
Validating the content of PDF files that an application generates is a common task while testing web applications. To do this, utilize PDFBox, a Java library for managing PDF documents, in combination with Selenium, a potent web automation tool. This post will demonstrate how to use PDFBox and Selenium to read and validate PDF text information in a browser.
-
Prerequisites
Before we begin, ensure you have the following:
- Java Development Kit (JDK)
- Eclipse IDE (or any other Java IDE)
- Selenium WebDriver library
- PDFBox library
- Chrome WebDriver
-
Apache PDFBox
-
Overview:
An open-source Java package called Apache PDFBox offers many features for interacting with PDF documents. It enables the creation, modification, and extraction of content from PDF files by developers. A popular tool for Java programs looking to process PDF files is called PDFBox, which is a component of the Apache Software Foundation.
-
Key Features:
- PDF Creation: Enables the creation of new PDF documents from scratch.
- PDF Manipulation: Allows adding or modifying text, images, and annotations in existing PDFs.
- Content Extraction: Supports extracting text and images from PDF files for analysis or processing.
- Form Handling: Facilitates working with interactive PDF forms, filling out fields, and extracting form data.
- Encryption and Decryption: Provides functionalities to encrypt and decrypt PDF files to ensure document security.
-
Use Cases:
- Generating PDF reports or documents from Java applications.
- Extracting text and metadata for data processing and analysis.
- Modifying existing PDF files for content updates or corrections.
- Handling PDF forms in automated workflows for data entry and extraction.
-
Setting Up the Project
- Create a New Java Project in Eclipse: Open Eclipse, go to File > New > Java Project and create a new project.
- Add Selenium and PDFBox Libraries: Download the Selenium WebDriver and PDFBox libraries and add them to your project’s build path.
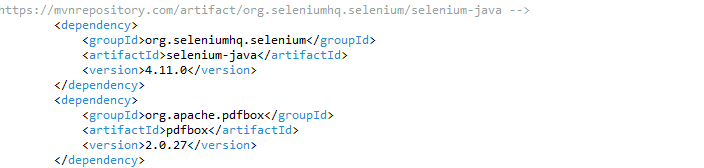
Step 1: Set Up Selenium WebDriver

First, set up the Selenium WebDriver to open the browser and navigate to the page with the PDF link.
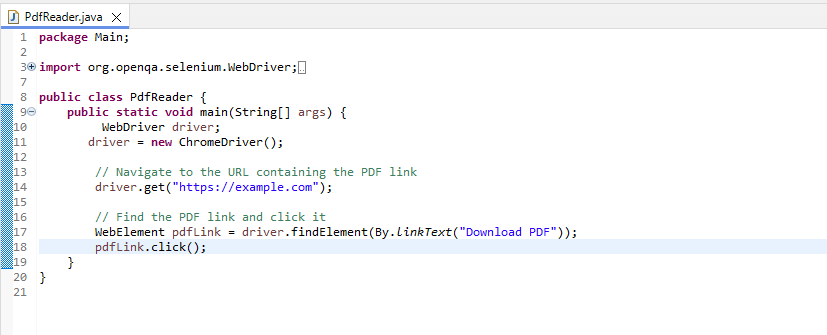
Step 2: Download the PDF
Next, download the PDF file to your local machine.
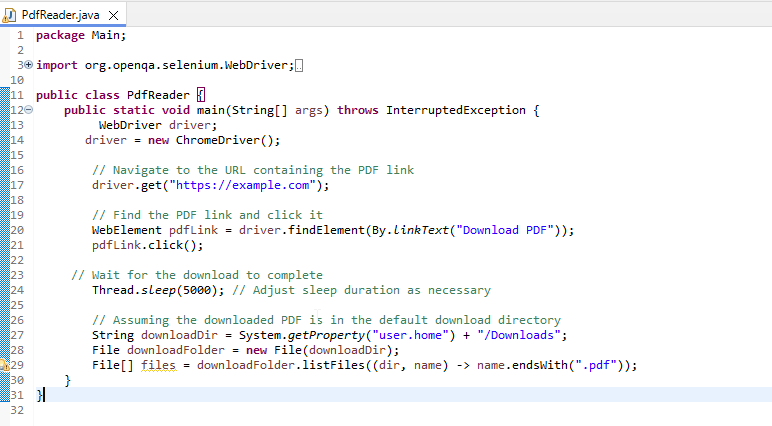
Step 3: Validate the PDF Content Using PDFBox
Now, use PDFBox to read and validate the PDF content.
Conclusion
These techniques will let you use PDFBox with Selenium to efficiently read and validate PDF document text in a browser. This method is very helpful for automatically testing online apps that produce PDF documents or reports to make sure the content satisfies the required standards. You may construct reliable test suites for your applications by combining the capabilities of PDFBox for PDF manipulation and Selenium for web automation.