
Intro 📖
In the new composable world, it’s common for medium to large Sitecore solutions to include a search appliance like Coveo and a digital asset management tool like Sitecore Content Hub. A typical use-case is to build search sources in Coveo that index content residing in Content Hub. Those indexes, in turn, can then be used to build front-end search experiences. In this blog post, I’d like to cover a few tips for working with the Content Hub REST API to populate search sources in Coveo. These tips are based on my experiences on a recent project that used the Content Hub REST API to index PDF documents in Coveo.
#1 – Knowing Which API to Use 🤔
Having not previously used the Content Hub REST API, I wasn’t initially aware that there are several endpoints. Here’s a quick rundown of a few of them:
Query API (GET http://<hostname>/api/entities/query/)
The Querying feature allows you to query for specific entities using specific indexed metadata fields. This basic querying is contrasted against the more elaborate search functionality offered by the M.Content API.
Scroll API (GET http://<hostname>/api/entities/scroll/)
You can use Scroll API to retrieve a large number of results (or even all results) from a single query.
It does not support the skip parameter and only lets you request the next page through the resource. You can continue paging until it no longer returns results or you have reached the last page.
SearchAfter API (POST http://<HOSTNAME>/api/entities/searchafter/)
The SearchAfter API is used to fetch multiple pages of search results sequentially. To start, a request is made for the first page of results, which includes a last_hit_data value corresponding to the last item in the page. This value is then used to fetch subsequent pages until all results are retrieved.
On this particular project, the Query API was used to pull PDFs. By design, the Query API returns a maximum of 10k results. In this case, that was okay–there were something like ~9k assets in Content Hub at the time (without any additional filtering applied). However, in order to future-proof the query a little and to avoid unnecessary processing of non-PDF documents, it made sense to make the query more specific (see #2, below 👇).
Net out: If you know you’ll need to pull 10k+ items from Content Hub and efficiently paginate through all of them, use the SearchAfter API. If your number of assets is smaller than 10k, then the Query API is probably fine. Note that the SearchAfter API will soon deprecate and replace the Scroll API so it’s best to avoid the Scroll API for any new work.
#2 – Filtering on Media Type and Approval Status 🔮
I like to think that I can figure most things out if I read the documentation. However, when it came to updating the query to filter down to approved PDFs for indexing, it wasn’t at all clear to me how to do that. As mentioned above, the Query API is limited to 10k results and we were pretty close to that in terms of total asset count. It was important to be more selective when pulling assets such that only approved PDFs were returned.
After unsuccessfully experimenting for while, I broke down and opened a Sitecore support ticket to ask how that could be accomplished. I got an answer…and it worked, but it wasn’t as obvious as I would have liked it to be. Who likes magic numbers? 🧙♂️✨
To query for PDF assets: ... AND Parent('AssetMediaToAsset').id==1057.
To ensure that only approved assets are included: ... AND Parent('FinalLifeCycleStatusToAsset')==544.

Putting it together, the full query URL (without any ordering applied; see #3 below 👇) was:
{baseURL}/api/entities/query?query=Definition.Name=='M.Asset' AND Parent('AssetMediaToAsset').id==1057 AND Parent('FinalLifeCycleStatusToAsset').id==544
In other words:
Give me all assets whose file type is PDF and whose approval status is approved.
Now, I think these IDs are common across all Content Hub instances but, just in case, please make sure they match the appropriate values in your Content Hub instance prior to using the same IDs in your queries. You can find the asset media type IDs under Taxonomy Management in Content Hub:
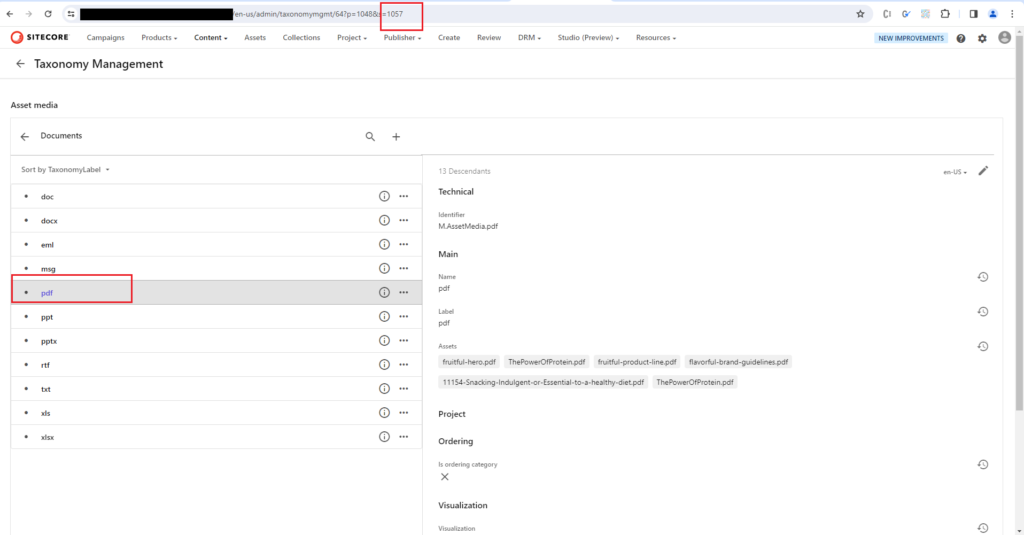
Asset media types in Content Hub’s Taxonomy Management interface.
#3 – Sorting 🔼
When you’re building a REST API source in Coveo with the intention of iterating through hundreds or thousands of assets in Content Hub, it’s best to return them in a consistent order. At one point during the troubleshooting of some indexing issues, Coveo support suggested that the Content Hub API was returning results in an inconsistent order and that that was potentially a contributing factor. While that was never conclusively shown to be the case, it does make sense to apply a sort, even if only to ensure assets are processed in a specific, predictable order.
The query was updated to sort on createdOn ascending (oldest first); the updated query URL looked like this:
{baseURL}/api/entities/query?query=Definition.Name=='M.Asset' AND Parent('AssetMediaToAsset').id==1057 AND Parent('FinalLifeCycleStatusToAsset').id==544&sort=createdOn&order=Asc
Interestingly enough, I found that created_on worked, too, but, according to Sitecore support, createdOn should be used instead.
#4 – Paging 📃
REST API sources in Coveo will almost always be configured to paginate through the results coming from the external API, otherwise only the first page’s worth of data will be processed and indexed. It’s important to ensure paging is configured correctly to allow for reasonable index rebuild and rescan times, too. In this case, using the Query API, and with a page size of 25 items per page, the paging configuration section in the Coveo REST API source looked like this:
...
"paging": {
"pageSize": 25,
"offsetType": "url",
"nextPageKey": "next.href",
"parameters": {
"limit": "take"
},
"totalCountKey": "total_items"
},
...
The corresponding paging properties as returned in the Query API response (for the first page) looked like this:
{
"items": [ ... ],
"total_items": 12345,
"returned_items": 25,
"next": {
"href": "https://{baseURL}/api/entities/query?skip=25&take=25&query=Definition.Name%3D%3D%27M.Asset%27%20AND%20Parent(%27AssetMediaToAsset%27).id%3D%3D1057%20AND%20Parent(%27FinalLifeCycleStatusToAsset%27).id%3D%3D%20544&sort=createdOn&order=Asc",
...
},
...
}
Note that the paging configuration may need to change if you’re using a different Content Hub API endpoint. For more information about configuring paging in Coveo REST API sources, refer to the official documentation.
#5 – File Size Can Affect Document Properties in Extensions 🏋️♂️
In Coveo, the maximum size for a single item is approximately 256 MB (reference). That number includes the item’s permissions, metadata, and content. For larger files, the content isn’t indexed, just the metadata. This limit came to light indirectly on this recent project.
While outside the scope of this post, Coveo supports extensions that can be attached to search sources. Extensions are bits of Python code that Coveo will run in the context of each document while processing the source. On this project, an extension was used to do things like conditionally reject (skip indexing) documents, set metadata fields based on other properties, etc. At one point, the extension attempted to resolve the extension (file type) for the document using the following code:
filetype = document.get_meta_data_value("detectedfiletype")[0]
For any documents not above the maximum size, the filetype variable would have the expected value: "pdf". For any documents that were above the maximum size, the variable had a generic value that, while non-empty, was also not the expected file type. Because the document was too large, the document object available within the extension didn’t have the expected values, including detectedfiletype. As a result, because the file was large, some logic within the extension broke as this case wasn’t accounted for.
Upon further investigation of the PDFs in Content Hub, it was noted that, of the 10 or so that consistently exhibited indexing issues, all of them were 300+ MB in size.
For more information on indexing pipeline extensions (IPE), please see Indexing pipeline extension overview.
Net out: If you’re using an extension on a source and you’re noticing that the document object has one or more properties that aren’t returning what you’d expect to see, double-check to ensure that the underlying document isn’t > 256 MB and that you aren’t trying to access properties within the extension that will never correctly resolve.
Thanks for the read! 🙏