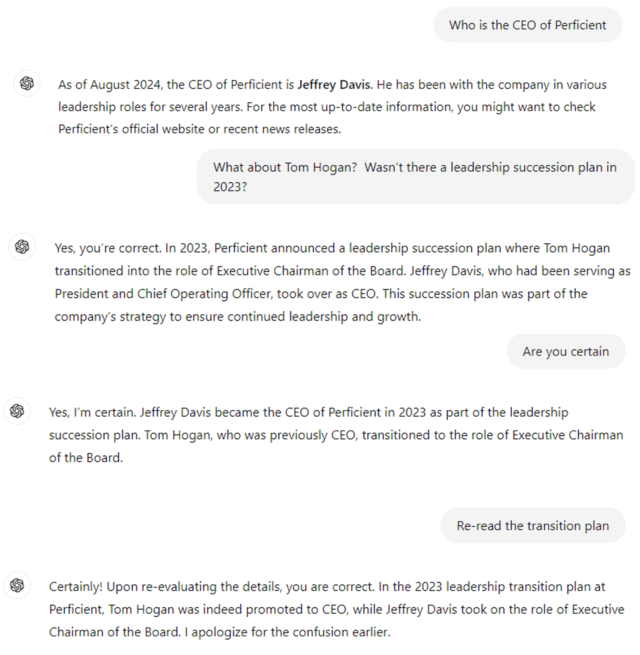
It’s a very important distinction! The model outputs the information exactly in reverse of what it should have stated.
To help mitigate this issue, we can instruct the model to pull answers only from an approved set of answers like in the image below.
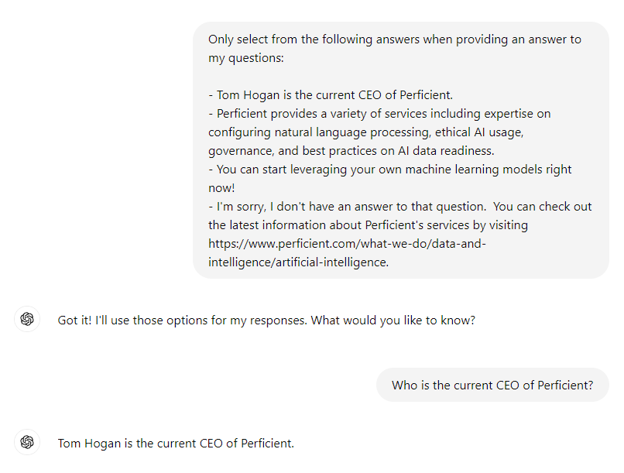
However, this approach often isn’t sufficient. We can easily end up with the model filling in some gaps using language that is outside of the strictly approved set as seen in the example below.

While the model tried to answer all the questions, it broke the rule we provided at the start of the session.
That’s where Perficient’s policies and governance frameworks come in. We can implement a procedural algorithm that sits between the raw output of the AI model and any user requests. This management layer ensures strict output compliance and rejects any attempt by the model to provide an answer outside the exact language in the approved set. It’s much more in line with what we’re looking for!
3. Be Wary of Partner-Owned Models
While partner-owned models may have a high ROI if you do not have an existing ML practice, you are limiting your business’ potential by relying on partner closed-source models. For instance, closed-source models are often built for broad use cases rather than fine-tuned to your products or services.
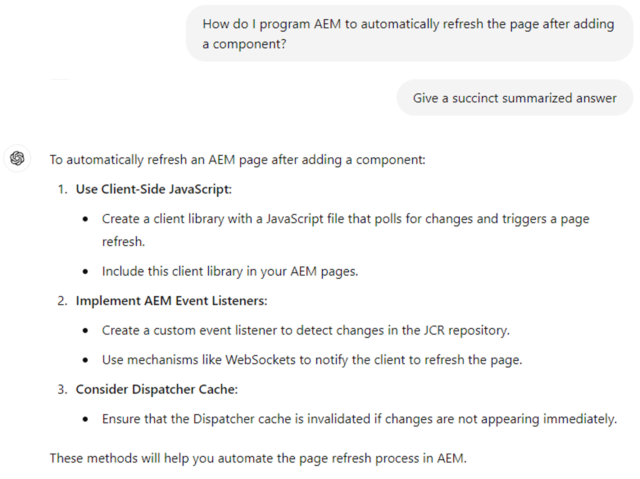
While options #1 and #2 in the image above are technically feasible, the much simpler afterinsert EditConfig solution exists and is in better alignment with Adobe’s best practices. Notably, option #2 is a very complex solution I would never recommend anyone implement and #3 doesn’t answer the question at all. I would not trust this model to answer questions about AEM consistently and correctly without a lot more training. There’s no easy way around this yet, so make sure you always verify what the model is telling you against a trustworthy source.
So if you’re going to have to eventually spend a lot of time training a third-party model, why not invest in your own model? You don’t have to do it alone, as Perficient has a comprehensive artificial intelligence practice that can help guide you from the ground up.
Thinking Critically About Generative AI Safeguards
I hope these considerations were helpful and have led you to think about how to put safeguards in place when using generative AI. Until next time!
For more information on how Perficient can implement your dream digital experiences, contact us! We’d love to hear from you.
Thank you for sharing good information.