
In the world of big data processing, efficient and scalable file systems play a crucial role. One such file system that has gained popularity in the Apache Spark ecosystem is DBFS, which stands for Databricks File System. In this blog post, we’ll explore into what DBFS is, how it works, and provide examples to illustrate its usage.
What is DBFS?
DBFS is a distributed file system that comes integrated with Databricks, a unified analytics platform designed to simplify big data processing and machine learning tasks. It builds on top of existing file systems like Amazon S3, Azure Blob Storage, and Hadoop HDFS, providing a layer of abstraction and additional functionalities for Spark applications.
How does DBFS work?
DBFS provides a unified interface to access data stored in various underlying storage systems. It uses a concept called “mount points” to seamlessly integrate different storage services into a single file system hierarchy. This allows users to interact with data using standard file system commands and Spark APIs without worrying about the specific storage backend.
Examples of DBFS Usage:
Mounting Data Storage:
# Mounting Amazon S3 Bucket
dbutils.fs.mount(
source = "s3a://your-s3-bucket/",
mount_point = "/mnt/s3",
extra_configs = {"<your-config-key>": "<your-config-value>"}
)
The dbutils.fs.mount() function is a Databricks utility function that users employ to mount external storage systems such as Amazon S3, Azure Blob Storage, Google Cloud Storage, etc., onto DBFS. Mounting a storage system allows you to access files in that storage system using standard DBFS file paths.
Reading Data:
# Reading data from DBFS
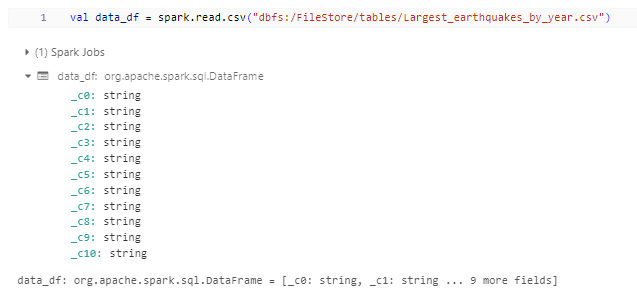
val data_df = spark.read.csv("dbfs:/FileStore/tables/Largest_earthquakes_by_year.csv")
The code will read the specified CSV file into a DataFrame named data_df, allowing further processing and analysis using Spark’s DataFrame API.
Output:
Writing Data:
# Writing data to DBFS
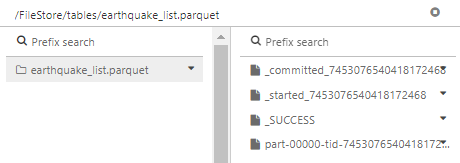
data_df.write.parquet("dbfs:/FileStore/tables/earthquake_list.parquet")
The code will write the contents of the DataFrame data_df to a Parquet file at the specified location. Parquet files are well-suited for Spark applications because they offer efficient storage and optimized performance for columnar data processing.
Output:
Managing Files and Directories:
- Listing the files in a directory
# List files in a directory
val files = dbutils.fs.ls("dbfs:/FileStore/tables")
The variable files will contain a list of file metadata objects, where each object represents a file or directory within the specified directory path. The file metadata typically includes information such as file name, size, modification time, and permissions. This list can be further processed or analyzed as needed within your Databricks notebook or application.

Output:

- Creating a directory
# Create a directory
dbutils.fs.mkdirs("dbfs:/FileStore/tables/new_directory")
A new directory named new_directory will be created within the mounted dbfs. If the directory already exists, this function will not throw an error; it will simply return without making any changes. This functionality allows you to safely create directories without worrying about inadvertently overwriting existing directories.
Output:
- Removing a file
# Delete a file
dbutils.fs.rm("dbfs:/FileStore/tables/Largest_earthquakes_by_year-2.csv")
The file named file.csv located at the specified path will be deleted from the mounted dbfs. If the file does not exist at the specified path, this function will not throw an error; it will simply return without making any changes. This behavior allows you to safely attempt to remove files without worrying about errors if the file does not exist.
# Delete a file
dbutils.fs.rm("dbfs:/FileStore/tables/Largest_earthquakes_by_year-2.csv", "true")
After executing this code, the file “dbfs:/FileStore/tables/Largest_earthquakes_by_year-2.csv” will be deleted from the Databricks File System. If the file does not exist at the specified path, the function call will return without making any changes.
- Deleting a folder:
#Delete a folder
dbutils.fs.rm("dbfs:/FileStore/tables/new",true)
When set to true, it means that if the specified path refers to a directory, the function will recursively delete the directory and all its contents. If set to false, it will only delete the specified file or empty directory without recursion.
- Copying a file from one location to another
#Copy a file from one location to another in DBFS
dbutils.fs.cp("dbfs:/FileStore/tables/Largest_earthquakes_by_year.csv", "dbfs:/FileStore/tables/new/Largest_earthquakes_by_year.csv")
Copies the file located at dbfs:/FileStore/tables/Largest_earthquakes_by_year.csv to dbfs:/FileStore/tables/new/Largest_earthquakes_by_year.csv within the mounted dbfs.
- Moving (renaming) a file in DBFS
#Moving (renaming) a file in DBFS
dbutils.fs.mv("dbfs:/FileStore/tables/new/Largest_earthquakes_by_year.csv", "dbfs:/FileStore/tables/new/Largest_earthquakes_new_list.csv")
renames the file located at dbfs:/FileStore/tables/new/Largest_earthquakes_by_year.csv to dbfs:/FileStore/tables/new/Largest_earthquakes_new_list.csv within the mounted dbfs.
- Checking if a file exists in DBFS
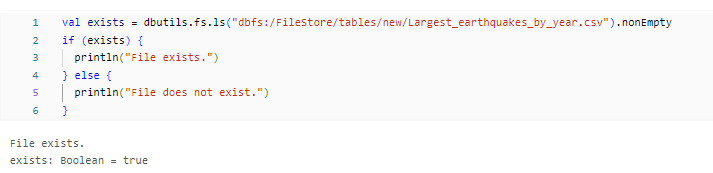
#Checking if a file exists in DBFS
val exists = dbutils.fs.ls("dbfs:/FileStore/tables/new/Largest_earthquakes_by_year.csv").nonEmpty
if (exists) {
println("File exists.")
} else {
println("File does not exist.")
}
This code checks if the file dbfs:/FileStore/tables/new/Largest_earthquakes_by_year.csvv exists within the mounted S3 bucket. If the file exists, it prints “File exists.”; otherwise, it prints “File does not exist.”
Output:
Performance Optimization:
# Configure optimal file format for performance
spark.conf.set("spark.databricks.io.cache.enabled", "true")
spark.conf.set("spark.databricks.io.cache.maxDiskUsage", "50g")
spark.conf.set("spark.databricks.io.cache.timeout", "10m")
- spark.conf.set(“spark.databricks.io.cache.enabled”, “true”):
- This configuration enables caching for Databricks I/O operations.
- When set to “true”, Databricks runtime will utilize caching mechanisms to improve the performance of I/O operations, such as reading data from external storage systems like Azure Blob Storage or Amazon S3.
- spark.conf.set(“spark.databricks.io.cache.maxDiskUsage”, “50g”):
- This configuration sets the maximum disk usage allowed for caching in Databricks runtime.
- In this case, set the parameter to “50g”, indicating 50 gigabytes.
- This parameter controls the amount of disk space available for caching data.
- If the cached data exceeds this limit, the system may evict older cached data to make room for new data.
- spark.conf.set(“spark.databricks.io.cache.timeout”, “10m”):
- This configuration sets the timeout for cached data in Databricks runtime.
- In this case, set it to “10m”, indicating 10 minutes.
- This parameter determines the duration for which cached data remains valid before the system considers it stale and potentially evicts it from the cache.
- Setting a timeout helps ensure that cached data remains fresh and reflects any updates made to the underlying data source.
By configuring these parameters, you can fine-tune the caching behavior in Databricks runtime to optimize performance and resource usage based on your specific workload and requirements.
Conclusion:
DBFS simplifies data management and access for Spark applications by providing a unified file system interface across various storage services. It abstracts away the complexities of dealing with different storage backends, making it easier for data engineers and data scientists to focus on their analysis and machine learning tasks. By using DBFS effectively, organizations can harness the power of Apache Spark for scalable and efficient big data processing.
In this blog post, we’ve covered the basics of DBFS along with practical examples to illustrate its usage in Apache Spark environments. Whether you’re working with Amazon S3, Azure Blob Storage, or Hadoop HDFS, DBFS offers a seamless and efficient way to interact with your data, ultimately enhancing productivity and performance in big data analytics workflows.
References:
Official Spark Documentation: Spark SQL and DataFrames – Spark 2.3.0 Documentation (apache.org)
Official DBFS Documentation: What is the Databricks File System (DBFS)? | Databricks on AWS