
Almost anyone attending XM Cloud sessions at SUGCON North America earlier saw GraphQL queries as a part of such presentations. For mature headless developers getting through each query requires some amount of time, while for newbies that “user-friendly” syntax stands as an unreachable barrier. Once in the past, I failed to find any good article about this without any doubt great query language – some of them were way too excessive while others missed out on a lot of basics. I decided to fill this gap by creating this article providing exactly that: the minimum required information for the maximum productive start. I write it for you in that exact manner as I wish it was written for me earlier.

What is QraphQL and why do I need it?
QraphQL is a query language and backend framework for open-source APIs introduced by Facebook in 2012 and was designed to make it easier managing endpoints for REST-based APIs. In 2015, GraphQL was made open source, and Airbnb, GitHub, Pinterest, Shopify, and many other companies now use GraphQL.
When Facebook developers created a mobile application, they looked for ways to speed things up. There was a difficulty: when simultaneously querying from different types of databases, for example from cloud Redis and MySQL, the application slowed down terribly. To solve the problem, Facebook came up with its own query language that addresses a single endpoint and simplifies the form of the requested data. This was especially valuable for a social network with lots of connections and requests for related elements: say, getting posts from all subscribers of user X.
REST is a good and functional technology, but it has some problems:
- Firstly, there’s redundancy or lack of data in the response. In REST APIs, clients often receive either too much data that they don’t need, or too little, forcing them to make multiple requests to get the information they need. GraphQL allows clients to request only the data they need and receive it in a single request, making communication more efficient.
- Also, in a REST API, each endpoint usually corresponds to a specific resource, which can lead to extensibility problems and support for multiple API versions. GraphQL, however, features a single endpoint for all requests, and the API schema is defined serverside. This makes the API more flexible and easier to develop.
- When working with related data in many REST APIs, the N+1 requests problem arises, when obtaining related data makes you doing additional request roundtrips to a server. GraphQL allows you to define relationships between requested data and retrieve everything required in a single query.
Coming back to the above use case – a social network has many users, and for each user, we require to get a list of his latest posts. To obtain such data in a typical REST API, one needs to make several requests: one request to the users endpoint to obtain a list of users, followed by another request to the posts endpoint to obtain posts for all required users deriving from the previous request (in the worst case it implements as a request for each the desired user). GraphQL solves this problem more efficiently. You can request a list of users and at the same time specify what exactly you want to get with the user details, in our case – the latest posts for each user.
Take a look at the example of GraphQL query implementing exactly that: request users with their 5 most recent posts:
query {
users {
id
name
posts(last: 5) {
id
text
timestamp
}
}
}
What makes this work? This works thanks to the GraphQL structure.
But why at all it has a Graph in its name? That’s because it represents a data structure in the form of a graph, where the nodes of the graph represent objects, and there are connections between these objects. This reflects the way data and queries are organized in GraphQL, where clients can query related data as well as only the data they need.
A graph shows the relationships of say a social network:
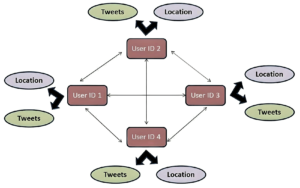
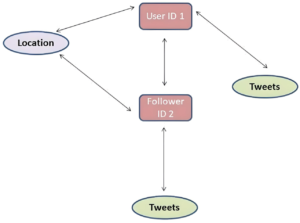
How do we access a graph via GraphQL? GraphQL goes to a specific record, called the root node, and instructs it to get all the details of that record. We can take, for example, user 1, and get their subscriber data. Let’s write a GraphQL query snippet to show how to access it:
query {
user(id: "1") {
followers {
tweets {
content
}
}
}
}
Here we are asking GraphQL to navigate to the graph from the root node, which is the user object with argument id: 1, and access the content of the follower’s tweet.
So far, so good. Let’s discuss query types there are in GraphQL in more detail.
GraphQL Request Types
There are three main request types in GraphQL:
- Query
- Mutation
- Subscription
Sitecore uses only the first two and does not support subscriptions, but to keep this guide full I will still mention how they work.
Queries in GraphQL
We have already become familiar with them in our examples earlier.
Using a query, GraphQL receives the necessary data from the server. This request type is an analog of what GET does in REST. Requests are string values sent in the body of an HTTP POST request. Please note that all GraphQL request types are sent via POST which is de-facto the most common option of HTTP data exchange. GraphQL can also work over Websockets, gRPC, and on top of other transport protocols.
We have already seen Query examples above, but let’s do it again to get the fname and age of all users:
query {
users {
fname
age
}
}
The server sends response data in JSON format so that the response structure matches the request structure:
data : {
users [
{
"fname": "Mark",
"age": 23
},
{
"fname": "David",
"age": 29
}
]
}
The response contains JSON with the data key and also the errors key (in case there are any errors). Below is an example of a faulty response when an error occurred – due to the fact that Maria’s age was mistakenly passed as a string value:
{
"errors": [
{
"message": "Error: 'age' field has incorrect value 'test'.",
"locations": [
{
"line": 5,
"column": 5
}
],
"path": ["users", 0, "age"]
}
],
"data": {
"users": [
{
"fname": "Maria",
"age": "test"
},
{
"fname": "Megan",
"age": 32
}
]
}
}
Mutations in GraphQL
Using mutations you can add or modify the data. Mutation is an analogue of POST and PUT in REST. Here’s a mutation request example:
mutation createUser{
addUser(fname: "Martin", age: 42) {
id
}
}

This createUser mutation adds a user with fname Martin and age 42. The server sends a JSON response to this request with the result record id. The answer may look like below:
data : {
addUser : "a12e5d"
}
Subscription in GraphQL
With the help of subscriptions, the client receives database changes in real-time. Under the hood, subscriptions use WebSockets. Here’s an example:
subscription listenLikes {
listenLikes {
fname
likes
}
}
The above query can, for example, return a list of users with their names and the count of likes every time it changes. Extremely helpful!
For example, when a user with fname Matt receives a like, the response would look like:
data: {
listenLikes: {
"fname": "Matt",
"likes": 245
}
}
A similar request can be used to update the likes count in real-time, say for the voting form results.
GraphQL Concepts
Now that we know different query types, let’s figure out how to deal with elements that are used in GraphQL.
Concepts I am going to cover below:
- Fields
- Arguments
- Aliases
- Fragments
- Variables
- Directives
1. Fields
Look at a simple GraphQL query:
{
user {
name
}
}
In this request, you see 2 fields. The user field returns an object containing another field of type String. GraphQL server will return a user object with only the user’s name. So simple, so let’s move on.
2. Arguments
In the example below, an argument is passed to indicate which user to refer to:
{
user(id: "1") {
name
}
}
Here in particular we’re passing the user’s id, but we could also pass a name argument, assuming the API has a backend function to return such a response. We can also have a limit argument indicating how many subscribers we want to return in the response. The below query returns the name of the user with id=1 and their first 50 followers:
{
user(id: "1") {
name
followers(limit: 50)
}
}
3. Aliases
GraphQL uses aliases to rename fields within a query response. It might be useful to retrieve data from multiple fields having the same names so that you ensure these fields will have different names in the response to distinguish. Here’s an example of a GraphQL query using aliases:
query {
products {
name
description
}
users {
userName: name
userDescription: description
}
}
as well as the response to it:
{
"data": {
"products": [
{
"name": "Product A",
"description": "Description A"
},
{
"name": "Product B",
"description": "Description B"
}
],
"users": [
{
"userName": "User 1",
"userDescription": "User Description 1"
},
{
"userName": "User 2",
"userDescription": "User Description 2"
}
]
}
}
This way we can distinguish the name and description of the product from the name and description of the user in the response. It reminds me of the way we did this in SQL when joining two tables, to distinguish between the same names of two joined columns. This problem most often occurs with the id and name columns.
4. Fragments
The fragments are often used to break up complex application data requirements into smaller chunks, especially when you need to combine many UI components with different fragments into one initial data sample.
{
leftComparison: tweet(id: 1) {
...comparisonFields
}
rightComparison: tweet(id: 2) {
...comparisonFields
}
}
fragment comparisonFields on tweet {
userName
userHandle
date
body
repliesCount
likes
}
What’s going on with this request?
- We sent two requests to obtain information about two different tweets: a tweet with
idequal 1 and tweet withidequal 2. - For each request, we create aliases:
leftComparisonandrightComparison. - We use the fragment
comparisonFields, which contains a set of fields that we want to get for each tweet. Fragments allow us to avoid duplicating code and reuse the same set of fields in multiple places in the request (DRY principle).
It returns the following response:
{
"data": {
"leftComparison": {
userName: "foo",
userHandle: "@foo",
date: "2019-05-01",
body: "Life is good",
repliesCount: 10,
tweetsCount: 200,
likes: 500,
},
"rightComparison": {
userName: "boo",
userHandle: "@boo",
date: "2018-05-01",
body: "This blog is awesome",
repliesCount: 15,
tweetsCount: 500,
likes: 700
}
}
5. Variables
GraphQL variables are a way to dynamically pass a value into a query. The example below provides a user id statically to the request:
{
accholder: user(id: "1") {
fullname: name
}
}
Let’s now replace the static value by adding a variable. The above can be rewritten as:
query GetAccHolder($id: String) {
accholder: user(id: $id) {
fullname: name
}
}
{
"id": "1"
}
In this example, GetAccHolder is a named function that is useful when you have plenty of requests in your application.
Then we declared the variable $id of type String. Well, then it’s exactly the same as in the original request, instead of a fixed id, we provided the variable $id to the request. The actual values of the variables are passed in a separate block.
We can also specify a default value for a variable:
query GetAccHolder($id: String = "1") {
accholder: user(id: $id) {
fullname: name
}
}
Additionally, it is possible to define a variable mandatory by adding ! to data type:
query GetAccHolder($id: String!) {
accholder: user(id: $id) {
fullname: name
}
6. Directives
We can dynamically generate a query structure by using directives. They help us dynamically change the structure and form of our queries using variables. @include and @skip are two directives available in GraphQL.
Examples of directives:
@include(if: Boolean)– include the field if the value of the boolean variable =true@skip(if: Boolean)— skip field if boolean variable value =true
query GetFollowers($id: String) {
user(id: $id) {
fullname: name,
followers: @include(if: $getFollowers) {
name
userHandle
tweets
}
}
}
{
"id": "1",
"$getFollowers": false
}
Since $getFollowers equals true, the followers field will get skipped, i.e. excluded from the response.
GraphQL Schema
In order to work with GraphQL on the server, you need to deploy a GraphQL Schema, which describes the logic of the GraphQL API, types, and data structure. A schema consists of two interrelated objects: typeDefs and resolvers.
In order for the server to work with GraphQL types, they must be defined. The typeDef object defines a list of available types, its code looks as below:
const typeDefs= gql`
type User {
id: Int
fname: String
age: Int
likes: Int
posts: [Post]
}
type Post {
id: Int
user: User
body: String
}
type Query {
users(id: Int!): User!
posts(id: Int!): Post!
}
type Mutation {
incrementLike(fname: String!) : [User!]
}
type Subscription {
listenLikes : [User]
}
`;
The above code defines a type User, which specifies fname, age, likes as well as other data. Each field defines a data type: String or Int, an exclamation point next to it means that a field is required. GraphQL supports four data types:
StringIntFloatBoolean
The above example also defines all three types – Query, Mutation, and Subscription.
- The first type which contains
Query, is calledusers. It takes anidand returns an object with the user’s data, it is a required field. There is another Query type calledpostswhich is designed the same way asusers. - The
Mutationtype is calledincrementLike. It takes afnameparameter and returns a list of users. - The
Subscriptiontype is calledlistenLikes. It returns a list of users.
After defining the types, you need to implement their logic so that the server knows how to respond to requests from a client. We use Resolvers to address that. Resolver is a function that returns specific field data of the type defined in the schema. Resolvers can be asynchronous. You can use resolvers to retrieve data from a REST API, database, or any other source.
So, let’s define resolvers:
const resolvers= {
Query: {
users(root, args) {return users.filter(user=> user.id=== args.id)[0] },
posts(root, args) {return posts.filter(post=> post.id=== args.id)[0] }
},
User: {
posts: (user)=> {
return posts.filter(post=> post.userId=== user.id)
}
},
Post: {
user: (post)=> {
return users.filter(user=> user.id=== post.userId)[0]
}
},
Mutation: {
incrementLike(parent, args) {
users.map((user)=> {
if(user.fname=== args.fname) user.likes++return user
})
pubsub.publish('LIKES', {listenLikes: users});
return users
}
},
Subscription: {
listenLikes: {
subscribe: ()=> pubsub.asyncIterator(['LIKES'])
}
}
};
The above example features six functions:
- The
usersrequest returns a user object having the passedid. - The
postsrequest returns a post object having the passedid. - In the
postsUserfield, the resolver accepts the user’s data and returns a list of his posts. - In the
userPostsfield, the function accepts post data and returns the user who published the post. - The
incrementLikemutation changes theusersobject: it increases the number oflikesfor the user with the correspondingfname. After this,usersget published inpubsubwith the nameLIKES. listenLikessubscription listens toLIKESand responds whenpubsubis updated.
Two words about pubsub. This tool is a real-time information transfer system using WebSockets. pubsub is convenient to use, since everything related to WebSockets is placed in separate abstractions.
Why GraphQL is conceptually successful
- Flexibility. GraphQL does not impose restrictions on query types, which makes it useful for both typical CRUD operations (create, read, update, delete) and for queries having multiple data types.
- Schema definition. GraphQL automatically creates a schema for the API, and the hierarchical code organization with object relationships reduces the complexity.
- Query optimization. GraphQL allows clients to request the exact information they need. This reduces server response time and the volume of data to be transferred over the network.
- Context. GraphQL takes care of the requests and responses implementation so that developers can focus on business logic. Strong Typing helps prevent errors before executing a request.
- Extensibility. GraphQL allows extending the API schema and adding new data types along with reusing existing code and data sources to avoid code redundancy.
Thank you for sharing good information.